SpringBatchには、コミット数を設定できる機能があると今までの記事で書いてきました。
ここでは、その機能についてみてみましょう!
ついでに、
処理の途中でエラーが発生したときにrestartさせた動きも見てみましょう。
ちなみに、
コミットはDBだけでなく、ファイルの書き込みにも関係していますので、
設定する数をうまく選んで処理スピードが速くなるようにしましょう![]()
【サンプル】
サンプルは、前回の記事と同じものを使用します。
上記の内容をすべて実行したら、以下の準備もお忘れなく!
・DBのmemberテーブルのデータをすべてクリアしておく
・起動の引数に、-nextをつけて実行する (つけないとAlreadyCompleted例外が発生すると思います)
【説明】
再掲:
<!-- ジョブの処理 -->
<job id="jobDb" xmlns="http://www.springframework.org/schema/batch
"
incrementer="jobParametersIncrementer">
<step id="step1" parent="simpleStep" >
<tasklet >
<chunk reader="fileItemReader" writer="dbItemWriter" commit-interval="2" />
</tasklet>
</step>
</job>
commit-interval="2"となっています。
つまり、コミットタイミングが2個と設定されています。
データ2個ごとにデータがコミットされます。
サンプルでは、ファイルからの読み込みになっているので、2行を溜め込んで、2行をDBに書き込んで
コミットすると言うことになります。
処理のイメージは以下のとおりです。
List items = new Arraylist();
for(int i = 0; i < commitInterval; i++){
items.add(itemReader.read());
}
itemWriter.write(items);
なんとなく動きが理解できましたでしょうか?
write()が内部で実際どのような処理になっているかは、使用するItemWriterによります。
ちなみにFlatFileItemWriterでも、commitIntervalの数を上げると格段に処理が早くなります。
しかし、数を上げすぎるとDBでもファイルでも、Out Of Memory例外が発生することもあります。
もちろん、起動時にheapサイズなどを設定しておけば対応できますが、限界があるので
最適値というものが存在します。
何回か走行して最適値を見つけましょう!
<ページングを使用したDBの読み込みと書き込みのコミットについて>
ページングItemReaderの機能を使用すると、一気に指定のページサイズ分だけデータを読み込みます。
そして、WriterがDBに値を書き込みます。
一気に操作する数の設定項目が、「ページサイズ」と「コミット数(commitInterval)」2つあります。
2つの設定が実際の動作にどのように関わるかを簡単に見てみます。
実際に実験した内容です。
<<設定値>>
ページサイズ: 1000
コミット数 : 100
<<動作>>
1.select文が実行され、1000レコードが読み込まれる。
2.insert文をバッチ機能で100レコード一気に挿入する。
3.2を10回繰り返し、1000レコード分が処理される。
4.1に戻って繰り返し。select文でデータ取れなくなるまで実行される。
なんとなく動作わかりましたでしょうか?
ちなみに、何回SQL文が実行されるでしょうか?
もし対象レコードが10000レコードあるとすると、
select文 = 10000÷1000 = 10回
insert文 = (10000÷1000)×(1000÷100) = 100回
(バッチ機能は1度SQL解釈してデータを一気に流し込みます)
ついでに、ページ機能、commitInterval機能を使用しなかった場合も見ておきましょう。
select文 = 1回
insert文 = 10000回
select文が少ない分、insert文の発行数が増えるので遅くなるのですね。
【restartの動作について】
では次に途中でエラーが発生した場合の動作を見てみましょう。
<準備>
前回の記事のサンプルでエラーを起こさせるには、以下のようにデータを書き替えます。
<データ>
1,太郎,18
2,次郎,29
3,さんま,53
abc,タモリ,54
5,鶴野,28
4行目が文字になっているので変換エラーが起きます。
しかも、コミット数は2にしているので、3行目のinsert処理をしてからエラーが起きます。
つまり、ちゃんとロールバックされていれば3行目の反映が無視され、2行目までが登録されているはずです。
<実行結果>
↓ログ
2010/08/21 11:39:50.312 [] INFO :: Job: [FlowJob: [name=jobDb]] launched with the following parameters: [{run.id=12}]
2010/08/21 11:39:50.937 [] INFO :: Executing step: [step1]
2010/08/21 11:39:51.156 [] ERROR :: Parsing error at line: 4 in resource=class path resource
[sample/sample-db.txt], input=[abc,タモリ,54]
org.springframework.batch.item.file.FlatFileParseException: Parsing error at line: 4, input=[abc,タモリ,54]
at org.springframework.batch.item.file.mapping.DefaultLineMapper.mapLine(DefaultLineMapper.java:49)
at org.springframework.batch.item.file.FlatFileItemReader.doRead(FlatFileItemReader.java:188)
at org.springframework.batch.item.support.AbstractItemCountingItemStreamItemReader.read(AbstractItemCountingItemStreamItemReader.java:85)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at org.springframework.aop.support.AopUtils.invokeJoinpointUsingReflection(AopUtils.java:307)
at org.springframework.aop.framework.ReflectiveMethodInvocation.invokeJoinpoint(ReflectiveMethodInvocation.java:182)
at org.springframework.aop.framework.ReflectiveMethodInvocation.proceed(ReflectiveMethodInvocation.java:149)
(中略)
Caused by: java.lang.NumberFormatException: Unparseable number: abc
at org.springframework.batch.item.file.transform.DefaultFieldSet.parseNumber(DefaultFieldSet.java:688)
at org.springframework.batch.item.file.transform.DefaultFieldSet.readInt(DefaultFieldSet.java:290)
at sample.SimpleMapFieldSetMapper.read(SimpleMapFieldSetMapper.java:42)
at sample.SimpleMapFieldSetMapper.mapFieldSet(SimpleMapFieldSetMapper.java:34)
at sample.SimpleMapFieldSetMapper.mapFieldSet(SimpleMapFieldSetMapper.java:1)
at org.springframework.batch.item.file.mapping.DefaultLineMapper.mapLine(DefaultLineMapper.java:46)
... 43 more
2010/08/21 11:39:51.234 [] INFO :: Job: [FlowJob: [name=jobDb]] completed with the following parameters: [{run.id=12}] and the following status: [FAILED]
<さらにrestartする>
さて、予定通りエラーになりました。
ログにはちゃんとエラーになった行番号とデータの内容が出力されています!
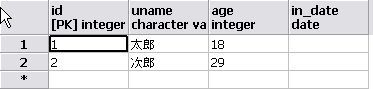
DBのテーブルの中身を確認してみてください。2行目までしか登録されてないですよね!
では、restartしてみましょう。
まず、ファイルのデータを元に戻してください。(これ忘れずに!)
1,太郎,18
2,次郎,29
3,さんま,53
4,タモリ,54
5,鶴野,28
次にコマンドの実行するときに引数タブ内の記述で、-restartをつけて実行してください。
classpath:/sample/runDb-context.xml jobDb -restart
<処理結果>

↓ログ
2010/08/21 11:48:29.078 [] INFO :: Job: [FlowJob: [name=jobDb]] launched with the following parameters: [{run.id=12}]
2010/08/21 11:48:29.296 [] INFO :: Executing step: [step1]
2010/08/21 11:48:29.468 [] INFO :: Job: [FlowJob: [name=jobDb]]
completed with the following parameters: [{run.id=12}] and the following status: [COMPLETED]
正常に終了しましたね。
DBのテーブルも見てみてください。
残りのデータが全部登録されました!
【まとめ】
SpringBatchを使用するだけで、手間はSQLのコマンドシェルみたいなものを作るのと同じくらいで
コミットタイミングの制御、およびrestartの機能まで実装できることを見ました。
かなり便利です。
少し覚えることはありますが、直感に近いのでそれほど惑わないと思います。
同様のSpringを使用したバッチ機能にTERAバッチというフレームワークがありますが
こちらはどうなんでしょうね。
気になります。
参照: