整理のため、最初からやりなおしてみました。
>>>
● ワーキングディレクトリ設定
> getwd()
[1] "C:/Users/・・・・・/Documents"
> setwd("C:\\Users\\・・・・・\\Desktop\\20150509rlec")
● データ読み込み&時系列データ設定
> mydata=read.csv("完全失業率とインフレ率.csv")
> attach(mydata)
> tmydata=ts(data.frame(inflation,shitsugyo),start=c(1978),frequency=1)
● データ参照
> tmydata
Time Series:
Start = 1978
End = 2012
Frequency = 1
inflation shitsugyo
1978 0.043806647 2.2
1979 0.036179450 2.1
1980 0.078212291 2.0
1981 0.047927461 2.2
1982 0.028430161 2.4
1983 0.018028846 2.6
1984 0.023612751 2.7
1985 0.019607843 2.6
1986 0.006787330 2.8
1987 0.000000000 2.8
1988 0.007865169 2.5
1989 0.022296544 2.3
1990 0.030534351 2.1
1991 0.032804233 2.1
1992 0.017418033 2.2
1993 0.013091641 2.5
1994 0.005964215 2.9
1995 -0.000988142 3.2
1996 0.000989120 3.4
1997 0.018774704 3.4
1998 0.005819593 4.1
1999 -0.002892960 4.7
2000 -0.006769826 4.7
2001 -0.007789679 5.0
2002 -0.008832188 5.4
2003 -0.002970297 5.3
2004 0.000000000 4.7
2005 -0.002979146 4.4
2006 0.002988048 4.1
2007 0.000000000 3.9
2008 0.013902681 4.0
2009 -0.013712047 5.1
2010 -0.006951341 5.1
2011 -0.003000000 4.6
2012 0.000000000 4.3
● varsパッケージインストール&呼び出し
> install.packages("vars",rep="http://cran.ism.ac.jp")
> library(vars)
● 次数の選択
> VARselect(tmydata,lag.max=5,type="const")
$selection
AIC(n) HQ(n) SC(n) FPE(n)
2 2 1 2
$criteria
1 2 3 4 5
AIC(n) -1.200239e+01 -1.209382e+01 -1.194445e+01 -1.180444e+01 -1.165958e+01
HQ(n) -1.191274e+01 -1.194441e+01 -1.173526e+01 -1.153548e+01 -1.133086e+01
SC(n) -1.172215e+01 -1.162676e+01 -1.129055e+01 -1.096372e+01 -1.063204e+01
FPE(n) 6.137766e-06 5.629185e-06 6.609971e-06 7.761309e-06 9.276880e-06
● VARモデル推定(階差:2)
> tmydata.var<-VAR(tmydata,p=2)
> summary(tmydata.var)
VAR Estimation Results:
=========================
Endogenous variables: inflation, shitsugyo
Deterministic variables: const
Sample size: 33
Log Likelihood: 99.394
Roots of the characteristic polynomial:
0.8043 0.6651 0.4963 0.07686
Call:
VAR(y = tmydata, p = 2)
Estimation results for equation inflation:
==========================================
inflation = inflation.l1 + shitsugyo.l1 + inflation.l2 + shitsugyo.l2 + const
Estimate Std. Error t value Pr(>|t|)
inflation.l1 0.387748 0.216227 1.793 0.0837 .
shitsugyo.l1 -0.014443 0.007599 -1.901 0.0677 .
inflation.l2 0.137376 0.210434 0.653 0.5192
shitsugyo.l2 0.010039 0.007587 1.323 0.1965
const 0.020026 0.013250 1.511 0.1419
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.01227 on 28 degrees of freedom
Multiple R-Squared: 0.6237, Adjusted R-squared: 0.5699
F-statistic: 11.6 on 4 and 28 DF, p-value: 1.111e-05
Estimation results for equation shitsugyo:
==========================================
shitsugyo = inflation.l1 + shitsugyo.l1 + inflation.l2 + shitsugyo.l2 + const
Estimate Std. Error t value Pr(>|t|)
inflation.l1 7.9487 5.5850 1.423 0.16572
shitsugyo.l1 1.5011 0.1963 7.648 2.49e-08 ***
inflation.l2 -5.5434 5.4354 -1.020 0.31652
shitsugyo.l2 -0.5536 0.1960 -2.825 0.00862 **
const 0.1884 0.3422 0.551 0.58627
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3168 on 28 degrees of freedom
Multiple R-Squared: 0.9301, Adjusted R-squared: 0.9202
F-statistic: 93.2 on 4 and 28 DF, p-value: 9.248e-16
Covariance matrix of residuals:
inflation shitsugyo
inflation 0.0001504 -0.001891
shitsugyo -0.0018912 0.100373
Correlation matrix of residuals:
inflation shitsugyo
inflation 1.0000 -0.4867
shitsugyo -0.4867 1.0000
● インパルス応答関数(14期先まで・信頼区間95%)
> tmydata.irf<-irf(tmydata.var,n.ahead=14,ci=0.95)
> plot(tmydata.irf)

Hit to see next plot:

● Granger因果性検定
> causality(tmydata.var,cause="inflation")
$Granger
Granger causality H0: inflation do not Granger-cause shitsugyo
data: VAR object tmydata.var
F-Test = 1.0483, df1 = 2, df2 = 56, p-value = 0.3573
$Instant
H0: No instantaneous causality between: inflation and shitsugyo
data: VAR object tmydata.var
Chi-squared = 6.3192, df = 1, p-value = 0.01194
<<<
● tseriesパッケージインストール&呼び出し
> install.packages("tseries",rep="http://cran.ism.ac.jp")
> library(tseries)
●2回階差を取り、dtmydataに格納
dtmydata<-diff(tmydata,lag=2)
●2階階差をとった時のグラフ
> plot(dtmydata)
Hit to see next plot:

●単位根検定(インフレ率)
> adf.test(dtmydata[,1])
Augmented Dickey-Fuller Test
data: dtmydata[, 1]
Dickey-Fuller = -3.2694, Lag order = 3, p-value = 0.09338
alternative hypothesis: stationary
●単位根検定(失業率)
> adf.test(dtmydata[,2])
Augmented Dickey-Fuller Test
data: dtmydata[, 2]
Dickey-Fuller = -3.4366, Lag order = 3, p-value = 0.06941
alternative hypothesis: stationary
●単位根あり→共和分検定へ
>>>
ここまでがこれまでやったことです。
配列の順番を入れ替えただけで、インパルス応答関数のplotが全然違う形に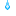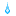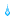
>>>
● ワーキングディレクトリ設定
> getwd()
[1] "C:/Users/・・・・・/Documents"
> setwd("C:\\Users\\・・・・・\\Desktop\\20150509rlec")
● データ読み込み&時系列データ設定
> mydata=read.csv("完全失業率とインフレ率.csv")
> attach(mydata)
> tmydata=ts(data.frame(inflation,shitsugyo),start=c(1978),frequency=1)
● データ参照
> tmydata
Time Series:
Start = 1978
End = 2012
Frequency = 1
inflation shitsugyo
1978 0.043806647 2.2
1979 0.036179450 2.1
1980 0.078212291 2.0
1981 0.047927461 2.2
1982 0.028430161 2.4
1983 0.018028846 2.6
1984 0.023612751 2.7
1985 0.019607843 2.6
1986 0.006787330 2.8
1987 0.000000000 2.8
1988 0.007865169 2.5
1989 0.022296544 2.3
1990 0.030534351 2.1
1991 0.032804233 2.1
1992 0.017418033 2.2
1993 0.013091641 2.5
1994 0.005964215 2.9
1995 -0.000988142 3.2
1996 0.000989120 3.4
1997 0.018774704 3.4
1998 0.005819593 4.1
1999 -0.002892960 4.7
2000 -0.006769826 4.7
2001 -0.007789679 5.0
2002 -0.008832188 5.4
2003 -0.002970297 5.3
2004 0.000000000 4.7
2005 -0.002979146 4.4
2006 0.002988048 4.1
2007 0.000000000 3.9
2008 0.013902681 4.0
2009 -0.013712047 5.1
2010 -0.006951341 5.1
2011 -0.003000000 4.6
2012 0.000000000 4.3
● varsパッケージインストール&呼び出し
> install.packages("vars",rep="http://cran.ism.ac.jp")
> library(vars)
● 次数の選択
> VARselect(tmydata,lag.max=5,type="const")
$selection
AIC(n) HQ(n) SC(n) FPE(n)
2 2 1 2
$criteria
1 2 3 4 5
AIC(n) -1.200239e+01 -1.209382e+01 -1.194445e+01 -1.180444e+01 -1.165958e+01
HQ(n) -1.191274e+01 -1.194441e+01 -1.173526e+01 -1.153548e+01 -1.133086e+01
SC(n) -1.172215e+01 -1.162676e+01 -1.129055e+01 -1.096372e+01 -1.063204e+01
FPE(n) 6.137766e-06 5.629185e-06 6.609971e-06 7.761309e-06 9.276880e-06
● VARモデル推定(階差:2)
> tmydata.var<-VAR(tmydata,p=2)
> summary(tmydata.var)
VAR Estimation Results:
=========================
Endogenous variables: inflation, shitsugyo
Deterministic variables: const
Sample size: 33
Log Likelihood: 99.394
Roots of the characteristic polynomial:
0.8043 0.6651 0.4963 0.07686
Call:
VAR(y = tmydata, p = 2)
Estimation results for equation inflation:
==========================================
inflation = inflation.l1 + shitsugyo.l1 + inflation.l2 + shitsugyo.l2 + const
Estimate Std. Error t value Pr(>|t|)
inflation.l1 0.387748 0.216227 1.793 0.0837 .
shitsugyo.l1 -0.014443 0.007599 -1.901 0.0677 .
inflation.l2 0.137376 0.210434 0.653 0.5192
shitsugyo.l2 0.010039 0.007587 1.323 0.1965
const 0.020026 0.013250 1.511 0.1419
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.01227 on 28 degrees of freedom
Multiple R-Squared: 0.6237, Adjusted R-squared: 0.5699
F-statistic: 11.6 on 4 and 28 DF, p-value: 1.111e-05
Estimation results for equation shitsugyo:
==========================================
shitsugyo = inflation.l1 + shitsugyo.l1 + inflation.l2 + shitsugyo.l2 + const
Estimate Std. Error t value Pr(>|t|)
inflation.l1 7.9487 5.5850 1.423 0.16572
shitsugyo.l1 1.5011 0.1963 7.648 2.49e-08 ***
inflation.l2 -5.5434 5.4354 -1.020 0.31652
shitsugyo.l2 -0.5536 0.1960 -2.825 0.00862 **
const 0.1884 0.3422 0.551 0.58627
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3168 on 28 degrees of freedom
Multiple R-Squared: 0.9301, Adjusted R-squared: 0.9202
F-statistic: 93.2 on 4 and 28 DF, p-value: 9.248e-16
Covariance matrix of residuals:
inflation shitsugyo
inflation 0.0001504 -0.001891
shitsugyo -0.0018912 0.100373
Correlation matrix of residuals:
inflation shitsugyo
inflation 1.0000 -0.4867
shitsugyo -0.4867 1.0000
● インパルス応答関数(14期先まで・信頼区間95%)
> tmydata.irf<-irf(tmydata.var,n.ahead=14,ci=0.95)
> plot(tmydata.irf)

Hit

● Granger因果性検定
> causality(tmydata.var,cause="inflation")
$Granger
Granger causality H0: inflation do not Granger-cause shitsugyo
data: VAR object tmydata.var
F-Test = 1.0483, df1 = 2, df2 = 56, p-value = 0.3573
$Instant
H0: No instantaneous causality between: inflation and shitsugyo
data: VAR object tmydata.var
Chi-squared = 6.3192, df = 1, p-value = 0.01194
<<<
● tseriesパッケージインストール&呼び出し
> install.packages("tseries",rep="http://cran.ism.ac.jp")
> library(tseries)
●2回階差を取り、dtmydataに格納
dtmydata<-diff(tmydata,lag=2)
●2階階差をとった時のグラフ
> plot(dtmydata)
Hit

●単位根検定(インフレ率)
> adf.test(dtmydata[,1])
Augmented Dickey-Fuller Test
data: dtmydata[, 1]
Dickey-Fuller = -3.2694, Lag order = 3, p-value = 0.09338
alternative hypothesis: stationary
●単位根検定(失業率)
> adf.test(dtmydata[,2])
Augmented Dickey-Fuller Test
data: dtmydata[, 2]
Dickey-Fuller = -3.4366, Lag order = 3, p-value = 0.06941
alternative hypothesis: stationary
●単位根あり→共和分検定へ
>>>
ここまでがこれまでやったことです。
配列の順番を入れ替えただけで、インパルス応答関数のplotが全然違う形に