さて、今回は実際にStepタグを使用して処理を記述してみましょう!
まず、準備はこちら。サンプルではDB名を「sample」にしています。順次環境に合わせて名前を変えてください。
・Spring Batchを使えるようにするには? (準備編)
※DBも作成してください。(サンプルのdataSourceはPostgresになっています)
今回はRepositoryにDBも使用する予定ですが、もうひとつの記事を組み合わせてDBを使用しない方法に修正してもらってもよいです。
・Spring Batchを起動するには? (基本編)
処理内容:
1.CSVファイルを読み込む
2.読み込んだデータのフィールドの順番と、日付の書式を変更してファイルに出力
3.上記2のファイルをコピーし増やす
では、早速いってみましょう!
【注意点等】
ファイルは、sampleパッケージを作成し、そこにおいてください。
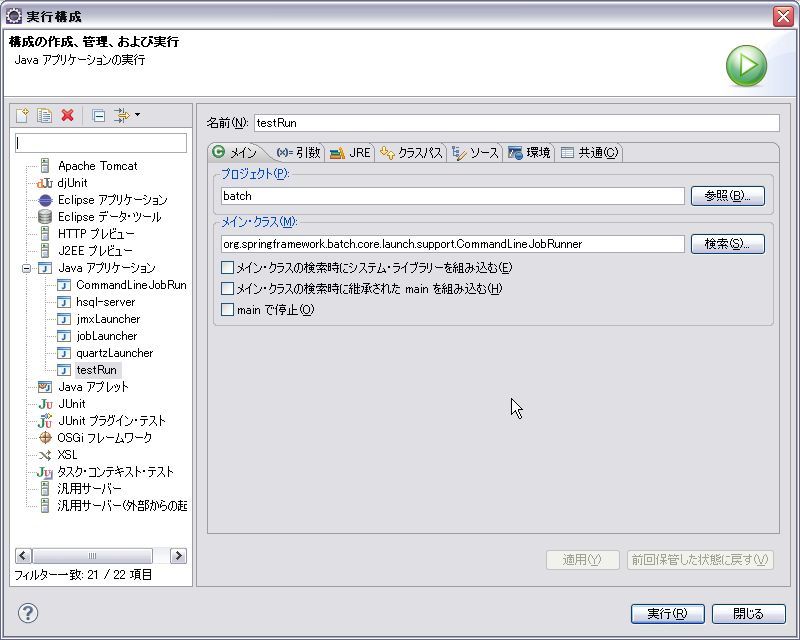
このときDBを使用する場合、前回の結果が残るのでeclipse上の実行設定で引数タブを
以下のように設定してください。(参考
)
classpath:/sample/run-context.xml jobFile -next
【/sample/test.txt ファイル (データファイル)】
2010/08/21,太郎,18
【/sample/back-context.xml ファイル(Batchバックグラウンドの設定)】
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans
"
xmlns:p="http://www.springframework.org/schema/p
"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance
"
xsi:schemaLocation="http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.1.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
">
<bean id="jobOperator"
class="org.springframework.batch.core.launch.support.SimpleJobOperator"
p:jobLauncher-ref="jobLauncher" p:jobExplorer-ref="jobExplorer"
p:jobRepository-ref="jobRepository" p:jobRegistry-ref="jobRegistry" />
<bean id="jobExplorer"
class="org.springframework.batch.core.explore.support.JobExplorerFactoryBean"
p:dataSource-ref="dataSource" />
<bean id="jobRegistry"
class="org.springframework.batch.core.configuration.support.MapJobRegistry" />
<bean class="org.springframework.batch.core.configuration.support.JobRegistryBeanPostProcessor">
<property name="jobRegistry" ref="jobRegistry"/>
</bean>
<bean id="jobLauncher"
class="org.springframework.batch.core.launch.support.SimpleJobLauncher">
<property name="jobRepository" ref="jobRepository" />
</bean>
<bean id="jobRepository"
class="org.springframework.batch.core.repository.support.JobRepositoryFactoryBean"
p:dataSource-ref="dataSource" p:transactionManager-ref="transactionManager" />
<!-- DB関連クラス --> 【/sample/run-context.txt ファイル(ジョブの処理の記述)】
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans
"
xmlns:p="http://www.springframework.org/schema/p
"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance
"
xsi:schemaLocation="http://www.springframework.org/schema/batch
http://www.springframework.org/schema/batch/spring-batch-2.1.xsd
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-2.5.xsd
">
<import resource="classpath:/sample/back-context.xml"/>
<!-- ジョブの処理 --> http://www.springframework.org/schema/batch
" incrementer="jobParametersIncrementer">
<step id="step1" parent simpleStep tasklet ref <!-- enables the functionality of JobOperator.startNextInstance(jobName) --> simpleStep <!-- ファイルを読み込みMapに入れる --> SimpleMapFieldSetMapper <!-- Mapをvalues()に展開(Extract)し、フォーマット変換した結果をファイルに出力していく
--> FormatterLineAggregator <!-- taskletタイプのクラス。DOSコマンドのファイルコピーを実施 --> 【SimpleMapFieldSetMapperクラス】
package sample;
import java.util.LinkedHashMap;
import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.validation.BindException;
/**
* LinkedHashMapにマップします。
*
*/ 【実行結果】 コンソール上の出力:
2010/08/17 23:32:56.281 [] INFO :: Job: [FlowJob: [name=jobFile]]
launched with the following parameters: [{run.id=1}]
completed with the following parameters: [{run.id=1}] and the following status: [COMPLETED]
ファイル出力:
C:/temp/spring_batch-test.txt
C:/temp/spring_batch-test2.txt (←step2で上のファイルをコピーした結果作成されます)
入力ファイルの内容:
2010/08/21,太郎,18
出力ファイルの内容:
【説明】
ここではstepをどのように書けばよいかを見ていきます。
再掲:
<!-- ジョブの処理 --> step simpleStep next step tasklet ref
<stepの記述>
stepに指定できるものは主に以下のものです。
①parent属性で基本になるbeanを指定します
simpleStepは、SimpleStepFactoryBeanクラスで、SpringのFactoryBeanを継承しています。
FactoryBeanはクラスを作るクラスで、SimpleStepFactoryBeanは単純なStepクラスを作成します。
上記の場合、作成された単純なStepが stepタグのid="step1"に設定されることになります。
このクラスを生成するFactory機能自体はSpringBatchではなく、Spring自体の機能です。
また、SimpleStepFactoryBeanで設定したプロパティはStepタグ内で上書きできます。
このFactoryを使用する他にも、Step自体を自作する方法もあります。
②taskletタグで、taskletを継承したクラスを指定します
指定しているcopyFileは、SpringBatchが用意しているクラスで、
システムのコマンドを実行するtaskletです。
timeoutプロパティは必ず指定する必要があります。
そのままcopyコマンドを実行できないので、cmdコマンドからcopyを実行しています。
その他のtaskletには、MethodInvokingTaskletAdapterのように
他のbeanのメソッドを実行するものもあります。
もちろん、Taskletインターフェースを継承して自作のTaskletを作成してもOKです。
③他のjobを呼び出します
stepとして、他のjob名を指定してコマンドのように呼び出すことができます。
このときパラメタも指定できます。ここでは詳しく説明しません。
<idについて >
stepタグなどのidは、裏ではSpringのbeanタグのidと同じ扱いになっています。
ですので、beanのidと重なるとエラーが発生します
個人的には、stepなどのidについては"step.xxx"にするとか、プレフィックスをつけておいたほうが
idが衝突する確率が下がるので良いのかなと思っています。
<処理の順番>
もう1つ重要な要素があります。
next属性です。
なんとなく想像付くと思いますが、stepの処理が終わった後に次のstepがどれかを指定します。
一度も通らないstepが存在するとエラーになります。
jobタグ内に一番最初に記述されたstepが一番最初に処理されますが、その後の記述の順番は処理の順番と関係しません。
すべてnextなどで順番を記述するからです。
【作成したクラスSimpleMapFieldSetMapperについて】
今回はクラスを作っています。
再掲:
<bean class="sample.SimpleMapFieldSetMapper
これは、FileItemReaderで使用されるクラスで、読み込んだデータをbeanに設定していく方法を定義したクラスです。
beanに設定していくことをmapするという言い方をするようです。
本当はbeanはgetter/setterが記述されたPOJOクラスであるべきですが、いろいろ実験する場合に
1つ1つファイルごとにbeanを作るのはメンドウなので、LinkedHashMapにmapするクラスを作りました。
このクラスは型変換もしてくれます。(String,Date,intだけですが)
たぶん割と遊べるクラスになっていると思いますので、他のItemWriterクラスなどを試すのにも使用してみてください。
【FormatterLineAggregator について(ItemWriter関連)】
このクラスは、ファイル書き込み用のクラスの中で設定されています。
ItemReaderで取得したデータをファイルにどのように展開するかを定義するクラスです。
再掲:
<bean class="org.springframework.batch.item.file.transform.FormatterLineAggregator %2$s,%1$tY%1$tm%1$td,%3$d
PassThroughFieldExtractorは単純なクラスで、受け取ったデータを何も加工せずに展開します。
例えば、渡ってきたデータがMapの場合、values()メソッドを呼び出すだけです。
Listが渡ってくれば、toArray()メソッドを呼び出すだけです。
展開の結果をどのような書式にするかを記述しているのがformatプロパティです。
%2$sという記述は、配列の2番目を文字列として出力するということです。
この機能により、フィールドの順番を入れ替えています。
以上で説明は終了です!ありがとうございます。
お疲れ様でした
参照:
・トップ
・SpringBatch機能について
・実際に作成するものとは(Stepの概念について)
・CommandLineJobRunnerとは?
・Spring Batchを起動するには? (基本編)
SpringBatch本家のドキュメント