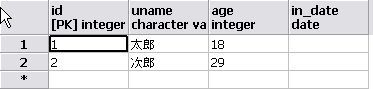
2010/08/21 11:39:50.312 [] INFO :: Job: [FlowJob: [name=jobDb]] launched with the following parameters: [{run.id=12}]
2010/08/21 11:39:50.937 [] INFO :: Executing step: [step1]
2010/08/21 11:39:51.156 [] ERROR :: Parsing error at line: 4 in resource=class path resource
[sample/sample-db.txt], input=[abc,タモリ,54]
org.springframework.batch.item.file.FlatFileParseException: Parsing error at line: 4, input=[abc,タモリ,54]
at org.springframework.batch.item.file.mapping.DefaultLineMapper.mapLine(DefaultLineMapper.java:49)
at org.springframework.batch.item.file.FlatFileItemReader.doRead(FlatFileItemReader.java:188)
at org.springframework.batch.item.support.AbstractItemCountingItemStreamItemReader.read(AbstractItemCountingItemStreamItemReader.java:85)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at org.springframework.aop.support.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:307)
at org.springframework.aop.framework.ReflectiveMethodInvocation.invokeJoinpoint(ReflectiveMethodInvocation.java:182)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:149)
(中略)
Caused by: java.lang.NumberFormatException: Unparseable number: abc
at org.springframework.batch.item.file.transform.DefaultFieldSet.parseNumber(DefaultFieldSet.java:688)
at org.springframework.batch.item.file.transform.DefaultFieldSet.readInt(DefaultFieldSet.java:290)
at sample.SimpleMapFieldSetMapper.read(SimpleMapFieldSetMapper.java:42)
at sample.SimpleMapFieldSetMapper.mapFieldSet(SimpleMapFieldSetMapper.java:34)
at sample.SimpleMapFieldSetMapper.mapFieldSet(SimpleMapFieldSetMapper.java:1)
at org.springframework.batch.item.file.mapping.DefaultLineMapper.mapLine(DefaultLineMapper.java:46)
... 43 more
2010/08/21 11:39:51.234 [] INFO :: Job: [FlowJob: [name=jobDb]] completed with the following parameters: [{run.id=12}] and the following status: [FAILED]
2010/08/21 11:48:29.078 [] INFO :: Job: [FlowJob: [name=jobDb]] launched with the following parameters: [{run.id=12}]
2010/08/21 11:48:29.296 [] INFO :: Executing step: [step1]
2010/08/21 11:48:29.468 [] INFO :: Job: [FlowJob: [name=jobDb]]
completed with the following parameters: [{run.id=12}] and the following status: [COMPLETED]
2010/08/19 23:29:03.921 [] INFO :: Job: [FlowJob: [name=jobDb]]
launched with the following parameters: [{run.id=1}]
2010/08/19 23:29:04.062 [] INFO :: Executing step: [step1]
2010/08/19 23:29:04.265 [] INFO :: Job: [FlowJob: [name=jobDb]]
completed with the following parameters: [{run.id=1}] and the following status: [COMPLETED]
public interface ItemReader<T>. Strategy interface for providing the data. Implementations are expected to be stateful and ... Implementations need *not* be thread safe and clients of a ItemReader need to be aware that this is the case. ... static.springsource.org/spring.../ItemReader.html - キャッシュ - 類似ページ
そのページの、All Known Implementing Classes: を見ると、実装クラスが分かります。