(右クリック系のツールはちょっと邪魔になるかもしれないので、一時的に切っておいたほうが良いかもしれません)
同盟ページを開いて
同盟ランク1位の人の名前を右クリック→「Firebugで要素を調査」を押してしてください。
こんな感じのが出てきたかと思います。
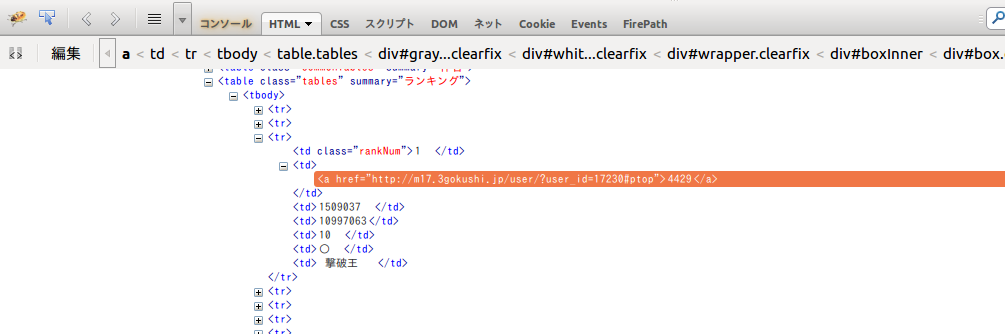
これはブラ三同盟ページのソースで、HTMLという記法で書かれています。
色が変わって選択されてる感じになっている部分が、先ほど右クリックした場所のソースです。
その色が変わってる(選択されている)行を右クリック→「FirePathパネルで調査」と行ってみてください。
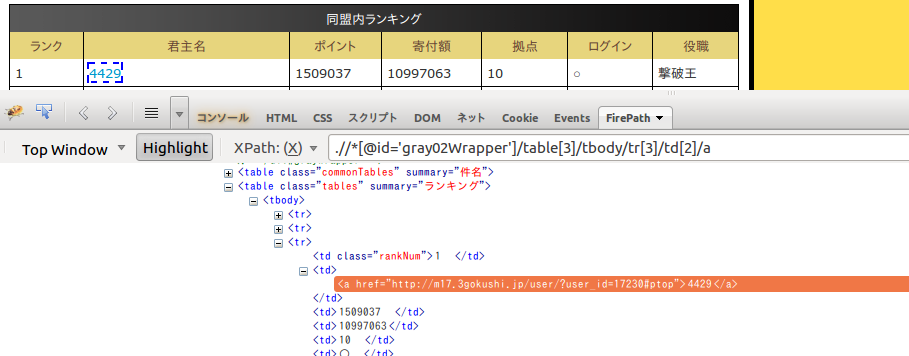
先ほど右クリックした同盟ランク1位の人の名前が青色点線の四角で囲われて
XPathのところに
.//*[@id='gray02Wrapper']/table[3]/tbody/tr[3]/td[2]/aこんなのが表示されています。
XPathはHTML文書上の住所です。
これを理解するためには、HTMLを知らなくてはいけません。
という事でHTMLの解説を少し。
HTMLではタグと呼ばれるものを使って要素を作っています。
例えば
<hoge>ほげほげ</hoge>
と書いたら、hogeタグを使って、「ほげほげ」という文字列が中身になっているhoge要素を作っています。また、タグには半角スペースで区切って「属性」ってのを入れる事ができます。
<hoge id="hogehoge">ほげほげ</hoge>
hoge要素のid属性はhogehogeで中身は「ほげほげ」という文字列です。さらに
<puri><hoge>ほげほげ</hoge></puri>
こんな感じに違う要素を中に入れることもできます。puri要素の中にhoge要素が入っていますね。
この時puri要素はhoge要素の親であると言います。
(hoge要素はpuri要素の子)
ちなみにFirebugではインデントと改行を使って見やすくしてくれています。
<puri>
<hoge>ほげほげ</hoge>
</puri>
<hoge>ほげほげ</hoge>
</puri>
子供は何人いてもいいので
<puri>
<hoge>ほげほげ</hoge>
<hage>パンチョ</hage>
<hage>おづら</hage>
<hage>あねは</hage>
</puri>
となっていることもあります。<hoge>ほげほげ</hoge>
<hage>パンチョ</hage>
<hage>おづら</hage>
<hage>あねは</hage>
</puri>
実際の例を見て行きましょう。
実際のHTMLに出てくるタグのそれぞれの意味については、現時点では分からなくても結構です。
もちろん知っていたほうが良いツールを作りやすいですが、必要になったらその時調べれば良いのです。
例えば良く使うタグにdivというのがあるのですが、
「HTML div」でググればいくらでも情報を手に入れる事ができます。
この企画中でも時々タグの解説はしますが、紹介できる数も私の知識にも限界があります。
暇なときにでもHTMLにはどんなタグがあるのかネットサーフィンしてみると良いかと思います。
さて、現在
<a href="http://m17.3gokushi.jp/user/?user_id=17230#ptop">4429</a>
が選択されています。これはa要素で、その中身が4429という文字列で、
href属性が"http://m17.3gokushi.jp/user/?user_id=17230#ptop"って事です。
さらに、このaの親がtdになっているのがお分かりいただけるでしょうか?
そして、そのtdの親はtrです。
逆の見方をすると
trの中身(子)が
<td class="rankNum">1 </td>
<td>
<a href="http://m17.3gokushi.jp/user/?user_id=17230#ptop">4429</a>
</td>
<td>1511109 </td>
<td>10997563</td>
<td>10 </td>
<td>○ </td>
<td> 撃破王 </td>
です。<td>
<a href="http://m17.3gokushi.jp/user/?user_id=17230#ptop">4429</a>
</td>
<td>1511109 </td>
<td>10997563</td>
<td>10 </td>
<td>○ </td>
<td> 撃破王 </td>
正確には
<a href="http://m17.3gokushi.jp/user/?user_id=17230#ptop">4429</a>
から見たこのtrは親ではなく、おじいさん(先祖)です。
さて今回取得したXPathは
.//*[@id='gray02Wrapper']/table[3]/tbody/tr[3]/td[2]/a
でした。
最初の.//は「何か親(先祖)がいても気にするなよ」って事です。
例えば
さいたまスーパーアリーナに手紙を出そうという時に
「埼玉県 さいたま市 中央区 新都心 8」
と書かなくても
「さいたま市 中央区 新都心 8」
でも十分届きます。
XPathの記法に置き換えると
埼玉県/さいたま市/中央区/新都心/8
を省略して
.//さいたま市/中央区/新都心/8
としているのです。
.//の次に*がついてますね。これは前にも出てきたワイルドカードです。
[@id='gray02Wrapper']はid属性がgray02Wrapperであることを意味します。
またその次の
table[3]
は3番目のtable要素って事です。
きっとHTMLが
<* id='gray02Wrapper'>
<table></table>
<table></table>
<table></table>
</*>
みたいになっていて、この3番目に目的のtableに目的の要素があるのでしょう。<table></table>
<table></table>
<table></table>
</*>
つまり
.//*[@id='gray02Wrapper']/table[3]/tbody/tr[3]/td[2]/aは
何でも良いからid属性がgray02Wrapperになってる要素の中の
3番目のtableの中の
tbodyの中の
3番目のtrの中の
2番目のtdの中の
a
という意味です。3番目のtableの中の
tbodyの中の
3番目のtrの中の
2番目のtdの中の
a
練習のために同盟ランク2位の人で同様にXPathを調べてみましょう。
.//*[@id='gray02Wrapper']/table[3]/tbody/tr[4]/td[2]/aとなりましたね?
1位の人は3番目のtrにいたのに対し
2位の人は4番目のtrにいることがわかります。
今度は逆の練習をしてみましょう。
5番目のtrを指定してみます。
XPathは
.//*[@id='gray02Wrapper']/table[3]/tbody/tr[5]/td[2]/aになります。
XPath欄を書き換えて右にあるevalボタンを押してみてください。

1位の人の時と同様に、3位の人の名前が青い点線四角で囲われ、そのソースがFirebug上で選択されていれば成功です。
少し退屈かもしれませんが、この練習は非常に重要です。
開発者の方のほとんどはHTML見ただけでFirePath無しでXPathを言い当てることができます。
皆さんもいつの日かFirePath無しでXPathを指定できるように頑張ってください。
最初は難しいかもしれません。すぐに出来るようにならなくても構いません。
今は「ふ~ん」くらいでも良いです。
徐々に腕を上げていけば良いのです。
お疲れ様でした。今回は以上です。
次回はこのXPathを使ったスクリプトでブラ三ページから情報を抜き取ってみます。
それでは本題のこちらもよろしく→
