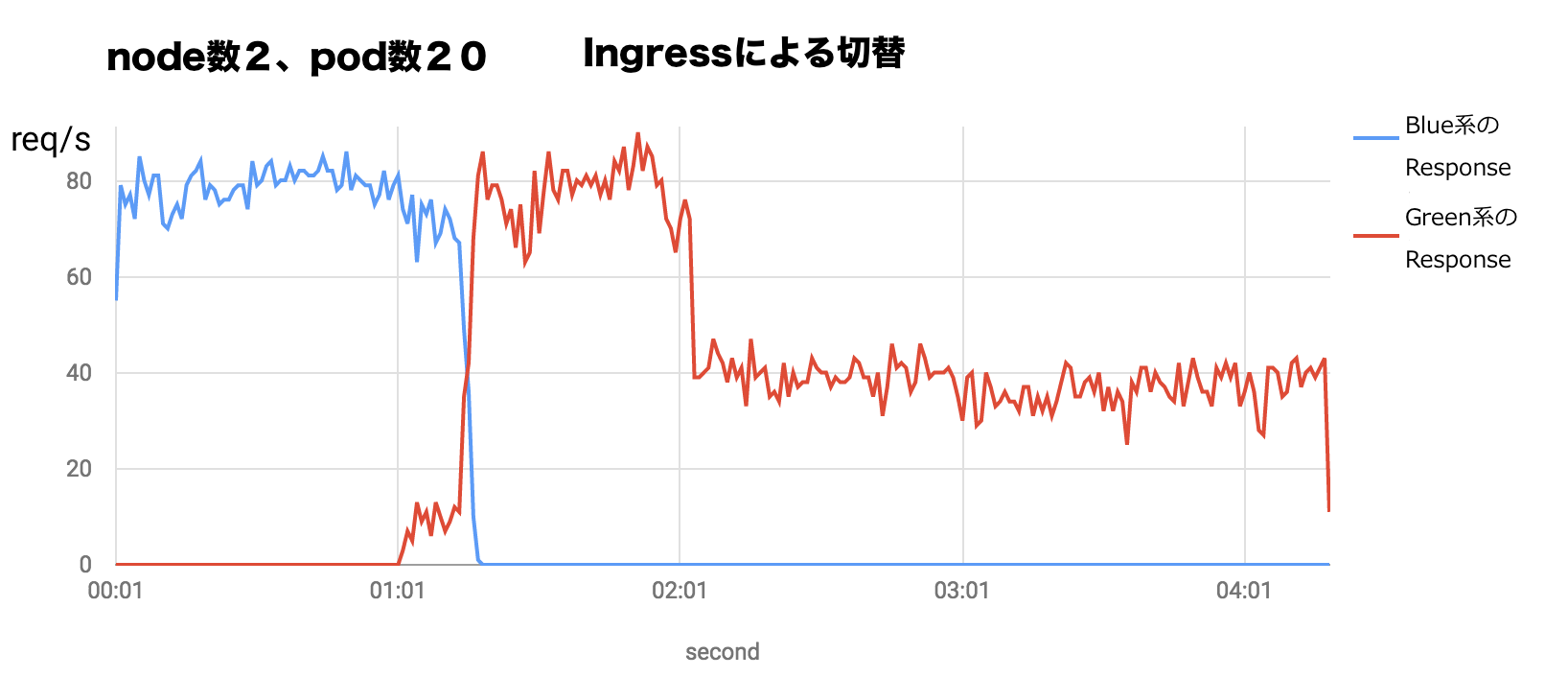
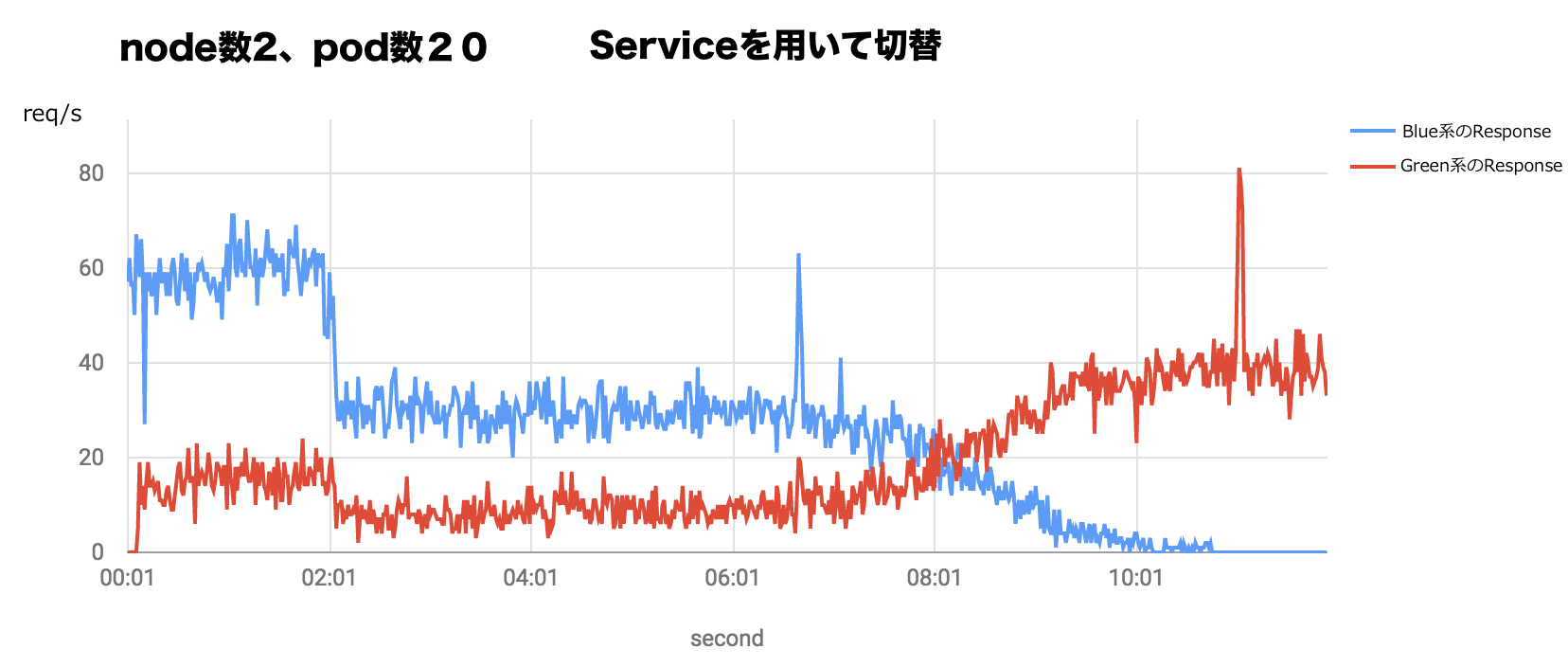
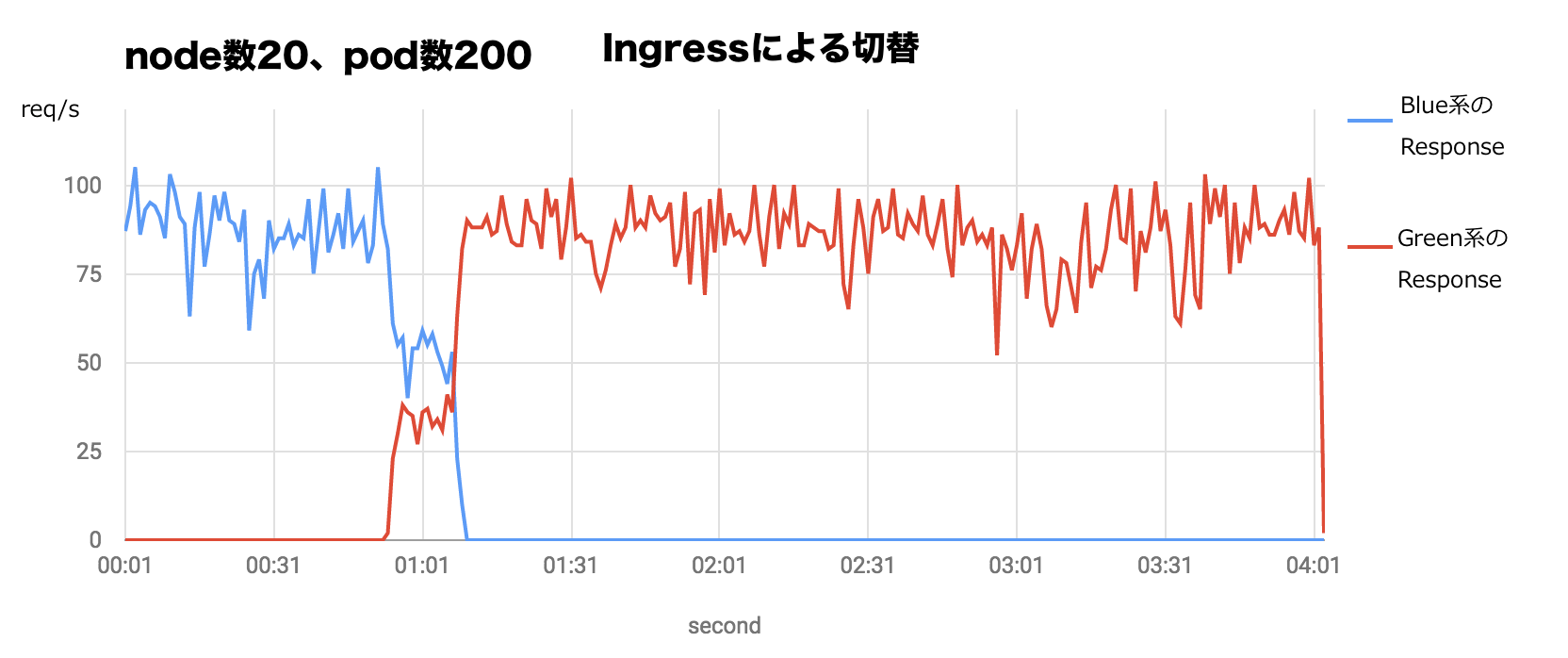
最近、kubernetesをさわりはじめました。
チュートリアルやってもあれなので、Redmineを立てたときのTips的なものを。
ローカルの操作PCとしてMac
Redmine構築先はGCP上のGKEでRedmineを立てます。
ローカルのMacにはgcloudコマンド、kubectlコマンドが入っているとします。
(kubectlが入ってない場合は、gcloud components install kubectlでインストールしてください)
dockerコマンドをMac上で実行するので、dockerコマンドを
実行できる環境を用意してください。
ローカルでもkubenetesをつかいたいので
私は、minikube(https://github.com/kubernetes/minikube)をインストールしました。
お手軽にGKE上でRedmineをたてたいので、
すでに作ってくれた人のものを利用します。
https://github.com/bitnami/bitnami-docker
手順はここに書いてある通りなのですが、いくつか修正したので、そこを解説
https://github.com/bitnami/bitnami-docker/tree/master/gke/redmine
まず、minikubeをいれるとはまるのが、contextです
とりあえず、向き先を確認します。
$ kubectl config current-context
minikube
となっていたら、ローカルを見ているので、GKE上を見るようにします。
ちなみに、先にGoogleのconsole上でclusterをつくっておいてください。
$ kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: REDACTED
server: https:/XXX.YYY.ZZZ.WWW
name: gke_example_asia-east1-a_cluster-1
- cluster:
certificate-authority: /Users/example/.minikube/ca.crt
server: https://192.168.99.100:8443
name: minikube
- cluster:
certificate-authority-data: REDACTED
server: https://192.168.1.10
name: vagrant
contexts:
- context:
cluster: gke_example_asia-east1-a_cluster-1
user: gke_example_asia-east1-a_cluster-1
name: gke_example_asia-east1-a_cluster-1
- context:
cluster: minikube
user: minikube
name: minikube
- context:
cluster: vagrant
user: vagrant
name: vagrant
current-context: minikube
で作成済みのclusterを確認します。
GKEのcontextはgke_*ではじまっているやつです
$ kubectl config set-context gke_example_asia-east1-a_cluster-1
でGKEを向くようにします。
手順にもどると
まず、cloneします。
$ git clone https://github.com/bitnami/bitnami-docker.git
作成するRedmineの環境は
フロントにWebrikでうごくRedmine
バックエンドにMariaDBのMaster、Slaveの構成です
READMEには、Redmine、MariaDBのSlaveのPodsを複数にしてますが(replica=3)、
そんなにいらないので、それぞれ1にして構築します
まず、DBのストレージを作成します。
$ gcloud compute disks create --size 100GB mariadb-disk
ディスクの名前は、kubenetesのYamlに記載してあるので、あわせておきます。(mariadb-disk)
sizeは200GBが推奨(200GB未満だと、パフォーマンスがおちる)ですが、
そんなにデータをつくらないので、今回100GBにします
データベースのMasterをつくります。
cloneしたディレクトリのgke/redmine配下に必要なファイルがあります。
cloneしたものは、ReplicationControllerをつかっていますが、
Deploymentを使う事にします。(今後Deploymentが主流だと思うので)
mariadb-master-deployment.yml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: mariadb-master
spec:
replicas: 1
template:
metadata:
labels:
app: mariadb-master
spec:
containers:
- name: mariadb-master
image: bitnami/mariadb:10.1.13-r0
env:
- name: MARIADB_DATABASE
value: redmine_production
- name: MARIADB_USER
value: redmine
- name: MARIADB_PASSWORD
value: secretpassword
- name: MARIADB_REPLICATION_MODE
value: master
- name: MARIADB_REPLICATION_USER
value: replication
- name: MARIADB_REPLICATION_PASSWORD
value: secretpassword
ports:
- containerPort: 3306
name: mariadb-master
volumeMounts:
- name: mariadb-persistent-storage
mountPath: /bitnami/mariadb
livenessProbe:
tcpSocket:
port: 3306
initialDelaySeconds: 30
timeoutSeconds: 1
volumes:
- name: mariadb-persistent-storage
gcePersistentDisk:
pdName: mariadb-disk
fsType: ext4
Deploymentを作ります
$ kubectl create -f mariadb-master-deployment.yml
正常に出来たかどうか確認します。
$ kubectl get pods -l app=mariadb-master
NAME READY STATUS RESTARTS AGE
mariadb-master-1674727184-ho215 1/1 Running 0 5s
つづいてサービスをつくります。
mariadb-master-service.yml
apiVersion: v1
kind: Service
metadata:
name: mariadb-master
labels:
app: mariadb-master
spec:
ports:
- port: 3306
targetPort: 3306
protocol: TCP
selector:
app: mariadb-master
$ kubectl create -f mariadb-master-service.yml
できたかどうか確認します。
$ kubectl get services mariadb-master
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
mariadb-master 10.123.240.249 3306/TCP 5s
まずはここまで
つづきはまた書きます。