今までの記事で、Spring Batchの概念、必要な準備を見てきました。
ここでは、実際に簡単なサンプルを動かしてみます。
【準備】
まず、以下の記事のライブラリをダウンロードしてプロジェクトに追加してください。
DBの準備はこの記事ではいりません!
・Spring Batchを使えるようにするには? (準備編)
実際には、DBの準備が必要ですが、この記事ではテスト用のごまかす方法で設定をしています。
<ライブラリの追加>
上記の記事を参考にjarファイルをダウンロードしたら、プロジェクトに追加します。
binというディレクトリを作成して、そこにドラッグ&ドロップすれいいだけです。
次に、ドロップしたjarファイルとプロジェクトを結び付けます。
「プロジェクト」 ⇒ 「プロパティ」 でプロパティを表示し、「Javaのビルド・パス」を選択します。

↑「JARの追加」ボタンを押して、
ドロップしたフォルダ内のjarファイルすべてを選択します。
とりあえず準備は以上です!
次に、実際にSpring Batchの設定を書いてみましょう。
【設定の作成】
これからやることを先に記述しておきます![]()
<処理内容>
1.CSVファイルを読み込みます。読み込まれたデータはFieldSetというbatchのクラスに設定されます。
(FieldSetをPOJOに設定することもできますがメンドウなのでそのまま使ってます。)
2.読み込んだFieldSetをtoString()してファイルに出力します。
う~ん。全く意味のない処理ですね(笑)
でも、自分でプログラミングしなければならない箇所はありません![]()
すべてSpringの設定だけで実現できちゃいます![]()
<c:/temp/read.csv ファイル(読み込みファイル)>
内容は以下のとおりです。ファイルを指定の場所に配置してください。
1,2,3
5,7,8
<launch-context.xml ファイル>Springの設定ファイルの内容です。
プロジェクトのexampleパッケージの下にでも置いてみてください。
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans " xmlns:p="http://www.springframework.org/schema/p " xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance " xsi:schemaLocation="http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch-2.1.xsd http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-2.5.xsd ">
<!-- SpringBatchの裏で動作しているbeanの設定 -->
<bean id="jobOperator" class="org.springframework.batch.core.launch.support.SimpleJobOperator" p:jobLauncher-ref="jobLauncher" p:jobExplorer-ref="jobExplorer" p:jobRepository-ref="jobRepository" p:jobRegistry-ref="jobRegistry" /> <bean id="jobExplorer" class="org.springframework.batch.core.explore.support.JobExplorerFactoryBean" p:dataSource-ref="dataSource" /> <bean id="jobRegistry" class="org.springframework.batch.core.configuration.support.MapJobRegistry" /> <bean class="org.springframework.batch.core.configuration.support.JobRegistryBeanPostProcessor"> <property name="jobRegistry" ref="jobRegistry"/> </bean> <bean id="jobLauncher" class="org.springframework.batch.core.launch.support.SimpleJobLauncher"> <property name="jobRepository" ref="jobRepository" /> </bean> <bean id="jobRepository" class="org.springframework.batch.core.repository.support.MapJobRepositoryFactoryBean" p:transactionManager-ref="transactionManager" />
<!-- ダミーのDB関連クラス --> <bean id="dataSource" class="org.springframework.jdbc.datasource.SingleConnectionDataSource"> </bean> <!-- ダミーのDB関連クラス --> <bean id="transactionManager" class="org.springframework.batch.support.transaction.ResourcelessTransactionManager" > </bean> <!-- 実際のバッチ処理 ============================================================== --> <job id="jobFile" xmlns="http://www.springframework.org/schema/batch" incrementer="jobParametersIncrementer"> <step id="step1" parent="simpleStep"> <tasklet> <chunk reader="fileItemReader" writer="fileItemWriter" /> </tasklet> </step> </job> <!-- enables the functionality of JobOperator.startNextInstance(jobName) --> <bean id="jobParametersIncrementer" class="org.springframework.batch.core.launch.support.RunIdIncrementer" /> <bean id="simpleStep" class="org.springframework.batch.core.step.item.SimpleStepFactoryBean" abstract="true"> <property name="jobRepository" ref="jobRepository" /> <property name="startLimit" value="100" /> <property name="commitInterval" value="1" /> </bean> <bean id="fileItemReader" class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"> <property name="resource" value="file:c:/temp/read.csv" /> <property name="lineMapper"> <bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper"> <property name="lineTokenizer"> <bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"> <property name="names" value="ID,bizDate,userName" /> </bean> </property> <property name="fieldSetMapper"> <bean class="org.springframework.batch.item.file.mapping.PassThroughFieldSetMapper" /> </property> </bean> </property> </bean>
<!-- toString()した結果をファイルに出力するWriter --> <bean id="fileItemWriter" class="org.springframework.batch.item.file.FlatFileItemWriter"> <property name="resource" value="file:c:/temp/spring_batch-test.txt" /> <property name="lineAggregator"> <bean class="org.springframework.batch.item.file.transform.PassThroughLineAggregator" /> </property> </bean> </beans>
【実行】
では、実際に動かしてみましょう!
①プロジェクトを右クリックし、「実行」 ⇒ 「実行の構成」 を選択します。
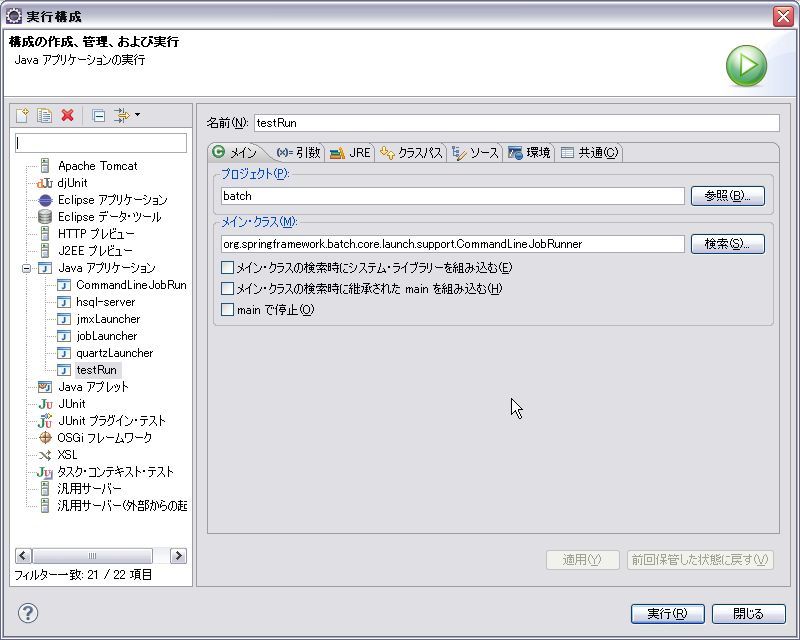
左側の「Javaアプリケーション」を選択し、
メインクラスに以下を設定します。
org.springframework.batch.core.launch.support.CommandLineJobRunner
次に「引数」タブを選択します。
「プログラムの引数」に、以下を設定します。
classpath:/example/launch-context.xml jobFile
②実行を押すとプログラムが実行されます。
【実行結果(作成されるファイル: c:/temp/spring_batch-test.txt)】
{ID=1, bizDate=2, userName=3}
{ID=5, bizDate=7, userName=8}
【説明】
さて、うまく動作して、ファイルができましたでしょうか?
うまくいかなかった方は、読み込みファイルの場所や、設定ファイルの場所などを確認してみてください。
読み込みファイル : c:/temp/read.csv
設定ファイル : プロジェクト内の、/example/launch-context.xml
では、簡単に設定の内容を見ていきましょう。
XML設定ファイルの前半は、SpringBatchの基本設定で、ほぼどのバッチ処理でも記述しないといけません。
これらは以下の記事の「全体の概要」に詳しく書きましたので見てみてください。
これらの記事での登場人物がいっぱい出てきていて、親近感が湧きますね![]()
<Repositoryの保存先をごまかす>
この中でも特に重要なのがRepositoryで、これは処理結果であるExecutionの保存先です。
通常、Repositoryクラスの先にあるのはDBです。
しかし、今回はDBを使用していません。
どうやってごまかしたのでしょうか?
マジックは、以下の二つのクラスの使用です。
MapJobRepositoryFactoryBean ・・・メモリ上にRepositoryを用意する
ResourcelessTransactionManager ・・・トランザクションをごまかす
これらは、メモリ上にリポジトリを展開するための常套手段のようです。
メモリに展開するならトランザクションはいらないはずなのですが、何故か必要になります。
なので、トランザクションをごまかすクラスを使用します。
※この方法はテスト用のものです。本番では使用しないでください。
何故かというと、処理結果が保存されないのでrestartなどが使用できないからです。
restartとは、処理が途中でFAILしたときにFAILした処理から実施する機能です。
このためには処理結果(どこまで終了したか?)をどこかに保存しておく必要があります。
メモリに処理結果を記述するのでJavaが起動し終わるたびにクリアされちゃいますよね![]()
もし、いつでも最初から処理し、restartなどの機能を使用しないならこれでもいいかもしれません。
<実際のバッチ処理>
実際のバッチ処理の部分では、「Job」というタグがあります。
これが実際のバッチ処理を記述するものです。
先立って以下の記事を読んでおくと分かりやすいと思います。
jobの中には、stepがあり、これが実際の具体的な処理になります。
ここでは1つしか記述していませんが、複数記述できます。
再掲:
<job id="jobFile" xmlns="http://www.springframework.org/schema/batch "
incrementer="jobParametersIncrementer">
<step id="step1" parent="simpleStep">
<tasklet>
<chunk reader="fileItemReader" writer="fileItemWriter" />
</tasklet>
</step>
</job>
さらにstepの中には、readerとwriter、processorがあります。
ここではprocessorは使用していません。
stepの処理は、read ⇒ process ⇒ write の順番に処理されます。
この流れをreadでデータ読み込めなくなるまで実施し、stepが終了します。
ここでは、readerでCSVファイルの読み込み、writerでファイルへの書き込みをしています。
<stepについて>
実際のstep処理は、stepというタグで記述されていますが、このタグの具体的なクラスは、
SimpleStepFactoryBean
です。
順番に処理するような単純な処理であればこれを使用すれば十分です。
stepタグにはparentというタグがあります。
この中で上記のSimpleStepFactoryBeanが使用されています。
parentはJavaのクラスのように継承するクラスで、設定されたpropertyを上書きすることもできます。
SimpleStepFactoryBeanのプロパティは以下のとおりです。
【SimpleStepFactoryBeanのプロパティ】
| プロパティ名 | 設定内容 |
|---|---|
| allowStartIfComplete | すでにJOBが処理成功(COMPLETE)になっていると通常、AlreadyComplete例外が発生します。しかし、この値を操作することで回避できます。 |
| beanName | stepが作られたときのstep名になります。 |
| chunkCompletionPolicy | チャンク単位でのCompletePolicyを設定します。 |
| chunkOperations | chunkOperationsを設定します。境界、トランザクションなどの条件を操作できます。 |
| commitInterval | 何回readが行われるとコミットが実施されるかを設定します。 |
| exceptionHandler | 例外ハンドラを設定します。 |
| isolation | ビジネスのisolationレベルを設定します。 |
| isReaderTransactionalQueue | Flag to signal that the reader is transactional (usually a JMS consumer) so that items are re-presented after a rollback. |
| itemProcessor | stepタグの中でもここでもprocessorを設定できます。ただし、step内でも設定した場合、step内の設定で上書きされます。 |
| itemReader | 同上 |
| itemWriter | 同上 |
| jobRepository | 同上 |
| listeners | 同上 |
| propagation | 同上。DBトランザクションの設定。 |
| singleton | Public setter for the singleton flag. |
| startLimit | Public setter for the start limit for the step. |
| stepOperations | Public setter for the stepOperations. |
| streams | The streams to inject into the Step. |
| taskExecutor | Public setter for the TaskExecutor. |
| throttleLimit | Public setter for the throttle limit. |
| transactionManager | Public setter for the PlatformTransactionManager. |
| TransactionTimeout |
<実際のファイル処理>
おおまかな流れはつかめたと思います。
ここでは、ファイルの読み込み、書き込みに使用しているクラスを見ていきましょう。
FlatFileItemReader
これはカンマ区切り、タブ区切りなどのテキストファイルを読み込むクラスで、
Springが用意してくれいているクラスです。
区切り文字は他のクラスDelimitedLineTokenizerで設定します。
また、読み込んだデータはPOJOに設定することもできますが、POJOを用意するのが
メンドウでしたのでFieldSetをそのまま渡すクラスPassThroughFieldSetMapperを使用してみました。
FlatFileItemWriter
これはテキストファイルにデータを書き込むクラスです。
ここではFieldSet をtoString()するクラスPassThroughLineAggregatorを使用してみました。
どうでしょう?
何もプログラムしなくても結構いろいろできますね!
SpringBatchでは、たくさんの処理用のreader, writerのクラスが用意されています。
ファイルだけでなくDBから値を取得するクラスや、DBに書き込みするクラスもあります。
また、ファイルの妥当性チェックも設定だけで実行する仕組みが用意されています。
ファイルの読み込みに関しては、複数の行を1つのラインのように読み込む機能もあるようです。
自分は結構いろいろ用意されていておもしろい!って思いましたが、
面白さが伝わりましたでしょうか?
参照:
・CommandLineJobRunnerとは?
Spring Batchについて