どうもこんにちは。先日に引き続き技術本部の池田 (@yukung) です。少し日が空いてしまいましたが、 SpringOne Platform 2日目のレポートをお送りします。
他にもたくさんのセッションがありましたが、今回は私が聴講したセッションを中心にお届けします。セッション一覧はこちらです。
Main Stage
1日目と同様、冒頭は Main Stage という Keynotes セッションでした。
Keynotes 前半
主に前半は Cloud Foundry や OSS, Community の話や、ユーザーである Bloomberg, McKesson, Manulife といった企業がいかにしてソフトウェアを中心にした企業文化に変えていったのかといった culture の話、そして Cloud Foundry と Google, Microsoft, Accenture が協力関係を持ちながらどういった取り組みをしているのか、という話がありました。
個人的には Bloomberg, McKesson といった企業の企業文化の変革のエピソードは興味深く、 Bloomberg は production 環境に1日に 4000 デプロイしていたり、まずプロジェクトに CONTRIBUTE.md を作るようにして、 Pull Request を推奨するようにして社内に OSS のコントリビュート文化を取り入れるように変えていったそうです。 Mckesson は Fortune500 の5位に位置する企業ですが、彼らもまたソフトウェア中心の企業文化を強くアピールしていました。Marc Andreessen の
“ソフトウェアは世界を食う”
という言葉を引用しながら、 Uber, Facebook, Square, Twitter などのように、現在では既存のビジネスをソフトウェア中心の企業が食っていっている、コードはビジネスのために書くのだ、そしてビジネスロジックに集中し、生産性を上げろ、クリエイティビティを上げろ、そのために Spring Boot や Spring Cloud は強い味方となるだろう、という強いメッセージを発していました。"Embrace Software Driven Mindset." とも。
私が聞いていて特に感じたのは、どの企業も技術者だけではなく、ビジネスレイヤーの人たちがソフトウェアや技術に対してビジネスそのものだ、という強い意識を持っていて、ビジネスのスピードを上げるために Cloud Native や Microservices にするんだ、という考えを持って、トップダウンでそういう方向に舵を切っていっていることに驚きました。この辺りは、個人的に日本との違いを感じるところです。
Main Stage 後半
よりテクニカルな話になり、Spring 5 のロードマップや、今後出てくるであろう Java 9 との関係が話されました。 DI コンテナ内部の改善の話や、 Web アプリケーションをより効率的にする仕組みである HTTP2, Reactive Streams ベースのコントローラの導入、Lambda-oriented な HTTP ルーティングや処理の導入など、Spring Framework がより進化していくことを印象づける話でした。JDK9 については、おそらくスケジュールは遅れるものの、 Spring Framework 5.1 で JDK9 をフルサポートするそうです。
その後、 Spring5 の目玉の一つである Reactive Streams 対応についてクローズアップした話がありました。HTTP リクエストを捌くためにスケーラブルにするためのアーキテクチャモデルの変遷(古くは1リクエスト1プロセスの時代から、1リクエスト1スレッド、ロードバランサでの分散処理、そしてクラウド上での水平スケーリングへ)を前提にして、現在ではクラウド上で効率的にリソースを利用して elastic なスケーリングを実現したいはずが、現実はうまく行っていなかったり、コストが掛かってしまっているといった問題があるのではないか、という問題提起がありました。
そこで対応する一つの方法として、クラシックなサーブレットコンテナが提供する様なスレッドモデルではなく、Netty や Node.js でポピュラーとなった少ないスレッド数でも多くの処理が行えるノンブロッキングなランタイムでアプリケーションを開発することで、リソースが節約でき、より効率的にできるのではないかということでした。いわゆる C10K 問題の話ですね。
ただ、ノンブロッキングなプログラミングモデルはコールバックヘルに陥りがちで複雑になりやすいですが、Java8 で登場した java.util.concurrent.CompletionStage を使うことで宣言的に非同期処理を記述できるようになり、さらに java.util.stream.Stream を使うことでコレクションやストリームデータをうまく扱えるようになりました。ただそこに欠けていたのは、Java9 で標準化予定の Reactive Streams の仕様策定にも関わっている Doug Lea が言及した、アクティブになったデータを push スタイルの操作で、そこを補完するのが Reactive Streams である、という説明がありました。
Reactive Streams はとても小さくてシンプルな仕様で、登場するのは Publisher と Subscriber しかおらず、そこに Subscriber からのボリュームコントロールを行う Buckpressure があるだけであるということ、そしてそれらがパイプラインのようにコンポーネント間を繋いでくれるということが説明されました。
Spring5 ではこれを Project Reactor で実現しようとしています。Project Reactor では、Reactive な Data Type として Mono と Flux という型が提供され、 Mono が CompletionStage に当たるもので、Flux は Stream のように複数のストリームデータを扱うためのモデルになります。そしてこの Mono と Flux が、Spring エコシステムの中で複数のマイクロサービス間や分散データストアやメッセージブローカーを介して繋がり、全てがデータのストリームで表現できるようになる、というのが Spring5 で実現しようとしている世界である、というメッセージでした。
では具体的に Spring5 でどの辺りが変わるのかについては、以下の図がわかりやすいと思います。

Spring MVC での Controller のリクエストハンドラで、Reactive Type である Mono, Flux が引数や戻り値で扱えるようになる Spring Web Reactive が新しく提供されます。
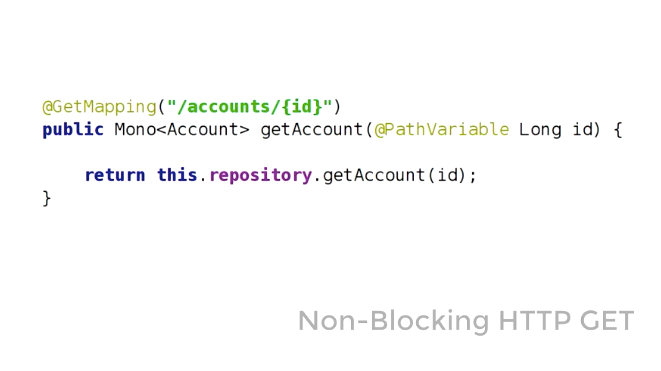

これはまた RxJava とも互換性があります。

REST API から別のエンドポイントを叩く例では以下のように記述することができます。

また、それに伴って、HTTP リクエスト/レスポンスの読み書きに Reactive な HTTP API が使われるようになり、InputStream/OutputStream が Flux や DataBuffer などで表現され、HTTP ソケットとのやりとりが Backpressure 付きで扱えるようになります。
そして、それらの基盤となるサーブレットコンテナでは、ノンブロッキング I/O が利用可能になった Servlet 3.1 Container の Tomcat/Jetty だけでなく、Java でノンブロッキング I/O の先駆けであり、サーブレットコンテナではないランタイムである Netty や、同じくノンブロッキング I/O をサポートするWebコンテナの Undertow が Spring5 でサポートされます。
最後に、Reactive Streams 対応がその他の Spring プロダクトにどういう効果をもたらすかに触れ、例で上がっていたのは Spring Cloud Stream というマイクロサービス間のメッセージングを実現するフレームワークでも、Reactive な Type で input/output を扱うことで、同様に Reactive なプログラミングモデルで記述することができるとのことでした。

後半の Technical Keynote は、Spring エコシステムがどういう方向に向かっているかということを知ることで、自ずと Reactive Streams や Microservices、分散メッセージング等の技術がどう繋がっていくのかが想像できる話で、個人的にとても得るものが多かったです。この辺りについて詳しくは
- https://spring.io/blog/2016/04/19/understanding-reactive-types
に記載されています。また日本語の資料としては @making さんの JJUG CCC 2015 Fall の資料がとても理解しやすいです。
Putting a SpEL on Spinnaker: Evolving an Expression Language for Continuous Delivery at Netflix
Spring Framework で利用できる式言語である SpEL(Spring Expression Language) を、Netflix OSS でも有名な Spinnaker で、パイプライン記述言語としてどのように使っているか、というセッションでした。 SpEL は他にはテンプレートエンジンの Thymeleaf でも使えることで知られていると思います。
Spinnaker は、マルチクラウド対応のインフラ・アプリのデプロイとクラスタ管理を実現し、継続的デリバリを自動化するソフトウェアです。Netflix は AWS のデプロイ・継続的デリバリの実現に Asgard という OSS を提供していましたが、その後継となるものです。
Spinnaker では、デプロイパイプラインを定義する際のステップの条件記述や、デプロイ単位のスタックの指定に SpEL で指定することができ、柔軟な記述が動的にできるとのことでした。動的に記述できることで記述量が減らせるので、パイプラインの定義がより気楽に行える、ということでしょうか。
また、セッション中のデモではインフラのデリバリを Jenkins のビルドパイプラインで構成して、AMI を指定して SpEL で記述されたコンフィグパラメータをインジェクションして、インスタンスの生成、テスト、Production への投入を自動化する例を実演していました。さらに SpEL の便利な使い方として、 Spinnaker では #alphanumerical や #fromUrl、#stage などのヘルパー関数を提供して、より簡単にかつパラメータチェックなども行えるようにしている、と言っていました。また、デモの中で、先日 Netflix からリリースされたマイクロサービスを可視化する Vizceral のデモをしていましたが、個人的にはこっちの方に興味を引かれてしまいましたw
Spinnaker の Pipeline Expressions のドキュメントはこちらにあるので、興味がある方はどうぞ見てみてください。
Architecting for Cloud Native Data: Data Microservices Done Right Using Spring Cloud
Data Microservices というデータに着目したマイクロサービスアーキテクチャを、Spring Cloud Data Flow と Spring Cloud Stream を使って実現するというセッションでした。
Data Microservices は、このセッションだけでなく他のセッションでも頻繁に聞かれたキーワードでしたが、このセッションで Data Microservices とはどんなものかイメージすることができました。マイクロサービスアーキテクチャと聞いてよくイメージされる、モノリシックなアプリケーションを分割したシステム的なアーキテクチャのコンセプトを、データ処理のプロセスも同じように適用します。モノリシックな1枚岩のデータ処理プロセスではなく、小さいプロセスを組み合わせることで、データを加工するプロセスをより迅速に開発し、リアルタイムにユーザに分析結果をフィードバックできるように、というのが Data Microservices のコンセプトだと思います。
コンウェイの法則で語られるように組織ごとにマイクロサービス化が進んでいっても、連携するシステムは相変わらずモノリシックだったり巨大なシステムが残り、それらを Integration Bus や ESB(Enterprise Service Bus) などで繋ぎ、ETL ミドルウェアで集約しデータ・ウェアハウスなどに蓄積するのが典型的なデータ分析のアーキテクチャですが、これは高価なソリューションであることが多く、また、夜間バッチなどで頑張って計算を行っているのが実情で、夜間バッチが遅れたりすれば分析業務にも影響が出ますし、リアルタイムな分析や機械学習は難しいという問題があります。

そこで Data Microservices では、モノリシックなデータ処理プロセスの一つ一つを分解し、それぞれをマイクロサービス化することで、迅速なデプロイや Blue-Green デプロイメントを可能にし、デリバリ速度を上げる事でデータ分析の精度を上げることができるということでした。

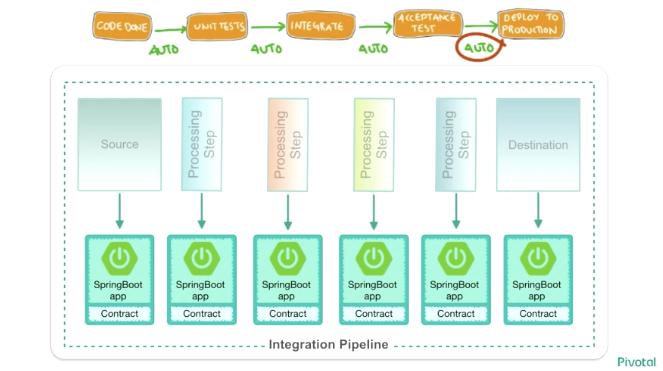
具体的には、一つ一つのデータ処理プロセスは Spring Boot のプロセスでマイクロサービス化し、それぞれのプロセス間や、メッセージキューなどの各種ミドルウェアとのメッセージングを Spring Cloud Stream で簡単に統合することができるそうです。

そしてこれらをクラウド上で実現することで、メトリクスやモニタリング、ログの集約やオートスケーリング、自動回復なども実現できるとも付け加えていました。また、データ処理パイプラインを Spring Cloud Data Flow を使って定義することで、それぞれのデータ処理プロセスをオーケストレーションすることができるようです。

ここまで説明したところで、デモとしてリアルタイムに入ってくる POS データを元にして機械学習を通して決済結果のリスク分析を行い、結果をリアルタイムにブラウザに出力するデモを披露していました。
デモ風景

デモのアーキテクチャ
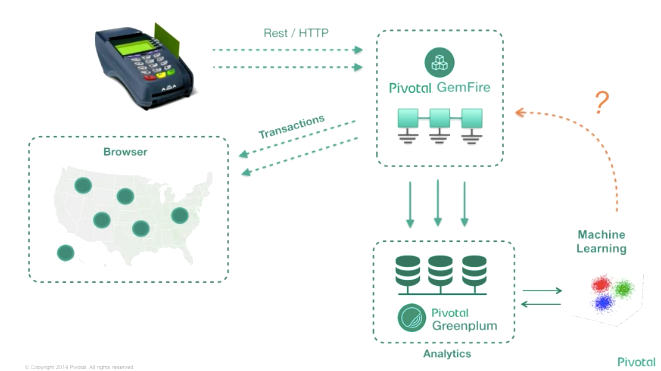
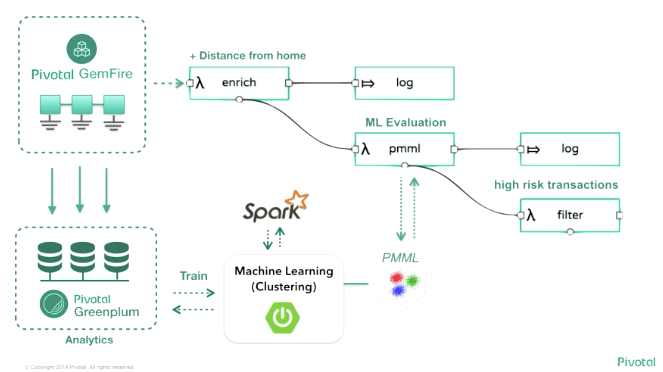
こうした Spring Cloud Stream/Spring Cloud Data Flow を使ったアーキテクチャの全体像がこちらで、Business Microservices と Data Microservices とに分けられているのが特徴的です。
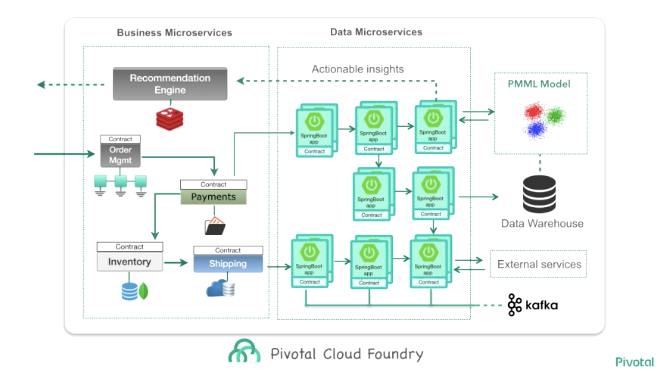
個人的にこの図を見た時に、Main Stage で紹介されていた Spring5 の Reactive Streams が目指す全てをストリームで扱える、という世界が具体的なイメージとして自分の頭の中に入ってきた感じがしました。
今回のデモはソースコードが GitHub にありますので、興味があれば是非読んでみてください。
Wall St. Derivative Risk Solutions Using Geode
ウォール街のデリバティブ取引のリスク分析に Apache Geode を使っている事例のセッションでした。が、ちょっと専門用語が多く、またスピーカーの喋り方がくぐもった声で聞き取りづらかったことで、あまり理解することができませんでした。。。そのうちセッションの動画が公開されると思うので、その際にまた見なおしてみたいと思います。Apache Geode 自体は、インメモリデータグリッドのソフトウェアで高速&スケーラブルである、ということくらいしかまだ知識がなかったのですが、セッション中で相当量のトランザクションを捌いている話をしていたと思うので、今後自分でも触ってみたいと思っています。
Cloud Native Streaming and Event-Driven Microservices
マイクロサービス間のメッセージングを行うフレームワークとしての Spring Cloud Stream の紹介と、その中身や仕組みについてコードやデモを交えて説明されていたセッションでした。上記で紹介した Data Microservices のセッションを見て、マイクロサービス間のメッセージングについてより興味が出てきていたため、Spring Cloud Stream の理解を深めるのにちょうどよいセッションでした。資料が公開されていましたので貼っておきます。
基本的には、Spring お得意のアノテーションを使って、メッセージの input/output を簡単に指定でき、具体的なメッセージングミドルウェアの実装も binder という概念で扱えるため、様々なメッセージングミドルウェアを透過的に扱える、という感じでしょうか。Spring Boot が基盤となっているため、アプリケーションを作るのも楽ちんなのが良いですね。
現在 Production Ready なミドルウェアとして、Apache Kafka や Rabbit MQ がサポートされており、Experimental ではありますが JMS や Google PubSub もサポートされているようです。他にも consumer ごとのグルーピングやパーティショニングなどもできるようです。セッションの最後に、Spring Cloud Stream 1.1 でサポートされる機能や、様々なデータソースのスキーマをバージョン管理する schema evolution の紹介や、将来的な展望も紹介されていました。
マイクロサービス化を進めていくと、この辺のメッセージングの仕組みも必要になってくると思うので、Spring Boot 同様、基盤となるソフトウェアになっていくかもしれないので、今後キャッチアップしていきたいですね。
Transforming the Monolith at 20M tph
2日目最後は、Comcast というケーブルテレビ・インターネットプロバイダの事業を行っている企業のマイクロサービス化の事例セッションを聴講しました。
内容としては、よく日本でも聞くような話でした。2億5000万/日の大規模トランザクションでかつ500台以上のサーバを抱える中で、以下の様な問題に直面したそうです。
- レガシーなコードベース
- 人手での手動オペレーション
- 物理インフラ
- ぐちゃぐちゃに混じりあったデータ
- 開発速度が出ない
これだけでもどこかで聞いた話だなぁと思うわけですがw そんな中、Comcast は一つは文化的な側面、もう一つは技術的な側面という2つのアプローチで組織を変革していったそうです。
文化的な側面では、Dev, Ops, QA それぞれの間にあった壁を壊すために、一つのチームにそれぞれの役割を含むように変え、自己組織化を促していったそうです。
技術的な側面では、マイクロサービス化を進めていくとともに、データの責務を分けて整理したこと、そしてテクノロジースタックも
- Weblogic -> CloudFoundry
- Oracle -> Couchbase
- IPベースのルーティング -> Consumer ベースのルーティング
に変えていき、CI やデプロイも
- Jenkins -> GoCD
- Maven -> Gradle
- 自作スクリプト -> Continous Delivery
というモダンなものに変えていったそうです。
そうした変化が、現在では CloudFoundry 上でゼロダウンタイムデプロイを実現するプラグインや Canary デプロイメントを実現するプラグインを開発して OSS で公開するまでになったそうで、そうした成果は GitHub で公開されています。将来的には外部サービスの影響をさらに縮小し、より多くのサービスを CloudFoundry 上に持って行きたいとのことで、これからさらにマイクロサービス化を進めていくことが印象的でした。
個人的な印象として、アメリカでは AWS や Netflix の事例がよく挙げられるために企業のマイクロサービス化が大分進んでいるのだろうという思い込みがあったのですが、このセッションの他にもいくつかセッションを聞いていく中で、アメリカでもまだまだこれからマイクロサービス化しようとしている、もしくは現在進めている、という企業が多いことを知りました。こういう感覚を現地で知ることができたことも、今回来て良かったなぁと思うところでした。
2日目の感想
全体を通して、 Microservices と Reactive Streams、Data streaming, Messaging などが強調されたセッションが多かったと思います。そしてそれらをサポートするミドルウェアとしての Kafka や Geode, 統合するフレームワークとしての Spring Cloud が今後より進化していくことが印象的でした。これらの技術要素が結びついていくことが実感として感じられたことが、今日の大きな収穫です。
ただ大分広範囲に渡って色々出てきたので、日本に帰ってからキャッチアップするものがたくさんあって大変だなぁというw あと結構2日目も一日セッションだったので大分疲れました。部屋に戻ってから寝オチしていたのは内緒です。
明日は最終日ですが、まだまだ興味深いセッションが多いので明日も頑張ってレポートしたいと思います!