今日は、アメーバで利用しているオープンソースの検索エンジンであるLucene/Solr の新機能の一つをご紹介します。いつもLucene/Solrの恩恵を受けているので、少しでも普及に繋がると嬉しいです。
紹介するのはLucene 3.2以降のバージョンで利用可能となるTieredMergePolicyです。
以下に、LuceneにおけるインデックスのSegment構成、MergePolicyの概要、TieredMergePolicyの特徴とアメーバの対応について記述します。
■ Luceneにおける転置インデックスのSegment構成
Luceneの転置インデックスは、各々が独立したSegmentという単位で構成されており、ドキュメントの追加分をflushする際、新しい世代番号を付けたSegmentを生成していきます(図1)。
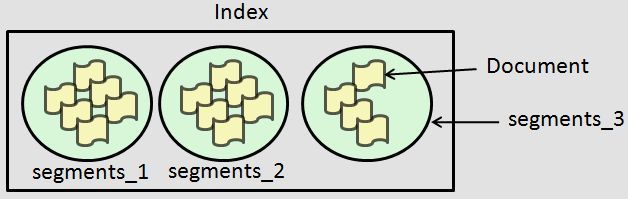
図1 LuceneのインデックスにおけるSegmentの概念
Segmentの集合があるデータサイズまたはドキュメント数に達すると、Segment間マージが発生し、インデックス全体のSegment数がコントロールされる仕組みになっています。このマージ対象を抽出するロジックはLogByteSizeMergePolicy(デフォルト)やLogDocMergePolicyで記述されており、処理自体は別スレッドで行うConcurrentMergeScheduler(デフォルト)で実施されます。検索パフォーマンスを最も向上させるには、拡散しているSegmentを1つにまとめるoptimize処理を行い、検索時のSegment間マージをなくすことが有効です。マージ処理を行う目的は、下記の3つが挙げられます。
1. Segmentに残っている削除可能なインデックスのクリーンアップを行い、
リソースの有効活用と検索パフォーマンスの改善を図る。
2. インデックスの更新、検索共にそれなりのパフォーマンスが出るSegment数とサイズを維持する。
3. File Descriptorの枯渇を防ぐ。
■マージSegmentの抽出方法
LogMergePolicyでは、マージ対象となるSegmentかどうかをパラメータminMergeSizeとmergeFactorから、下記の判定方法に従って選択します。

収集のされ方を図示すると図2のようになります。

図2 Segmentのマージ処理(mergeFactor=3の場合)
CommitterのMike McCandless氏が公開している非常にわかりやすい動画もご紹介します(動画1)。
動画1 29GBのWikipediaテキストをインデクシングした際のSegmentの様子。
最終的なインデックスサイズは10.87GBとなったが、途中のマージ処理で扱われた
データサイズは67.3GBに及ぶ。この実験ではSSDを使用しており、write amplificationは6.19
■ MergePolicyの課題とTieredMergePolicy
LogMergePolicyにおいて、Segmentサイズは指数的に増大するため、マージ処理にかかるコストも無視できないほどの負荷になってきます。また、マージ処理が行われるまで、インデックス内の削除ドキュメントも残っているため、大きなインデックスになるほど、削除分にばらつきが出てくるのですが、マージ対象はDocument IDが連なったレンジでなければいけない、という制約がありました。そのため、不適切な組み合わせのSegment選択に起因する、不安定なパフォーマンス劣化が課題となっていましたが、より効率的で柔軟なSegment選択をできるようにしたものが、TieredMergePolicyです。
TieredMergePolicyは名前の通り、階段上(降順)となるようにマージ対象Segmentを抽出します。抽出方法はskewという独自スコアを算出し、最もマージ後のSegmentサイズの傾きが小さくなるような組み合わせを選択します。主なパラメータとして、maxMergeAtOnce(1回のマージで扱う上限Segment数)、maxMergedSegmentBytes(マージ後のセグメント上限サイズ)、floorSegmentBytes(小さなSegmentサイズに対して、skewの算出上切り上げる値)、segsPerTier(TierごとのSegment数を決める値)があります。
TieredMergePolicyの最も大きな改善点は、Segment全体からDocument IDの連なりを気にせず、マージ対象を選択できる点です。これを実現するためにIndexWriterも変更されました。動画2は動画1と同様、Mike McCandless氏が公開しているTieredMergePolicyの様子です。既存のLogByteSizeMergePolicyとの比較など、詳しくは下記の記事をご参照ください。
http://blog.mikemccandless.com/2011/02/visualizing-lucenes-segment-merges.html
動画2 TieredMergePolicyの様子
■ アメーバのMergePolicyについて
今までアメーバでは、本課題に対してcontrib/miscにあるBalancedSegmentMergePolicy(LinkedInのJohn Wang氏がZoieMergePolicyをLuceneへコミットしたもの)を利用してきました。
BalancedSegmentMergePolicyは、SegmentをSmall SegmentとLarge Segmentで分けて考え、Small Segmentは、LogByteSizeMergePolicyと同じMergePolicyを適用します。そして、Small Segmentの合計データサイズがLarge Segmentの平均に到達すると、Viterbiアルゴリズムを用いて、サイズ変動が最小化されるようにマージ対象を選択します。下記の表1は実際にLogByteSizeMergePolicyと比較したものです。検索時のパフォーマンスが平均・分散共にLogByteSizeMergePolicyよりも良い結果となっています。
○検証環境
OS:CentOS5.4
CPU:8core(Xeon E5620 2.40GHz)
メモリー:16GB
HDD:147GB SAS 15,000RPM
RAID: raid1
FS: ext3(noatime)

表1 tachy検索に対して、200万docのインデックスが既に存在する状態から
さらに400万docの更新と検索を同時に行った時のパフォーマンス比較
今回のエントリーでは、MergePolicyをテーマにLuceneの新機能についてご紹介しました。ブログ検索のように大規模になってくると、Solrを使ってMaster/Slave構成を取っていますが、新サービスなどのスモールスタートサービスでサーバ台数を少なくしたい場合やリアルタイム検索を行いたい場合には、安定した検索パフォーマンスを発揮するBalancedSegmentMergePolicyやTieredMergePolicyが活きてきます。