いよいよ、irisデーターセットを使って、学習と思ったら
参考にさせてもらったページに
「データフレームにしておくと、データを扱いやすくなります、、、、」
データーフレーム って何 超初心者なのですぐにつまずきます
Pandas(パンダス)とは、データ解析を容易にする機能を提供するPythonのデータ解析ライブラリです。
pandasの大きな特徴にpandas.DataFrame(データフレーム)というオブジェクトがあります。
で データーフレーム で検索
DataFrame(データフレーム)
pandasの大きな特徴にpandas.DataFrame(データフレーム)というオブジェクトがあります。
データフレームで、2次元の表形式のデータを処理します。 Series と同様に値とそれが何かを示す見出しを持っています。
行方向の見出しをインデックスと呼びます。 列方向の見出しを列名一覧と呼ぶことにします。
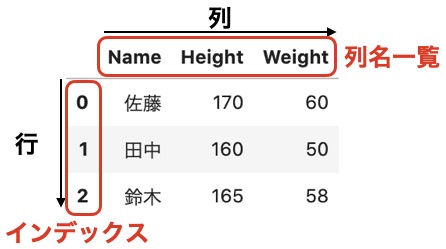
行列として扱うわけですね

から 取り出させてもらいました
<sampleD01.py>
from sklearn.datasets import load_iris iris = load_iris()import pandas as pddf = pd.DataFrame(iris.data, columns=iris.feature_names)df['target'] = iris.target df.loc[df['target'] == 0, 'target'] = "setosa" df.loc[df['target'] == 1, 'target'] = "versicolor" df.loc[df['target'] == 2, 'target'] = "virginica"
irisのデーターを2次元配列で処理しようとしてるのはわかりましたが
iris.feature_names って何?
iris.feature_names には、さっきの【4 つの特徴とはどんな情報か】が書かれています。らしいです
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']らしいです。