LiveTheSoundCardV8
中華のAliさんからLiveTheSoundCardV8なるものをおすすめされた。
なんと、お値段300円未満ってことだったのでポチってみました。
LiveTheSoundCardV8をGeminiに聞いてみると。
Live Sound Card V8を一言で言うなら、
「スマホ一台で配信を完結させるための、多機能オーディオミキサー」
です。

との事で。あんまりスマホは使わないんだけどなーと思いつつ。
調べてみました。
概略
マイクからの入力とBGMの入力を混合(ミキシング)して出力できます。
マイク音声にエコー、ボイスチェンジャー、リバーブなどの簡単なエフェクトが可能。
内蔵電子音で拍手、笑い声などが合成可能。
機能は以下のような感じです。
1.マイクとBGMをミキシングできます。
2.マイク音声はTREBLE、BASSの簡単な高音/低音イコライザ機能が使えます。
3.Record:出力の音の大きさの調整。
パソコンに接続すると、USBオーディオとして認識されます。これが出力になります。
パソコンへの出力(パソコン側から見ると入力)の音量をRecordツマミで調整できます。
EarphoneSpeakerとHeadsetではないので注意。
4.BackingTrack:AccompanyInstrumentからの入力されたBGMの音の大きさを調整します。
5.Monitor:EarphoneSpeakerとHeadsetの音の大きさを調整します。
6.MIC:CondenserMicとDynamicMicの音の大きさを調整します。
7.ECHO:CondenserMicとDynamicMicのエコーの大きさを調整します。
8.下にくっついている多数のファンクション
8-1.ReverbDelay
若干遅れて聞こえます。
「カラオケのような響きを作るのがリバーブ」で、
「やまびこのように音が遅れて聞こえるのがディレイ」
これを解除するにはMCボタンを押す。
8-2.VoiceChange
声が変になります。窒素を吸った声になったり、
それが野太くなったりします。
これを解除するのにMCボタンを押す。
8-3.Elimination
ノイズ除去してくれてると信じたい。
8.4.Crack
マイクの声を変にする機能。若干割れたような音になります。
8.5.MC
一般のオーディオ用語だと、VoiceOverと同じ意味ですが、
今回の検証ではVoiceChange、ReverbDelayの解除ボタンのようだ。
8.6.VoiceOver
司会者モード。マイクから音声入力が有る時だけ
自動的にBGM=AccompanyInstrumentの音量を下げる
9.12個のいろんな音
笑い声、カラス、マシンガン、ブーイング、拍手等12種音がなります。
背面の端子へ接続

LIVE1:アンドロイドスマホ用らしい。未検証。多分デジタルで接続すればスマホの
アプリから連動可能と思われます。
付属のminiB→3.5ミリ4端子オーティオ変換ケーブルで普通の
オーディオ信号を入力できます。
ただし、この端子のためのツマミは無いので、入力する機器側で
音の大きさは調整する。
LIVE2:アイホン用らしい。未検証。多分デジタルで接続すればスマホのアプリから
連動可能と思われます。
付属のminiB→3.5ミリ4端子オーティオ変換ケーブルで普通のオーディオ信号を
入力できます。
ただし、この端子のためのツマミは無いので、入力する機器側で
音の大きさは調整する。
AccompanyInstrument:付属のminiB→3.5ミリ4端子オーティオ変換ケーブルで、
普通のオーディオアナログを入力できます。
この端子への入力の大きさはBackingTrackで調整可能です。
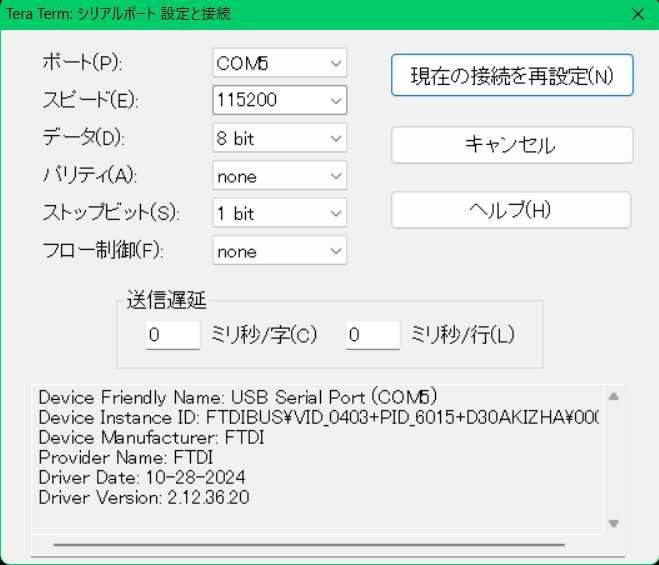
Charging:充電 と パソコン接続 付属のminiB→Aケーブルでパソコンに接続しました。
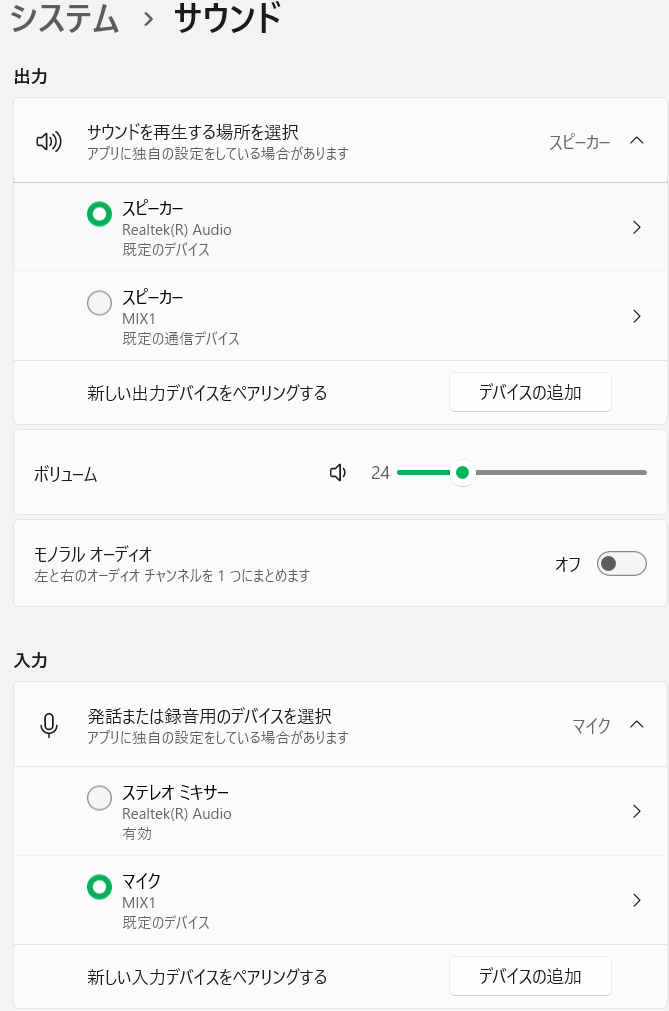
Windows11で試すと、マイクとスピーカーとしてMIX1という名前で認識します。
配信として使用する場合はOBS Studio等で入力インターフェースとしてMIX1を選ぶ。
EarphoneSpeaker:普通のヘッドホンを接続できます。
Headset:未検証。ネット情報によると4端子のスピーカー付きヘッドセットに接続して、
モニターとマイクの役割を果たします。
CondenserMic:コンデンサーマイクからの音の入力。
DynamicMic:未検証 普通にマイクです。
Windows接続した時の画面
以下全体的に気になった所。
ぱっと判らない。インターフェース名とか、LINE1とか言われても何のことだかわからない。
デジタル接続 または Audio入力1とか判りやすくしないと。その他、ツマミの名前と
入力端子の名前が合っていないせいで大混乱になる。
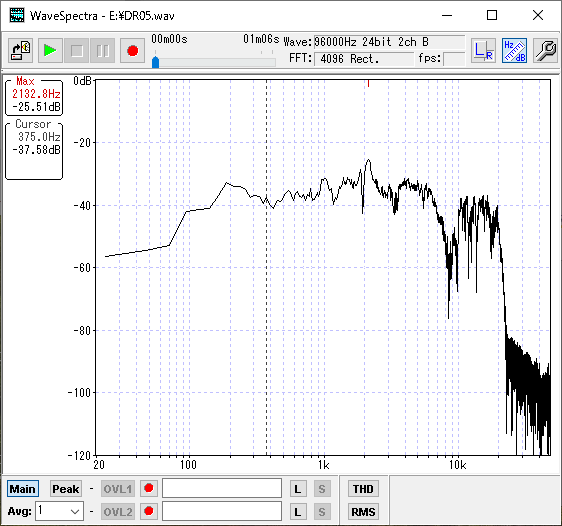
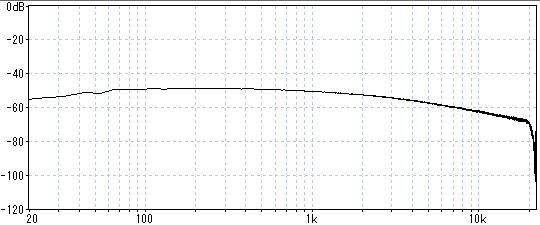
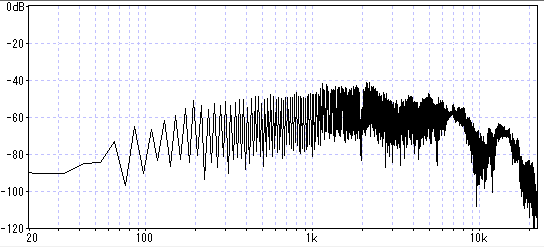
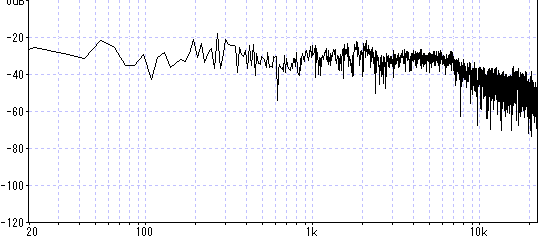
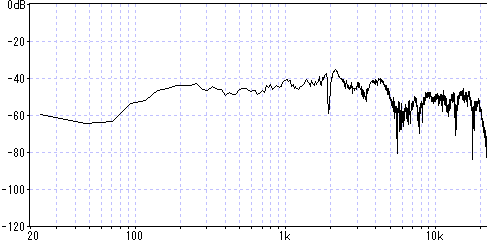
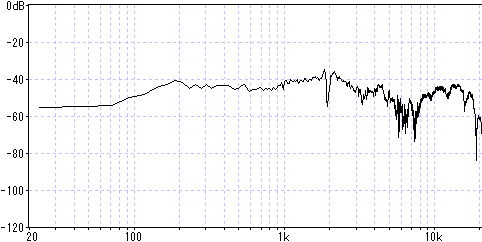
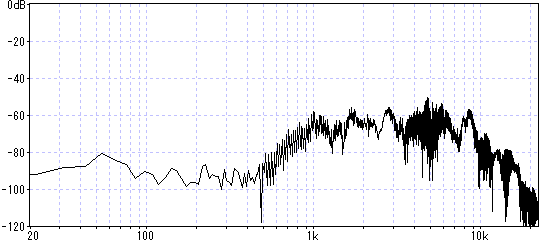
ヘッドホンだけ繋いで無音で聞くと判るが、この機器自体からノイズが発生している。
電池も内蔵しているのでACアダプタ無しの単体でも聞こえる。自分は結構気になるレベル。
これが有る限り配信は無理ですね。とてもHiFiとは呼べない音質です。
12個のいろんな音はほぼ使えないですね。買う前に調べれば良かったですが、
個人的にはクイズの正解音ピンポーンとブブーぐらいが入ってれば最低限使えるかも
と思ってましたが、それもなし、
拍手と笑い声ぐらいかなー
謎のキッス音とかはいらないなー(笑)
惜しいんだよね。ソフトでクラウドに接続して選んで入れ替えるとか、
スマホから選んで自分の好きなのが入れられるとか出来るのが今の普通なので。
もしかしたら、スマホ連携すると出来る?
学級会でDJして遊ぶには楽しめます。
だから、クイズの正解音と不正解音は欲しかった。
放送部とかでも結構楽しめそう。取り上げられちゃったりとかするかな?
300円以下のおもちゃとしては上出来です。
バッテリ内蔵で短時間の運用なら外でも使えるし、
上記の通り多機能でコレとスマホでもDJ楽しめちゃいます。
ECHO機能でカラオケみたいにもなりますので、
これからのお花見で活用する人現れたり現れなかったり。楽しみですね。
お花見会場でカラオケは迷惑だからやめてね。
活用方法が多すぎてヤバイ。