というわけで、今回からしばらく物理の時間っす。
ちなみに物理学は英語で
Physics
と書いてフィジックスと呼ぶのだよ。いまだに綴りを間違っちゃう。
私達もついに、現実世界の画面と3D仮想体をシンクロさせるだけじゃなく、仮想体に現実世界の物理運動を再現させるという、ARの新たな領域に踏み込むわけだが…
いったいどうしろと?
こういう時は、developer.apple.comを、キーワード「physics」あたりで検索すればよくってよ。
注意)ここら辺のノウハウは「リブートキャンプ by Swift 目次」の「12、または私は如何にして心配するのを止めて…」で説明してるんで、わからん人はそっち読むように
https://developer.apple.com/search/?q=physics&type=Videos
検索結果いっぱい出ます。

このうち、VideosタブてっぺんのInside SwiftShot: Creating an AR Gameなんかは、WWDC 2018で公開されたAR対戦ゲームで使われてる技術の説明で、ソースまで提供されとります。
複数のiPhone実機間での実空間の共有や、そのための実機間通信、シェーダを使った旗を揺らす方法、そういった手法のとっかかりを紹介してます。
具体的な手法を知るためには提供されてるプロジェクトを読み込まないとダメなんだけど、やれば、かなりの情報が手に入りそう。
これまでの話を読んでる人なら、このサンプル使って自力でなんとかできるかもしれんけど、敷居は高めです。
私は、とりあえずは、地道に進んでみようかと思ってます。
なら、どっから手をつけるか?なんですが、同じ検索結果の下の方にあるWWDC 2014のビデオ
あたりを軽く見て、Phisycsで何ができるのか把握しておいて、検索結果のGuidesタブ側にある検索結果確認ですな。
https://developer.apple.com/search/?q=physics&type=Guides
なんだけど、ヒットするのほとんどSpriteKitの方で、上のビデオで紹介されてるSceneKit側のSCNPhysicsBodyが出ねーんすよ。「SceneKit physics」で検索してもあんま変わらない。
注意)SpriteKitはSceneKitの2D版です。SceneKitより先にこっちが用意された。2DならUIViewとかUIImageViewとかあるじゃんと思うかもしれないけど、UIKit系はボタンやナビゲーションバーや画面遷移といったGUIパーツの構築しやすさを優先してて、ゲームといったグラフィック性能バリバリ使います系にはスピード面でやや劣るんですな。そのため、ゲーム作る人は、UIKitより操作がめんどくさい(でも高速な)OpenGLなんかを使わないとダメだったんですが、その点を改善すべくUIKit風に使い勝手がよくて、OpenGL並みに描画性能が高いKitとしてSpriteKitが登場しますた
仕方ないんで、とりあえず実際に、上のビデオの18分12秒あたりで紹介されてるように、SCNNodeのphysicsBodyプロパティにSCNPhysicsBodyのdynamicBodyで作ったオブジェクトを割り当ててみようかと。
SCNPhysicsBody
ビデオによると、SCNNodeは、こいつを割り当てられると物理学に従った挙動をするわけっす。
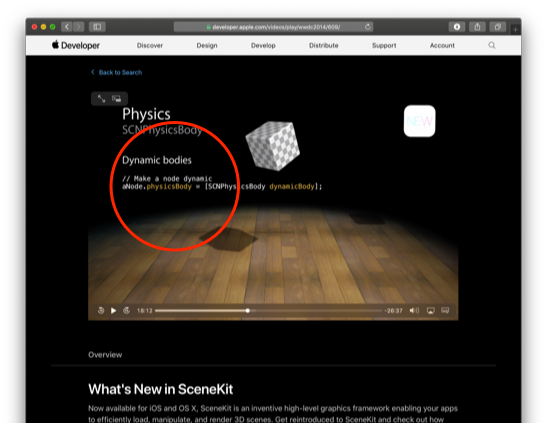
これね
これを実際に試す。
ベースにするのはXcodeのARテンプレね。

こいつは「こんにちはAR」、「ARKitだ!」でやった「Single View App」テンプレからのARセットアップまでをテンプレ側で終わらせてくれてるすぐれもの。
おまけに「見た目が大事」で紹介したSceneファイルからのSCNScene構築までやっちゃってるので、Runさせるだけで、そのまんま空間に宇宙船が浮いたりもするわけですよ。
注意)ちなみにSCNScene構築のために読み込んでるファイルは、COLLADAじゃなくSceneKitのネイティブファイルであるSceneファイル(拡張子.scn)ね
プロジェクト作成手順自体は「Argmented Reality App」を選ぶ以外は「Single View App」と同じっす。

てなわけだ
で、こいつはSCNSceneのrootNodeに"ship"て名前のSCNNodeが追加されてるんで、childNode(withName:,recursively:)で取り出せます。
ここらへんの情報は、提供されてるSceneファイルをScene Editorで見ればわかります。

で、取り出したSCNNodeオブジェクト"ship"の、physicsBodyプロパティに
SCNPhysicsBody.dynamic()
で作ったオブジェクトを割り当ててみる。
ViewController.swift
class ViewController: UIViewController, ARSCNViewDelegate { @IBOutlet var sceneView: ARSCNView! override func viewDidLoad() { ・・・ // Create a new scene let scene = SCNScene(named: "art.scnassets/ship.scn")! phygicsLab(scene:scene) ・・・ } ・・・ func phygicsLab(scene:SCNScene) { if let ship = scene.rootNode.childNode( withName: "ship", recursively: true) { ship.physicsBody = SCNPhysicsBody.dynamic() } } }
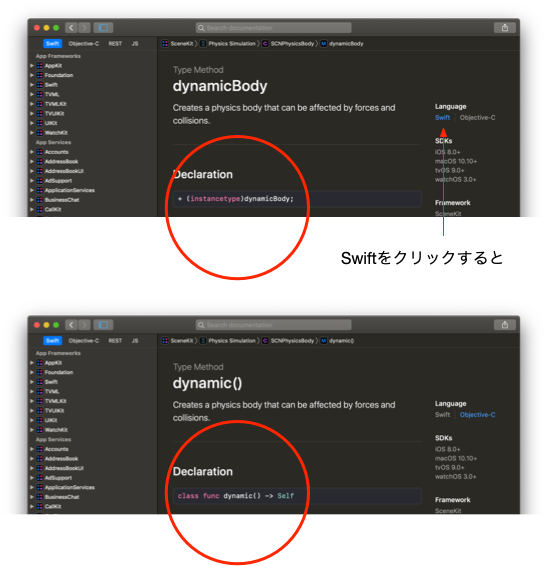
ビデオではObjective-C言語で
[SCNPhysicsBody dynamicBody];
と説明されてるんだけど、swift言語なんで、そのまま記述できんわけなんやね。なので
[SCNPhysicsBody dynamicBody];
は
SCNPhysicsBody.dynamic()
となる。
ここらへん、Objective-Cとswiftの対応はXcodeのHelp>Developer Documentationメニューで出てくる画面で調べられます。
で、早速Run。
なんか宇宙船落ちたし(笑。
一瞬すぎてわからんけど、目の前通り過ぎたような…
SCNPhysicsBody.dynamic()を割り当てたんで、重力が効いてしまって自由落下しちゃうんですな。
底がないんで、地球の中心に向かって落下してる模様。
チューわけで底を用意します。
あと、床に跳ね返る様子を見やすいように、ship.position.zに-3を指定して、宇宙船を3m後ろに移動させとく。でもって、床の高さも、position.yに-1を設定して1m下にしてます。positionわからん人は「仮想体を置いてみる」ね。
ViewController.swift
func phygicsLab(scene:SCNScene) { if let ship = scene.rootNode.childNode( withName: "ship", recursively: true) { ship.physicsBody = SCNPhysicsBody.dynamic() ship.position.z = -3 // 3m後ろに移動させとく } // 床を追加 静的な物理物体として設定 let floorNode = SCNNode(geometry: SCNFloor()) floorNode.physicsBody = SCNPhysicsBody.static() floorNode.position.y = -1 scene.rootNode.addChildNode(floorNode) }
SCNFloorてのは組み込み形状で無限xz平面です。Appleのサンプル色々見てて見つけますた。

で、こいつのphysicsBodyプロパティには、ビデオで紹介されてたように、重力や外から加えられた物理的な力に影響されない静的な物理体(PhysicsBodyを直訳してみた)となるSCNPhysicsBodyを割り付ける。静的な物理体を作る場合は
SCNPhysicsBody.static()
を使う。
これで今回作る床は、空間に固定されたSCNPhysicsBody付きSCNNodeになるわけです。
空間に固定って、physicsBodyプロパティにSCNPhysicsBodyを割り付けられてないSCNNodeと一緒じゃんと思うかもしれないけど、SCNPhysicsBody.static()を割り当てた場合、SCNPhysicsBody同士が衝突した場合、お互いに弾きあうという性質が利用できるんですよ。
SCNPhysicsBodyが設定されてないSCNNodeとは、衝突してもそのまますり抜けちゃうんで、宇宙船の落下を止めるには固定されたSCNPhysicsBodyを設定したSCNNodeが必要なんですな。
これで落下した宇宙船は、固定された床にぶつかって止まる。
Runさせると、無事床に着地しました。

ま、ぶっちゃけ、突き刺さったわけだが
おもろいやんけ〜、ということで、画面タップしたら宇宙船に力を加えてみることにしました。
ViewController.swift
func phygicsLab(scene:SCNScene) { ・・・ scene.rootNode.addChildNode(floorNode) // 画面タップを見張る self.view.addGestureRecognizer(UITapGestureRecognizer( target: self, action: #selector(didTap))) } /// 画面タップされたら、宇宙船に力加える @objc func didTap() { if let ship = sceneView.scene.rootNode.childNode( withName: "ship", recursively: true) { ship.physicsBody?.applyForce( SCNVector3(x:0, y:8, z:0), asImpulse: true) } }
Runすると、画面タップするたびに宇宙船が飛び跳ねるようになります。
サンプル:
http://tetera.jp/xcc/book-sample/ARPhysics.zip
空中で浮いてる時にタップすれば、そこからまたジャンプだ。
無限の宇宙へ!
ここで使ってるapplyForceってメッセージは、SCNPhysicsBodyオブジェクトに対して力を加えるって指定です。Developer DocumentationのSCNPhysics
衝撃指定の場合の第1引数のSCNVector3は力積値を意味するらしい。
力積て何?
という話は長くなるんで次回。