利用者スタッフ の rickyだ。
今日は、機械学習アルゴリズムの一つサポートベクトルマシーン(以下、SVM)について説明していこうと思う。
このアルゴリズムは2つ以上の特徴から、それらがどんな要素に当てはまるか判別するのに長けている。
例えば、初代のいわタイプのポケモンはぼうぎょの値は高いが、とくぼうの値が低い
かくとうタイプのポケモンは、こうげきが高いが、とくこうは低い、
エスパータイプのポケモンは、とくこうが高いが、ぼうぎょは低い
と、初代ポケモンを経験したなら分かると思うが、その差は非常にピーキーであった(そ んな環境の中でも、どういうわけか編集者はカイリキーを使うのをやめなかった)。
今回の記事の内容は、もうお分かりであろう、
ポケモンのステータスの内容から、そのポケモンのタイプを予測することだ。
In[1] :
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
sns.set()
from matplotlib import rcParams
rcParams['font.family'] = 'IPAGothic'
In[2] :
pokemon = pd.read_csv("pokemon.csv")
pokemon
データ分析に必要なラベルを絞り込む。 前回のカラム絞り込みに、更に種族値合計を加えている。
In[3] :
pokemon = pokemon[['pokedex_number','name','japanese_name','type1', 'type2', \
'hp','attack','defense','sp_attack', 'sp_defense', 'speed', \
'is_legendary','generation',"base_total"]] pokemon

さて、このままデータの表示まで行きたいところだが、 このままでは、最終進化形態を含んでいるため 正確なデータが図れるとは言い難い。
例えば、 かくとうタイプのワンリキー(A:80,SA:35)と カイリキー(A:130,SA:65)は、 綺麗に初代のかくとうタイプの特徴に当てはまっているように見える。 が、その特徴値を相対量ではなく絶対量で取っているので、 他のポケモンも入ってくるということを考えると、 最終進化形態のみを評価に加えた方がよいのだ。
ここでは、CSVの中身の種族値合計が370を足きりとして それを超える初代のポケモンのみを評価に入れている。 (なお、一部中間進化形態のポケモンも入っている)
In[4] :
# 総種族値が370以上、初代のポケモンを検索
dt = pokemon[(pokemon["base_total"] > 370) & (pokemon['generation'] == 1)]
dt

ポケモンを分類するために、まずかくとうタイプかそうでないかを見分けるためにラベルを付けたい。 しかし、ポケモンはタイプを二つ併せ持っている場合がある。(CSVの中のtype1とtype2が、それだ。) そこで、type1,type2のどちらかに "fighting" を持っているものに、 新しくlabelというカラムにその真偽を追加する。 np.where(条件,True,False)は、既存のCSVカラムに新しく要素を足すのに持ってこいの機能である。 ちなみに、ここでは 1 をかくとうタイプのポケモン、0をかくとうタイプでないポケモンとしておいている。
In[5] :
#タイプ1 もしくは タイプ2がかくとうのものを絞り込み、
#新しくlabelという項目を追加する。
dt["label"] = np.where((dt["type1"] == "fighting") | (dt["type2"] == "fighting"),1,0)
dt
In[6] :
#labelが1(格闘ポケモン)を検索 fighting = dt[dt["label"] == 1] fighting
out[6]:
| pokedex_number | name | japanese_name | type1 | type2 | hp | attack | defense | sp_attack | sp_defense | speed | is_legendary | generation | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 56 | 57 | Primeape | Okorizaruオコリザル | fighting | NaN | 65 | 105 | 60 | 60 | 70 | 95 | 0 | 1 | 1 |
| 61 | 62 | Poliwrath | Nyorobonニョロボン | water | fighting | 90 | 95 | 95 | 70 | 90 | 70 | 0 | 1 | 1 |
| 66 | 67 | Machoke | Gorikyゴーリキー | fighting | NaN | 80 | 100 | 70 | 50 | 60 | 45 | 0 | 1 | 1 |
| 67 | 68 | Machamp | Kairikyカイリキー | fighting | NaN | 90 | 130 | 80 | 65 | 85 | 55 | 0 | 1 | 1 |
| 105 | 106 | Hitmonlee | Sawamularサワムラー | fighting | NaN | 50 | 120 | 53 | 35 | 110 | 87 | 0 | 1 | 1 |
| 106 | 107 | Hitmonchan | Ebiwalarエビワラー | fighting | NaN | 50 | 105 | 79 | 35 | 110 | 76 | 0 | 1 | 1 |
かくとうポケモンでないポケモンを比較対象としてかくとうポケモンの数と同数サンプリングして加える。
In[7] :
#格闘タイプ以外のポケモンから、labelが0のものを検索し、
#fightingの個数分だけサンプリングする。
other = dt[dt["label"] == 0].sample(fighting.name.count())
other
Out[7]:
| pokedex_number | name | japanese_name | type1 | type2 | hp | attack | defense | sp_attack | sp_defense | speed | is_legendary | generation | base_total | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 52 | 53 | Persian | Persianペルシアン | normal | dark | 65 | 60 | 60 | 75 | 65 | 115 | 0 | 1 | 440 | 0 |
| 37 | 38 | Ninetales | Kyukonキュウコン | fire | ice | 73 | 67 | 75 | 81 | 100 | 109 | 0 | 1 | 505 | 0 |
| 21 | 22 | Fearow | Onidrillオニドリル | normal | flying | 65 | 90 | 65 | 61 | 61 | 100 | 0 | 1 | 442 | 0 |
| 60 | 61 | Poliwhirl | Nyorozoニョロゾ | water | NaN | 65 | 65 | 65 | 50 | 50 | 90 | 0 | 1 | 385 | 0 |
| 25 | 26 | Raichu | Raichuライチュウ | electric | electric | 60 | 85 | 50 | 95 | 85 | 110 | 0 | 1 | 485 | 0 |
| 72 | 73 | Tentacruel | Dokukurageドククラゲ | water | poison | 80 | 70 | 65 | 80 | 120 | 100 | 0 | 1 | 515 |
In[8] :
#格闘タイプのポケモンのデータと、そうでないデータを結合する。
train_xy = np.vstack([ np.array(fighting.loc[:,["attack","sp_attack","label"]]), np.array(other.loc[:,["attack","sp_attack","label"]]) ])
train_xy
out[8]: array([[105, 60, 1], [ 95, 70, 1], [100, 50, 1], [130, 65, 1], [120, 35, 1], [105, 35, 1], [155, 70, 0], [ 75, 100, 0], [ 80, 135, 0], [134, 100, 0], [ 50, 115, 0], [100, 25, 0]])
In[9] :
fig, ax = plt.subplots()
ax.scatter(
x = train_xy[:,0], y = train_xy[:,1], c = ["maroon" if (i == 1) else "mediumaquamarine" for i in train_xy[:,2]], )
ax.set( title = "かくとうポケモンとその他ポケモンの、こうげき と とくこうの比較", xlabel = "こうげき", ylabel = "とくこう" )
ax.axis = "tight"
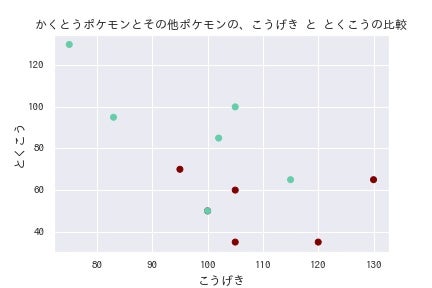
上記の図を見てみよう。 茶色の点がかくとうポケモンで、水色の点がそれ以外のポケモンである。 x軸こうげき、y軸とくこうで取っているので、 図の右下に寄っていればいるほど、それはかくとうタイプである可能性が高くなる。 これなら、うまく線形分離できるだろう。 (本当はいけないことなのだろうが、 これでも、望みのサンプリングデータが来るまで何度か繰り返したのだ。)
今回使うアルゴリズムはscikit-learnのsvmクラスを使う。
In[10] :
from sklearn import svm
In[11] :
model = svm.SVC(C = 1.0, kernel = "linear")
(追記予定)
In[12] :
model.fit(train_xy[:,:2],train_xy[:,2])
out[12]: SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0, decision_function_shape='ovr', degree=3, gamma='auto_deprecated', kernel='linear', max_iter=-1, probability=False, random_state=None, shrinking=True, tol=0.001, verbose=False)
学習したモデルの評価
In[13] :
#データを変えるために、その他のデータセットをリサンプリングする。
other = dt[dt["label"] == 0].sample(fighting.name.count())
test = pd.concat([fighting,other]) test
out[13]:
| pokedex_number | name | japanese_name | type1 | type2 | hp | attack | defense | sp_attack | sp_defense | speed | is_legendary | generation | base_total | label | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 56 | 57 | Primeape | Okorizaruオコリザル | fighting | NaN | 65 | 105 | 60 | 60 | 70 | 95 | 0 | 1 | 455 | 1 |
| 61 | 62 | Poliwrath | Nyorobonニョロボン | water | fighting | 90 | 95 | 95 | 70 | 90 | 70 | 0 | 1 | 510 | 1 |
| 66 | 67 | Machoke | Gorikyゴーリキー | fighting | NaN | 80 | 100 | 70 | 50 | 60 | 45 | 0 | 1 | 405 | 1 |
| 67 | 68 | Machamp | Kairikyカイリキー | fighting | NaN | 90 | 130 | 80 | 65 | 85 | 55 | 0 | 1 | 505 | 1 |
| 105 | 106 | Hitmonlee | Sawamularサワムラー | fighting | NaN | 50 | 120 | 53 | 35 | 110 | 87 | 0 | 1 | 455 | 1 |
| 106 | 107 | Hitmonchan | Ebiwalarエビワラー | fighting | NaN | 50 | 105 | 79 | 35 | 110 | 76 | 0 | 1 | 455 | 1 |
| 11 | 12 | Butterfree | Butterfreeバタフリー | bug | flying | 60 | 45 | 50 | 90 | 80 | 70 | 0 | 1 | 395 | 0 |
| 104 | 105 | Marowak | Garagaraガラガラ | ground | fire | 60 | 80 | 110 | 50 | 80 | 45 | 0 | 1 | 425 | 0 |
| 118 | 119 | Seaking | Azumaoアズマオウ | water | NaN | 80 | 92 | 65 | 65 | 80 | 68 | 0 | 1 | 450 | 0 |
| 142 | 143 | Snorlax | Kabigonカビゴン | normal | NaN | 160 | 110 | 65 | 65 | 110 | 30 | 0 | 1 | 540 | 0 |
| 148 | 149 | Dragonite | Kairyuカイリュー | dragon | flying | 91 | 134 | 95 | 100 | 100 | 80 | 0 | 1 | 600 | 0 |
| 70 | 71 | Victreebel | Utsubotウツボット | grass | poison | 80 | 105 | 65 | 100 | 70 | 70 | 0 | 1 | 490 | 0 |
In[14] :
test_xy = np.array([test["attack"],test["sp_attack"],test["label"]]).T
test_xy
out[14]: array([[105, 60, 1], [ 95, 70, 1], [100, 50, 1], [130, 65, 1], [120, 35, 1], [105, 35, 1], [ 45, 90, 0], [ 80, 50, 0], [ 92, 65, 0], [110, 65, 0], [134, 100, 0], [105, 100, 0]])
立てたmodelに対して、テストデータが一致するかどうか?
In[15] :
pred_y = model.predict(test_xy[:,:2])
pred_y
out[15]: array([1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0])
out[15]の出力が、予測データの結果だ。 1がかくとうで、0がかくとう以外のポケモンということを示す。 これを使ってデータがあってるかどうかをテストデータのカラムに入れてやる。
In[16] :
#予測データの成否を、結果に追加する。
test["結果"] = [(a == b) for a,b in zip(pred_y,test_xy[:,2])]
test[["japanese_name","attack","sp_attack","label","結果"]]
結果のカラムのTrueが正解で、Falseがはずれである。 上の結果から、ニョロボン以外のすべての分類に成功していることがわかる。 さて、分類アルゴリズムは、このデータをどう考えたのだろうか? それを分かりやすくするのに、図に起こしてみたい。
out[16]:
| japanese_name | attack | sp_attack | label | 結果 | |
|---|---|---|---|---|---|
| 56 | Okorizaruオ コリザル | 105 | 60 | 1 | True |
| 61 | Nyorobonニョロボン | 95 | 70 | 1 | False |
| 66 | Gorikyゴーリキー | 100 | 50 | 1 | True |
| 67 | Kairikyカイリキー | 130 | 65 | 1 | True |
| 105 | Sawamularサワムラー | 120 | 35 | 1 | True |
| 106 | Ebiwalarエビワラー | 105 | 35 | 1 | True |
| 11 | Butterfreeバタフリー | 45 | 90 | 0 | True |
| 104 | Garagaraガラガラ | 80 | 50 | 0 | True |
| 118 | Azumaoアズマオウ | 92 | 65 | 0 | True |
| 142 | Kabigonカビゴン | 110 | 65 | 0 | True |
| 148 | Kairyuカイリュー | 134 | 100 | 0 | True |
| 70 | Utsubotウツボット | 105 | 100 | 0 | True |
In[17] :
#テストデータのこうげきととくこうの最大値から、meshgridを得る
x_range = np.linspace(0,test_xy[:,0].max() * 1.1)
y_range = np.linspace(0,test_xy[:,1].max() * 1.1)
Y,X = np.meshgrid(y_range,x_range)
Y,X
In[18] :
mesh = np.vstack([X.ravel(),Y.ravel()]).T
mesh
out[18]: array([[ 0. , 0. ], [ 0. , 2.46938776], [ 0. , 4.93877551], ..., [143. , 116.06122449], [143. , 118.53061224], [143. , 121. ]])
In[19] :
#modelから、サポートベクトルの範囲を得る
P = model.decision_function(mesh).reshape(X.shape)
P
out[19]: array([[-10.98151827, -11.04736861, -11.11321895, ..., -14.07648425, -14.14233459, -14.20818493], [-10.59295113, -10.65880147, -10.72465181, ..., -13.68791711, -13.75376745, -13.81961779], [-10.20438399, -10.27023433, -10.33608467, ..., -13.29934997, -13.36520032, -13.43105066], ..., [ 7.2811373 , 7.21528696, 7.14943662, ..., 4.18617131, 4.12032097, 4.05447063], [ 7.66970444, 7.60385409, 7.53800375, ..., 4.57473845, 4.50888811, 4.44303777], [ 8.05827157, 7.99242123, 7.92657089, ..., 4.96330559, 4.89745525, 4.83160491]])
In[20] :
fig, ax = plt.subplots()
ax.scatter(
x = test_xy[:,0],y = test_xy[:,1],
c = ["maroon" if (i == 1) else "mediumaquamarine" for i in test_xy[:,2]] )
ax.contour( X,Y,P,colors=["gray","gray","gray"], levels = [-1,0,1], linestyles = ["--","-","--"] )
ax.set( title = "かくとうポケモンとその他ポケモンの、こうげき と とくこうの比較 + svm予測値", xlabel = "こうげき", ylabel = "とくこう", xlim = (test_xy[:,0].min() * 0.9,test_xy[:,0].max()), ylim = (test_xy[:,1].min() * 0.9,test_xy[:,1].max()) )
fig.axis = "tight"
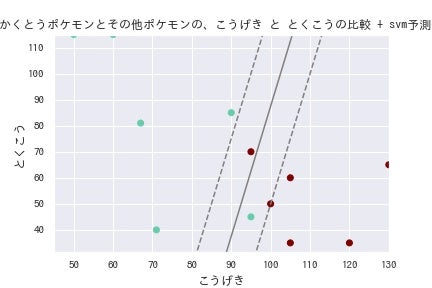
上の図が、まさにSVMがどう動いているかの種明かしだ。 50-90までの間に三本の直線と点線があるだろう。 その直線が、こうげきととくこうのステータスからタイプを分離するための基本の直線だ。 しかし、かくとうタイプの全てがこうげきが高く、とくこうが低いとは限らない。(実際 にニョロボンのデータは誤分類していた。) また、こうげきが高く、とくこうが低いポケモンだからといって必ずしもかくとうタイプとは限らない。(例をあげていてはきりがない。)
そこで、そのデータの誤差や外れ値をある程度許容するために、SVMはペナルティライン を引く。 それが直線の両端に位置する、二本の点線というわけだ。
そこでこのモデルの妥当性を検証するべく、2-4世代のデータも加えて 再度検証してみたい。(後半へ続く)