新Facebookページの写真サイズ一覧
FacebookをSEO対策の一環として利用することは、いまやめずらしいことではないでしょう。そんなFacebookページが2012年3月30日に従来までのウェルカムページが廃止され、タイムライン型に変更になることはみなさんご存知のことでしょう。
Facebookページで一番変わるところといえば、Facebookページの写真のサイズです。タイムライン型以降までもう少ししかありません。写真のサイズをしっかりと確認し、新しいFacebookページの移行に対応していきましょう!
以下がFacebookページ写真の一覧です。
1.カバー写真 851px × 315px
Facebookページの一番上に表示される写真です。最も目立つ場所に表示されるため、Facebookページ全体の印象を決める写真です。
2.プロフィール写真 180px × 180px
Facebookページとして投稿やコメントをするときに表示される写真です。写真をアップする際のサイズは180px ×180pxですが、実際には125px × 125pxで表示されるのでご注意ください。
3.アプリイメージ写真 111px × 74px
新Facebookページでの新しい機能です。以前はアプリ名しか変えられませんでしたが、今回より写真も変更できるようになりました。
アプリの設定編集から「カスタムタブの画像 」をクリックすると写真をアップすることが可能です。
4.投稿写真(通常) 404px × 404px
写真を投稿すると通常はこのサイズでアップされます。
このサイズより小さい写真をアップすると、写真が目立たなくなりますので、できるだけ大きなサイズの写真をアップするようにしましょう。
5.投稿写真(ハイライト) 843px × 403px
投稿した写真を「ハイライト」にするとこのサイズで表示されます。
アップした写真の右上から星マークをクリックすると「ハイライト」として、大きいサイズで表示されます。
応援クリックにご協力ください!
↓↓↓↓↓
検索結果にプレイスページ情報表示
最近になって検索KWによっては、検索結果画面にプレイスページ情報が大きく占有しているということが多くなってきました。場合によっては1位以外の順位のサイトはファーストビューすら収まっていないといったことも見受けられました。
今回はそんなプレイスページ情報が検索結果画面に表示されるようになった件について解説している記事がありましたのでご紹介したいと思います。
GoogleとYahoo! JAPAN が2012年1月より共に、ウェブ検索(オーガニック検索)内にGoogleプレイス情報を大幅に増やしています。以下、それぞれの検索結果の変化の状況について説明します。
Googleの場合 - プレイス情報の表示対象キーワードが増加
Googleは他種類の検索結果を複合的に表示するユニバーサル検索を推し進めていることもあり、特に地域系クエリ(都道府県及び市区町村などの語句との掛け合わせ検索キーワード[例 ラーメン 那覇、チョコ 函館]、またはキーワード自体が地域属性を持つもの[例 漫画喫茶、コンビニ]等)で検索時にプレイス 情報が検索結果に表示されるケースは多い。最近は、その対象キーワードが拡大した模様です。ただし、明らかにプレイス(=地域情報)とは関連性が低いキーワードも確認されており、今後調整される可能性があります。
Yahoo!JAPAN の場合 - プレイス情報のURLがmaps.google 以外のサイトを表示
2010年12月よりGoogleの検索バックエンドを採用するYahoo!検索 であるが、基本的にウェブ検索(=ウェブページを対象とした検索)をベースとしており、その他の検索結果は同社の他プロパティからの情報などを組み合わせて 表示してきました。2012年1月下旬よりオーガニック検索内にGoogleプレイス情報も含まれるようになっています。確認方法は、検索結果の表示形式がタイトルのみ(スニペットなし)で連続して3~7個程度表示されているものが該当します。
ただし同じキーワードでGoogleとYahoo!検索の検索結果を比較すると、プレイス情報は必ずしも同一セットを表示するわけではありません。これは、Yahoo!検索の検索結果では、特定の条件に該当するプレイス情報は非表示となるためです。
その特定条件とは、Google検索結果に表示されるプレイス情報のリンク先が、maps.google.~ となっている場合です。
Googleで表示されたビジネス情報のリンク先が maps.google - のものはYahoo!検索の検索結果には表示されません。つまり、Yahoo!検索の検索結果上に表示されるプレイス情報は、Googleのそれから maps.google - ドメインのサイトを差し引いたものとなります。
たとえば、Googleで「トルコ料理 品川」と検索すると、現時点(2012/02/22 00:22)でオーガニック検索の4件目よりGoogleプレイス結果が7件差し込まれることが確認できます。このうち、上から2件目のレストランは maps.google.co.jp となっているため、同検索クエリでYahoo!検索で検索しても同レストランは表示されていません(1件差し引かれるため、Yahoo!検索結果のプレイス表示件数は6件となっている)。
一方、たとえば「メイド喫茶 秋葉原」のように、プレイス情報として表示される全てのサイトのドメインが maps.google に該当しない場合は、Yahoo!検索でも同様の情報が表示されます。
以上、現状どのようにプレイス情報が表示されているか、説明されていますが、具体的な解決策については触れられていません。今後どのように対策をしていくべきなのか注目されるかもしれません。
記事元はこちら
↓↓↓
GoogleとYahoo! JAPAN、オーガニック検索でプレイス情報表示を拡大 ::SEM R (#SEMR)
応援クリックにご協力ください!
↓↓↓↓↓
正しいURL正規化について
重複コンテンツ対策として、URL正規化タグを使って正規化を行ったことがあるかとは思いますが、その正規化は本当に正しい正規化なんでしょうか。今回はそんな正規化について議論してある記事がありましたのでご紹介したいと思います。
301リダイレクトを使うにせよURL正規化タグを使うにせよ、本当に正しい正規URLはどれかを判断するにはどうすればいいのだろうか?
しばしば見られる間違いとしては、「多くのページから不適切なURLに正規化してしまう」というものがあります。たとえば次のようなものです。

本来ならば「product.php?id=1234」のような製品個別のページに正規化しなければいけないのに、間違って「product.php」という単なるテンプレートページに正規化してしまっている例です。
これでは、たった1つの(おそらくは製品を表示さえしていない)ページがすべての製品を代表してしまうことになります。
正規のページは、最もシンプルな形のURLだとは限りません。他とは違うコンテンツを生成する最もシンプルな形のURLです。たとえば、下の3つのURLが同じ製品ページを生成するとしましょう。

3つのうちの2つは本質的に重複ページであり、「print」や「session」というパラメータは、正規ページとすべきメインの製品ページのバリエーションを表しています。ただし、「id」パラメータは、そのコンテンツにとって不可欠なものです。どの製品が実際に表示されるかは、このパラメータが決めるからです。
重複コンテンツの乱造と同じくらい、適切でないURL正規化がさらなるダメージを招くケースもあります。慎重に計画を練り、正しい正規URLを選んでいることを入念に確認した上で、正規化を進めましょう。
重複コンテンツがどういうものかを理解したところで、自分のサイトに重複があるかどうかを調べるにはどうしたらいいでしょうか? 以下のツールを見てみましょう。
- Googleウェブマスターツール
- グーグル検索の「site:」コマンド
Googleウェブマスターツール
Googleウェブマスターツール(GWT)では、ロボットがクロールしたtitle要素とmeta descriptionタグの重複リストを取り出せます。できることはこれだけですが、出発点としてはなかなかといえます。
URLをベースとした重複の多くは、メタデータが同じになっている。GWTのアカウントから[診断]>[HTMLの候補]を選ぶと、下のような表が出てくるはずです。
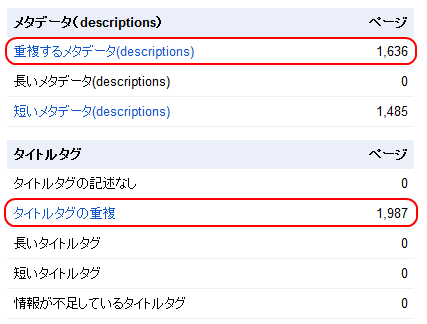
「重複するメタデータ」や「タイトルタグの重複」をクリックすると、重複のリストを取り出せます。これは問題のある箇所を見つけ出すのに素晴らしい足がかりとなるでしょう。
グーグル検索の「site:」コマンド
どこに問題があるかがすでに分かっていて、もっと突っ込んだ対策を講じる必要がある時は、グーグルの「site:」コマンドが非常に強力かつ柔軟なツールになります。「site:」コマンドが強力なツールになる理由は、他の検索演算子と組み合わせて使用できる点にあります。
たとえば、トップページの重複が気になっているとしましょう。グーグルがトップページの重複ページをインデックス化しているかどうかを調べるためには、下の例のように「site:」と「intitle:」を一緒に使うといいでしょう。
ひとまとまりのフレーズとして検索するためにタイトルを半角の二重引用符で囲んで指定します。重複コンテンツを全部はき出させるには、必ず(wwwを除いた)ドメイン名をsite:に指定しましょう。これでwww付きバージョンとwwwなしバージョンの両方が見つかるでしょう。
もう1つの強力な演算子の組み合わせは「site:」と「inurl:」です。「inurl:」は指定したキーワードがページのコンテンツではなく URLの文字列に含まれるものを探す検索オプションです。これをうまく使うと、先述した検索結果のソートから生じる問題などでパラメータを見つけ出せるでしょう。
「inurl:」という演算子は、使われたプロトコルを検知することもできる。セキュア通信のページ(https:)がインデックス化されているかどうかを調べるのに便利です。
また、「site:」と通常の検索キーワードを組み合わせて、不完全重複(繰り返し使われているコンテンツの塊など)を見つけることもできます。サイト全体でコンテンツの塊を探すには、探したい部分を引用符でくくったものを追加するだけでかまいません。
オリジナルなコンテンツの塊を引用符で囲んで検索するやり方は、自分のサイトが盗用されていないかどうかを調べる安上がりで手軽な方法だということも言い添えておくべきでしょう。「site:」演算子を外して、長文の、あるいはオリジナルなコンテンツの塊を引用符でくくって検索してみるといいでしょう。
記事元はこちら
↓↓↓
URL正規化のポイントと重複を診断する4つのツール- 重複コンテンツ対策完全ガイド #4 | Web担当者Forum
応援クリックにご協力ください!
↓↓↓↓↓
![]()
重複コンテンツ対策
Googleは定期的にパンダアップデートを行い、重複コンテンツのある質の低いサイトに対しペナルティを課すようになってきています。今回は重複コンテンツ問題を解決する手段を紹介している記事がありましたので、ご紹介します。
IV 重複問題の解決に役立つ方法
説明の順番が適当でない感じがするかもしれないが、具体例の解説に進む前に、重複コンテンツに対処する方法をいくつか紹介しておきたい。そうしておけば、各事例を修正するための適切なお薦めツールを、混乱を招くことなく紹介できるだろうから。
ここで紹介するのは、次の12種類の方法だ。
- 重複ページを削除する
- 301リダイレクト
- robots.txt
- meta robotsタグ
- URL正規化タグ(rel="canonical")
- URLの削除(グーグル)
- パラメータによるブロック(グーグル)
- URLの削除(Bing)
- パラメータによるブロック(Bing)
- 「rel="next"」と「rel="prev"」
- link rel="syndication-source"
- サイト内リンクの構造
- 何もしない
それぞれについて詳しく解説していこう。
IV-1 重複ページを削除する
最も簡単な重複コンテンツ対処法はもちろん、該当するページを削除して404エラーを返すことだ。
そのコンテンツが本当に訪問者や検索エンジンにとって何の価値もないものなら、また重要な被リンクやトラフィックもないなら、すっきり削除してしまうのが完璧に有効な方法だ。
IV-2 301リダイレクト
ページを削除するもう1つの方法は、301リダイレクト を使うやり方だ。
404エラーと違って、301リダイレクトは訪問者に(人間でも検索ロボットでも)、該当ページが別の場所に恒久的に移動されたことを伝える。訪問者が人間の場合、ブラウザは自動的にリダイレクト先のページを表示してくれる。SEOの観点から見ると、被リンクが持つ信頼度の大部分は新しいページにも渡される。
重複コンテンツの正規URLがはっきりしていて、そのコンテンツがトラフィックや被リンクを獲得しているなら、301リダイレクトは有効な選択肢になり得る。
IV-3 robots.txt
もう1つの選択肢は、人間の訪問者には重複コンテンツが見えるようにしておくが、検索エンジンのクローラーは締め出してしまうというものだ。
これを実現する方法として最も古く、おそらく最も簡単なのがrobots.txtファイル (普通はルートディレクトリに置かれる)を使うやり方だ。たとえばこんな感じになる。

robots.txtが持つ長所の1つは、フォルダ全体、場合によってはパラメータ付きのURLさえ比較的容易にブロックできることだ。
短所は、ちょっと強力過ぎて、時には信頼性に欠けるソリューションだという点だ。robots.txtはクローラーがまだアクセスしていないコンテンツをブロックするのには効果的だが、すでにインデックス化されているコンテンツを削除する方法としては有効ではない。
主要な検索エンジンもrobots.txtの多用を嫌っているようで、一般に重複コンテンツ対策としてはrobots.txtを推奨していない。
IV-4 meta robotsタグ
HTMLの<head>要素内でmeta robotsタグ (またはmeta noindex)を使って、ページ単位で検索ロボットの行動を制御することもできる。最も簡単な指定は次のようになる。

このディレクティブは検索ロボットに対して、あるページをインデックス化しないように、あるいはそこにあるリンクをたどらないようにと指示する。ついでに、僕はこちらの方がrobots.txtよりも若干SEOと親和性が高いと思うし、プログラムで動的に生成できるので、より柔軟な使い方ができることも多い。
meta robotsタグのcontent属性値として、上の例で挙げた「noindex, nofollow」以外によく使われるのが「noindex, follow」だ。こうしておくと、そのページはインデックスに追加されないが、ページ上にあるリンクは検索ロボットにたどってもらうことができる。サイト内検索の結果表示のようなページではこれが役に立つ。検索のしかたによって何通りも生成されるURLのうち、ある形式のものはブロックすべき(これについては後で説明しよう)だが、それでも製品ページへのリンクはたどってもらわなければ困るだろう。
ここで一言。「index, follow」というmeta robotsタグをページに追加する必要はまったくない。すべてのページは、(他の方法でブロックされていなければ)何もしなくてもインデックス化され、リンクもたどってもらえるので、そうするように指示するのは無駄なのだ。
IV-5 URL正規化タグ(rel="canonical")
2009年、検索エンジン各社が手を組んで、rel="canonical"というURL正規化タグ を作り出した。単に「rel="canonical"」とか「カノニカルタグ」と呼ばれることもあるこのディレクティブを使うことで、ウェブマスターはすべてのページについて正規バージョンのURLを指定できるようになった。
このタグは(meta robotsタグと同様に)HTMLページの<head>要素内に置かれる。簡単な例を次に示そう。

検索ロボットがカノニカルタグのあるページにやってくると、そこへたどりつくのに使ったURLが何であれ、正規のURLをそのページのURLとみなす。だから、たとえば検索ロボットが上に挙げた例のようなカノニカルタグが書かれているページにたどりついたURLが「www.example.com/index.html」だったとしても、そのページのURLは正規化指定されているURLと比べると「index.html」が付いている非正規URLなのでので、検索エンジンは余計な非正規URLをインデックス化しない。流れ込んでくるリンクジュースも、通常はカノニカルタグを通じて引き渡されているようだ。
ここで指摘すべき重要な点は、ウェブサイトのあらゆるテンプレートに対して、どれが正しい正規ページなのかを明確に把握しておく必要があるということだ。サイト全体を1つのページで正規化したり、間違ったページで正規化したりすると、悲惨な結果 を招く可能性がある。
V-6 URLの削除(グーグル)
Googleウェブマスターツール (GWT)から、個々のページ(またはディレクトリ)をインデックスから手作業で削除するようリクエストを送信できる。[サイト設定]>[クローラのアクセス]を選ぶと3つのタブが並んでいるので、3つ目の[URLの削除]タブをクリックすると次のようになる。
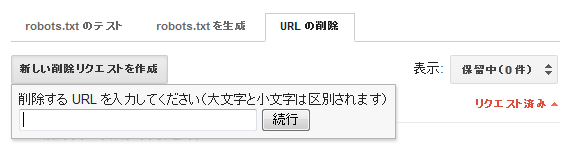
このツールはふつう、重複コンテンツの対処策としては最後の手段に用いられるものだ。というのも、削除できるのが1度に1つのURLまたはパスであり、また、決定権が完全にグーグルにあるからだ。とはいえ、ここでは選択肢をすべて取り上げておきたい。
技術的な注意点としては、URLの削除をリクエストする前に 、そのコンテンツにアクセスすると404エラーが返ってくることを確認するか、robots.txtによるブロック、またはnoindexのメタタグを実施しておくといい。そうしていなくても URLの削除をリクエストできるが、再度そのURLでクロールしてページにアクセスできた場合、削除は90日間しか続かない。
GWTを使った削除は基本的に、他の方法でグーグル側がどうにも動いてくれない場合の最終防衛策だ。
IV-7 パラメータによるブロック(グーグル)
ウェブマスターツールでは、グーグルに無視してほしいURLパラメータを指定することもできる(グーグルは基本的にこのパラメータを用いてページのインデックス化をブロックする)。
ウェブマスターツールで[サイト設定]>[URLパラメータ]を選ぶと、次のようなリストが表示される。
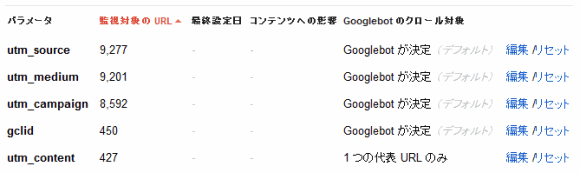
リストには、すでにグーグルが検出したURLパラメータと、各パラメータがどうクロールされるべきかを決める設定が並んでいる。「Googlebotが決定」という設定は、robots.txtやrobotsのメタタグといったほかのブロック方法を反映しているものではない点に留意してほしい。「編集」をクリックすると、以下のような選択肢が表示される。
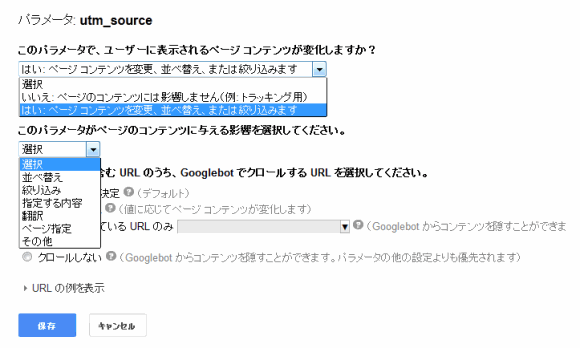
最近グーグルが変更を行ったために、新バージョンは少しわかりにくくなっている気がするが、基本的に「はい」はそのパラメータが重要でインデックス化されるべきものであること、「いいえ」はそのパラメータが重複を示していることを意味する。
このツールは効果がありそうに思える(また手っ取り早い手段にもなり得る)だろうが、優先策としてはやはり推奨できない。グーグル以外の検索エンジンには効果がないし、SEOツールやモニタリングソフトでは検出できない。それに、グーグルによる変更がいつあってもおかしくない。
IV-8 URLの削除(Bing)
Bing Webmaster Center (BWC)には、Googleウェブマスターツールととてもよく似たツールがある。実際には、Bingのパラメータブロックツールのほうがグーグルのツールより先に登場したと思う。
BingにURLの削除をリクエストするには、ウェブマスターセンターの[インデックス]>[URLのブロック]タブで[URLおよびキャッシュのブロック]を選ぶ。次のように表示されるはずだ。

実のところ、BWCの方が選択肢が幅広く、ディレクトリやサイト全体をブロックするよう指示できる。もちろん、最後の選択肢は普通は選ばないものだ。
IV-9 パラメータによるブロック(Bing)
BWCの[インデックス]タブには[URL正規化]という項目がある。この名称からは、Bingが正規化の処理をしてくれるような気がするが、選択肢は[有効にする][無効にする]しかない。
グーグルのツールと同じように、自動的に検出されているパラメータの一覧が表示され、そこでパラメータの追加や修正を行える。
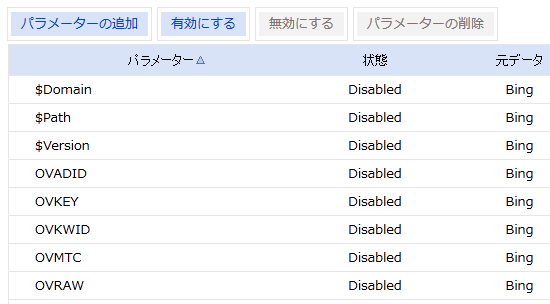
グーグルのGWTと同じく、Bingのツールも最後の手段だと思う。総じて、僕がこれらのツールを使うとすれば、他の方法でうまく行かず、悩みの種となっている検索エンジンが1つだけという場合だけだ。
IV-10 「rel="next"」と「rel="prev"」
グーグルは2011年9月、不完全重複の一形式であるページネーション(ページ分割)された検索結果に対処するための新ツールを公開した。この問題については次のセクションでもっと詳しく説明するが、簡単に言うとページネーションされた検索結果とは、検索結果が複数の塊に分散され、それぞれの塊(たとえば10個の結果)が独自のページ/URLを持つ状況を指す。
「rel="canonical"」によく似た2つの属性を使うことで、ページネーションされたコンテンツ間のつながりをグーグルに伝えることができるようになった。「rel="next"」と「rel="prev"」 だ。実装は少し厄介だが、ここでは単純な例を挙げる。

これは検索ボットが検索結果の3ページ目にやってきている場合の例だと考えてほしい。この例では、
- 2ページ目(つまり前のページ)を指す「rel="prev"」属性のタグ
- 4ページ目(つまり次のページ)を指す「rel="next"」属性のタグ
という2つのタグが必要になる。実装が厄介なのは、検索結果はおそらく1つのテンプレートから作られるので、たいていの場合、これらのタグを動的に生成する必要が生じるという部分だ。
当初使ってみたところ、これらのタグはちゃんと機能しているようだが、Bingは対応を表明しておらず、有効性に関して集まっているデータも十分ではない。ページネーションされたコンテンツについては、他の対処方法を次のセクションで簡単に取り上げる。
IV-11 link rel="syndication-source"
グーグルは2010年11月、コンテンツを配信するパブリッシャ向けに2つのタグを導入した 。
メタタグによるシンジケーション・ソース(syndication-source)という指示を使うと、転載された記事の配信元を以下のように示せる。

グーグル自身による説明でも、このタグとドメイン名間の「rel="canonical"」をどう使い分けるのかが少し不明瞭だ。また、グーグルは「実験的なもの」としてこのタグを公開したが、それが正式な仕様になったというグーグルの公式な発表はされていないと思う。
さらに、グーグルが最近link rel="standout"というタグ を追加したことで、混乱はさらに深まっている。独自のニュース記事を掲載する際に使うものだとされているが、これとsyndication-sourceとの相互作用がよく分からない。
注目には値するが、当てにしてはいけない。
IV-12 サイト内リンクの構造
留意すべき重要な原則がある。重複コンテンツ問題に対処する最良の策は、そもそも初めから重複コンテンツを作らないことだ。もちろん、いつでもそれが可能なわけではないが、対処すべき問題が大量にある場合、サイト内リンクの構造やサイトの構成を再検討してみる必要があるかもしれない。
301リダイレクトやURL正規化タグで重複の問題を修正したら、サイトの他の部分にもその変更を反映させることが大切だ。僕はこれまで、301や正規化タグでページの1つのバージョンを設定したのにサイト内のリンクが非正規のバーションに張られたままだったり、XMLサイトマップに非正規のURL が大量に含まれたりしている例を、驚くほどたくさん見てきた。サイト内リンクは強力なシグナルなので、混乱したシグナルを検索エンジンに送ることは問題を招くだけだろう。
IV-13 何もしない
最後になったが、検索エンジンに解決を任せるという方法もある。実際、グーグルは長年にわたってこのやり方を推奨している。だが、僕の経験から言うと、残念ながら良い結果になることはほとんどない。規模の大きなサイトだとなおさらだ。
とはいえ、重複コンテンツが必ずしも大きな問題を引き起こすとは限らないことと、グーグルが大きな影響を及ぼすことなく一部の重複コンテンツをフィルタリングできる例も確かにあることは、指摘しておくべき重要な点だろう。
単発的な重複コンテンツが少しだけあるという場合、そのままにしておくというのは十分に有効な選択肢になる。
記事元はこちら
↓↓
重複コンテンツ問題を解決する12の手段 - 重複コンテンツ対策完全ガイド #2 (p.2) | Web担当者Forum
応援クリックにご協力ください!
↓↓↓↓↓
Google、代わりのTitleを表示
TitleタグがSEOにとって非常に重要であることは、このブログをご覧になられている方は、ご存知の方も多いのではないでしょうか。
ただ、このTitleですが、どんなKWに対しても常に同じTitleの内容を表示してしまうと、検索KWとの関連性が低いと判断され、ユーザーにクリックしてもらえる率が下がってしまう可能性があります。
そこで、Googleでは代わりのTitleを生成するアルゴリズムを利用する事があります。検索KWに合った代わりのTitleをしようすることで、ユーザーのクリック率は大幅に向上しています。つまり、検索するユーザー、サイト管理者双方に役立つことであると言えます。
検索KWに合った代わりのTitleを表示するだけでなく、他にはそのページを表すようなタイトルが付けられていなかったり、1 つのサイトのページ内でまったく同じ(またはほぼ同じ)タイトルが使われていたり、不必要に長かったり読みにくかったりした場合いに、Googleは代わりのTitleを表示する事があります。
上記の詳しい情報はGoogleウェブマスター向け公式ブログであるこちら をご覧になってみてください。
応援クリックにご協力ください!
↓↓↓↓↓