音声入力技術は近年劇的に進歩しましたが、これほど多くの選択肢がある中で、どのAPIが最も正確性を発揮するのでしょうか?このベンチマークでは、クラウドベースのサービスを含む主要な音声認識APIをテスト・比較します。 AWS, Google Cloud, および Microsoft Azure, ASRを専門とする2つのスタートアップ: アセンブリAI および ディープグラム, オープンソース OpenAIのささやき モデル、 Googleでジェミニを検索できます, 音声入力を処理できる大規模な言語モデル.
このベンチマークでは、これらすべてのAPIをクリーン、ノイズ、アクセント付き、テクニカルといった様々な音声タイプをカバーする一連のテストを行い、実際の文字起こしタスクにどれだけ対応できるかを確認しました。目標はシンプルです:どのAPIが最も精度が高いか、そしてそれぞれがどこで苦手かを見極めることです.
音声認識ベンチマークの問題点
これほど多くの音声翻訳モデルが存在しているので、どれが最適かは明確な答えがあると考えるかもしれません。まあ、ある意味そうです。ASRに関する学術論文はたくさんありますが、主にモデルの比較でありAPIではありません。APIは内部が正確にわからないためベンチマークが難しいため、企業はいつでも更新できます. しかし、ほとんどの開発者はAPIを呼び出したいだけです, そして、ローカルでモデルを立ち上げたり実行したりすることに興味がない、ただ動くサービスを選ぶのが良いです.
オンラインでいくつか比較を見つけましたが、多くは自社の音声認識APIを販売している企業が公開しているものでした。 このブログ記事はDeepgramによるものです, 予想通り、Deepgramはすべてのカテゴリーで最もパフォーマンスが良いAPIとしてランク付けされています。これは自社製品を販売しようとする企業に期待される通りなので、真に偏りのない評価を見つけるのは難しいです.
私の場合, 私はただ、Murmurの音声認識を最高のものにしたかっただけです. リアルタイムで音声を文字起こししつつ、文法や句読点を修正する必要があるため、音声認識モデルは製品の動作を確実にするために不可欠です。私はこれらの企業とは一切関係がないため、このベンチマークは純粋に実際の性能に基づいて客観的に最良の音声入力APIを見つけるためのものです.

小さなベンチマークデータセットの作成
これらの音声入力APIを適切にベンチマークするためには、背景雑音、アクセントのあるスピーカー、専門用語など様々な条件下での性能をテストできる多様な音声クリップのコレクションが必要でした。また、多くの音声認識モデルが単文以上のフォーマットに苦労するため、句読点や大文字の評価に十分な長さを持たせたかったのです.
最初は調べてみました オープンソースデータセット. Hugging Faceには「ベンチマーク」があります "ESB:マルチドメインエンドツーエンド音声認識のベンチマーク", これは、いくつかの一般的に使われている音声認識データセットをまとめています。これは良い出発点のように思えましたが、よく調べてみると、このベンチマークとしては少し合わないと判断しました:
-
その コモンボイス データセットには多くのアクセントのある話し言葉が含まれていますが、クリップは一般的に短すぎて、10秒以下であることが多いです。そのため、APIが長い文章と句読点をどれだけうまく処理するかをテストするのが難しくなります.
-
もう一つの広く使われるデータセット, リブリスピーチ, LibriVoxからのオーディオブック録音で構成されています。パブリックドメインのコンテンツから取られているため、言語はしばしば詩的で古風であり、現代の日常会話のベンチマークにはあまり適していません.
既存のデータセットが完全に自分のニーズに合わなかったため、自分で作ることにしました。数時間かけて、さまざまなソースからの音声クリップと書き起こしを集め、正確性を手動で確認しました。各クリップは 1 2分に, 句読点や文の構造を評価するのに十分な文脈を確保すること。最終データセットには、4つの主要条件で約30分の音声が含まれていました:
-
クリーンイングリッシュスピーチ. 標準的でよく表現された話し方には、TEDトークの音声クリップを使いました。これらはネイティブの英語話者が一般的な話題について明瞭な音声で話しています。音声の質が高いので、すべてのAPIがこのカテゴリーで良好に動作すると期待しています.
-
騒がしい話し方. 現実世界の背景音をシミュレートするために、TEDトークの録音に病院の音を加えました。これは、病院やカスタマーサービスセンターなど、Voice Writerがよく使われる混雑した環境を模倣しています.
-
アクセントのある話し方. APIが英語を母語でない話者をどれだけ認識するかをテストするために、中国語とインド語のアクセントを持つ話者が朗読したWikipediaの音声を使いました。Voice Writerには世界中のさまざまな非ネイティブアクセントを持つユーザーがいるため、アクセントをうまく扱うことが非常に重要です.
-
専門的なスピーチ. 学術的・技術的な内容としては、機械学習、数学、物理学などの分野で最近発表されたarXiv論文の要旨を収集しました。その後、Eleven Labsのテキスト読み上げシステムを使って、これらの要旨の音声版を作成しました。理想的には人間の音声を使いたいですが、Eleven LabsはすべてのASRプロバイダーとは別なので、この構成がどのASRプロバイダーにも偏っていないと仮定しています.
その 投稿のビデオ版 各音声条件のサンプルが含まれています。これはASRセットアップの網羅的なテストではありません。主にVoice Writerに関連する条件に焦点を当てたため、複数話者会話や現在Voice Writerでサポートされていない非英語言語は含めていません.
テストしたモデルとAPI
このベンチマークでは、スタートアップ向けのASRモデル、クラウドプロバイダーの音声入力サービス、オープンソースモデル、音声機能を持つ大規模言語モデルを組み合わせてテストしました。これらのシステムはそれぞれ非常に高精度だと謳っていますが、実際の状況でどのように動作するかを見たかったのです。これらのサービスでは、複数のモデルから選べる場合、私は必ず最も精度が高いと宣伝されているものを選び、すべてのテストでデフォルト設定を適用しました. これらすべての試験は1月に実施されました 2025.
まずはスタートアップについてです。最も有名な音声認識スタートアップの2つは アセンブリAI および ディープグラム. 両社とも、明確なドキュメントと簡単な統合を備えたシンプルなAPIベースの文字起こしサービスを提供しています。音声ファイルをアップロードすれば、数行のコードで文字起こしが返ってくるのが可能です。Assembly AIもDeepgramも競合他社より優れていると主張しているため、このベンチマークではどちらが実際に最も優れた性能を発揮しているかが明らかになります.
次に、主要なクラウドプロバイダーについて - AWS、Google Cloud、Microsoft Azure—音声入力機能も提供しています。このベンチマークで面倒なのは、どれもセットアップのオーバーヘッドがかなり大きいことです。Assembly AIやDeepgramのように音声ファイルをアップロードして文字起こしできるのに対し、これらのサービスは多くの追加作業を必要としました。例えばAWS Transcribeでは、まずファイルをS3にアップロードし、APIを呼び出してトランスクリプトジョブを作成し、あるクラウドバケットから別のクラウドプロジェクトに出力するファイルを処理し、処理を待ってから出力S3バケットからJSON形式の文字起こしファイルをダウンロードして内容を読み取る必要があります.
GoogleやMicrosoft Azureも同様の多段階プロセスを踏襲しており、それぞれ独自の権限やアクセス制御を設定し、それらを適切に設定する必要があります(例えば、文字起こしサービスが入力クラウドバケットを読む権限を持つように)。このベンチマークの中で一番楽しくない部分でした. もしアプリケーションがすでにAWS、Google Cloud、Azureにデータを保存しているなら、これらのサービスは便利かもしれません. しかし、単にシンプルなAPIを求めているなら、Assembly AIやDeepgramの方が実装しやすいでしょう.
次に、ベンチマークを行った OpenAIのささやき モデルは、このベンチマークで唯一のオープンソース音声認識モデルです。APIベースのサービスとは異なり、Whisperは自分のハードウェア上でローカルに動かすことができます(ただし、より便利にするためにクラウドプロバイダーでも動かせます)。2つのセットアップを試しました:
-
最初に試したセットアップは ファスター・ウィスパー, GPUでもCPUでもWhisperを動かせる最適化版です。私は使いました ウィスパー・ラージV3 GPU上に搭載されています。小型のWhisperモデルはCPUで動作しますが、最大かつ最も高精度なバージョンは合理的な処理速度のためにGPUが必要です.
-
クラウドベースの方法も試しました DeepgramホストのWhisper. これはWhisper Large V2と一部の独自の前処理および後処理を組み合わせて使用しています。私のテストでは、この実装はローカルセットアップよりわずかに良い性能を示しました(ただし0.5%未満)。簡単のために、このベンチマークの残りはこのホスティング版のWhisperを使っています.
このベンチマークの最後のAPIは Googleでジェミニを検索できます. これは他のモデルとは少し異なります。専用のASRモデルではなく、音声処理が可能な大規模な言語モデルです。音声を書き起こすには、音声ファイルにテキストプロンプトを添付します。 "この音声をできるだけ正確に書き起こしてください" そしてそれをジェミニに送り、ジェミニはトランスクリプトを返します.
GeminiのようなマルチモーダルLLMは比較的新しい音声認識アプローチですが、将来的にはより多くのLLMベースのASRモデルが登場する可能性が高いです。現在、Geminiはダイレクトスピーチ入力をサポートする唯一の主流のLLMですが、OpenAIやAnthropicも近いうちに追加する可能性が高いです。このベンチマークのために、私はテストしました ジェミニ 1.5 Pro そして ジェミニ2.0フラッシュ実験 モデルはほぼ同じだったので、ベンチマークの残りは1.5 Proと仮定します.
音声認識精度の測定
音声入力モデルを評価する際には、 ワードエラー率(WER)) 主要な指標として。WERは音声認識システムが音声を文字起こしする能力を、挿入、削除、置換の3種類の誤りを正しい文字起こしの総語数と比較して数えることで測定します.
しかし、すべての誤りが同じとは限らず、特に大文字、句読点、細かな綴りの違いに関してはそうです。例えば、「2」という数字は「2」と書かれ、「color」と「colour」は地域の綴りによって異なる場合があります。これらの不整合は、たとえ技術的に正確であってもWERに影響を与える可能性があります.
これを考慮するために、私たちは 非フォーマットWER (これは句読点や大文字の除外、誤り計算の前にスペルを標準化するものです。このバージョンのWERは、単語認識に専念し、フォーマットではなく純粋に文字起こしの正確性をより明確に測定します.
例えば、次の書き起こしを考えてみましょう:
-
参考文献: “はい、その通りです。カップは2色あります.”
-
出力: “はい、その通りです。カップは2色あります.”
-
正規化: “はい、その通りです。カップは2色あります”
この場合、 非フォーマットWER 句読点、短縮形(「you're」と「you are」)、数字のフォーマット(「two」対「2」)、地域別スペル(「color」対「colours」)の違いを無視し、単語認識の正確さのみを測定します.
なぜフォーマット済みと非フォーマット型の両方を使うのですか?両方のWERバージョンは異なる文脈で有用です:
-
フォーマットされたWER (句読点と大文字付き)は、適切なフォーマットのテキストが不可欠なライティングアシスタントのような用途で重要です.
-
非フォーマットWER 音声アシスタントや機械学習パイプラインのように、テキストのフォーマットがほとんど取り除かれている用途により適しています.
これら2つのアプローチは異なる目的を果たすため、音声からテキストへの正確さの完全な全体像を示すために、両方をこのベンチマークに含めています.
結果:音声認識に最適なAPI
さて、私たちが待ち望んでいた結果についてですが、まずは各スピーチの場面を見て、全体のランキングを比較してみましょう.

クリーンスピーチ カテゴリーでは、どのモデルも比較的良好な性能を発揮し、フォーマットが不要なときはWER(労働率)が10%未満でした。しかし、フォーマットを測定すると、エラー率は全体的に約10%増加し、モデル間の違いがより顕著になりました.
このカテゴリーで最も優れた成績を収めた選手は OpenAIのささやき, フォーマット済み・非フォーマット版の両方で1位でした。ディープグラムとジェミニはウィスパーに2%以内のWERであった。アセンブリAIも生の精度は強かったですが、フォーマットに関しては苦労しました.

移転 騒がしい話し方, 全体的なパフォーマンスはわずかに低下し、クリーンスピーチカテゴリーより通常1〜2%悪化しました。一部のモデルはノイズの処理が優れていました。Whisper、Assembly AI、AWS Transcribeはノイズに対する強い耐性を示し、より良いパフォーマンスを示しました。一方で、MicrosoftとGoogle Cloud ASRはこの環境で苦戦し、常に下位にランクインしていました.
OpenAIのささやき フォーマットが必要な場合には依然として最良のモデルであり、フォーマットされていない場合にはアセンブリAIとWhisperが1位タイとなりました。ジェミニもノイズの中ではまずまず耐えましたが、トップパフォーマーほど強くはありませんでした.

スピーチの場合 非ネイティブアクセント, ランキングに大きな変化がありました. Googleでジェミニを検索できます フォーマットが必要かどうかにかかわらず、他のすべてのモデルを上回る明確な勝者となりました。Whisper、Assembly AI、AWSもこのカテゴリーでまずまずの成績を収めました。再び最下位はGoogleのクラウドASR(アセント付き音声)で平均WER(35%)という悲惨な成績を残しています.

に対して 専門的なスピーチ, 勝者は再び Googleでジェミニを検索できます, フォーマットドとアンフォーマットの両方で1位を獲得しました。ここでLLMが本当に輝くと思います。従来のASRモデルとは異なり、Geminiは専門用語の世界的な知識を持っているため、正確に書き起こすのが格段に優れています.
WhisperやAssembly AIもここで良いパフォーマンスを見せ、他のAPIを上回っています。興味深いことに、一部のモデルはクリーンスピーチよりもWERが低く、これはEleven LabsのTTS合成音声が実際の人間の録音よりもクリアだったためと考えられます.
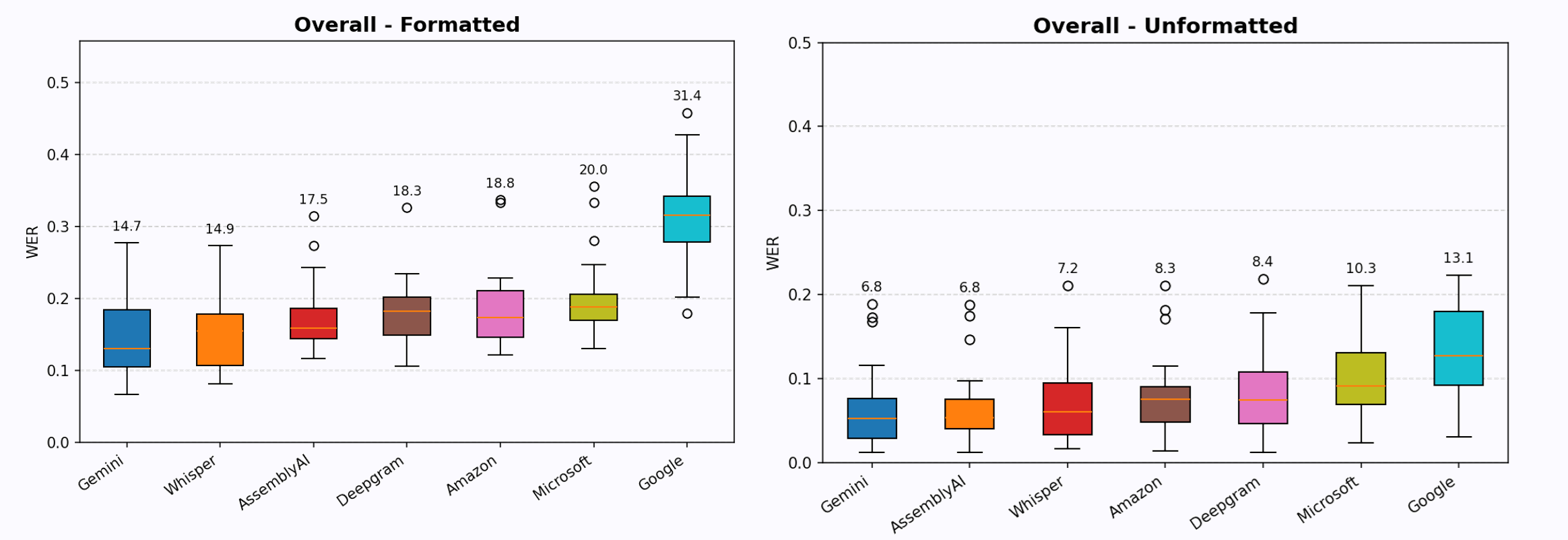
総合ランキングを見ると、WhisperとGeminiは同率で1位に並んでいます. Whisperはノイズに対する強固さで際立っており、Geminiはアクセントや技術的な話し方の扱いに優れています。ランキングは状況によって比較的一貫しており、GoogleのクラウドASRは常に最下位、Microsoft Azureは常に2番目、AWSとDeepgramは中位にとどまっています。アセンブリAIは強力で、フォーマットされていない文字起こしでは上位にランクインすることが多いですが、フォーマットにはやや苦労しています.
Googleに何が起こったのか?
このベンチマークで最大の驚きの一つは、Google Cloud ASRのパフォーマンスが非常に悪かったことです。その差があまりにも大きかったので、テストプロセスにミスがないかセットアップを再確認し、他のベンチマークも確認しました(例えば ディープグラムのベンチマーク および この学術的基準) Google Cloud ASRは常に最下位で、時にはかなりの差をつけてランク付けされることもあります。同時に、GoogleのGeminiは最高のモデルの一つです.
最も可能性の高い説明は、GoogleがGeminiに注力し、優れた人材とリソースをLLMベースのAIモデルに注ぎ、従来の音声認識サービスを軽視していることだと思います。クラウドASRモデルは停滞しているように見え、年々ますます遅れをとっています。しかし、もしこれを読んでいる方でGoogleのASRについて何か知見がある方がいれば、これが事実かどうか知りたいです.
リアルタイムストリーミング音声認識
これまでのベンチマークはバッチASRに焦点を当てており、音声ファイル全体をアップロードし、処理完了後に完全な文字起こしを受け取る仕組みです。において リアルタイムストリーミング 設定時には、APIは受信音声を短遅延(通常1〜3秒程度)で処理しつつ、高い精度を維持する必要があります。モデルはバッチモードで文の全文脈にアクセスできないため、やや精度が低いと予想されます.
私がテストしたほとんどのAPIはバッチとストリーミングASRの両方を提供していますが、Geminiだけは現在リアルタイムストリーミングをサポートしていません。GoogleとMicrosoftのバッチASRにはあまり感心しなかったので、ストリーミングAPIのテストはやめました。これで4つの候補が残りました: AWS トランスクライブ, アセンブリAI, ディープグラム, および ウィスパー・ストリーミング.
ウィスパーの状況は十分に興味深いので注目に値します。WhisperはもともとリアルタイムASR向けに設計されたわけではありませんが、コミュニティがリアルタイムストリーミングASRに対応するための巧妙なセットアップを考案しています。その一例のプロジェクトは ウィスパー・ストリーミング, これは音声をチャンク化し、段階的に書き起こします。もしこの機能について興味があれば、私には 動画はこちら 詳細に説明する。このベンチマークでは、Whisper Large V3とFaster Whisper、GPU推論を使い、すべてをデフォルト設定のままにしました.

結果はこちらです。すぐに、ストリーミングASRモデルはバッチモデルと比べて精度が明らかに低下していることが明らかです。パフォーマンスの低下が最も顕著です フォーマットが必要な場合、WERは次の方へ増加します 6-7% バッチと比べると、バッチは大幅な減少です。しかし、フォーマットが不要で生の単語認識のみを見る場合、精度の低下はかなり小さくなります 3% フォーマットが不要な場合、WER(世界基準管理)が増加します.
リアルタイムモデルの中では、AWS TranscribeとAssembly AIが最も優れたパフォーマンスを示しましたが、フォーマットが不要な場合にのみ効果がありました。これら2つのモデルはストリーミングモードで単語の認識に最も正確でしたが、句読点には苦労していました.
すべてのストリーミングASRモデルの大きな問題は句読点の扱い方です. バッチASRでは文全体を一度に処理するのに対し、リアルタイムモデルは次に何が来るか分からずに句読点を決めなければなりません。これにより、長く自然な文が複数の短い文に分割される過度な文断片化が生じます。例えば、以下は典型的な出力です(Assembly AIによるもので、この問題が最もひどいケースでしたが、すべてのモデルで程度の差はあれこの問題が発生していました):
"これが新しい法律です。しっかりした。私たちは最高の弁護士と最大のクライアントを揃えています。私たちは常にクライアントのためにパフォーマンスをし、ビジネスをしています。私たちと一緒に。これが。新しい車だ。燃費も抜群です."
ここでは、元の文字起こしが2文だけであるのに対し、モデルは8つの非常に短い文を生成しました。これは問題で、スピーカーが一瞬間を置くと、モデルがピリオドを予測すべきか、カンマを選べるか、あるいは何もしないかを判断しづらくなります。この問題のため、すべてのストリーミングモデルのフォーマットされたWER(WER)は一貫して20%を超え、バッチモードモデルよりもはるかに高かった.
しかし、句読点や大文字を無視すると、正確さははるかに合理的になりました。ストリーミングモードでのフォーマットが非常に信頼性が低いため、リアルタイム音声認識が必要なアプリケーションを作る場合, 句読点を省いて、フォーマットされていない文字起こしを使う方が良いかもしれません.
Whisper Streamingモデルはフォーマットされたテキストでは比較的優れた性能を発揮しましたが、信頼性の問題があり、本番環境での使用を推奨するのは難しいものでした。私が直面した問題のいくつかは以下の通りです:
-
句読点の不一致—2つのテストケースでは突然句読点の出力が完全に停止しました.
-
あるファイルでは、文字が抜け落ちてしまいました.
-
幻覚的なフレーズ――3つのファイルで、元の話し方にはなかったテキストがランダムに追加されました。例えば “ご視聴ありがとうございました”.
これらの問題は、Whisperがリアルタイムストリーミング向けに設計されておらず、ストリーミング実装はバッチ処理用に訓練されたモデルの上に作られた回避策に過ぎないことに起因していると考えられます。修正可能かもしれませんが、設定を調整しても解決策が見つからなかったので、Whisper Streamingを本番環境で使うのはためらわれます.
では、リアルタイムの文字起こしに最適なモデルはどれでしょうか?フォーマットが必要なら、明確な勝者はいません――どのモデルも満足できるほど性能が良くありません。ただし、生の文字起こしだけが必要な場合は, AWS トランスクライブ および アセンブリAI DeepgramやWhisper Streamingよりも正確で、フォーマットされていないテキストを扱い、句読点を別々に扱えるなら、同率で1位に並んでいます.
最終ランキング
すべてのベンチマークを終えたところで、最終ランキングをベストから最悪まで分解してみましょう。一部のモデルは一貫して強い結果を出していましたが、他は大きく遅れをとっていました.

最適なASRモデルを決める前に、まずは最悪のモデルから先に挙げましょう。間違いなく, GoogleのASRは最悪のパフォーマンスでした このベンチマークにおいて。Googleのモデルはすべてのテストで最下位となり、しばしば大きな差をつけていました。クリーンな話し方、騒がしい環境、アクセント、技術的な話し方、フォーマットされていようとなかろうと、Googleのモデルはあらゆるカテゴリーで最下位でした.
Microsoft Azure: Googleよりはやや良いですが、全体的には多くのカテゴリーで下から2番目に低い選択です。唯一意味のある場合は、あなたのデータがすでにMicrosoftのクラウドエコシステム内にある場合です.
最も優れた2つのモデルは明らかに際立っていました: OpenAIのささやき および Googleでジェミニを検索できます. この大会では統計的に1位に並んでおり、シナリオによっては必ずどちらかが1位になります。Whisperは騒がしい環境の扱いがやや優れており、Geminiはアクセントや専門用語の扱いがやや優れていますが、どちらも最先端の音声認識には優れた選択肢です.
アセンブリAI 特にフォーマットされていない音声には強い候補です。生の単語の正確さは非常に良好でしたが、句読点付きのフォーマットテキスト生成には少し苦労しました. AWS トランスクライブ および ディープグラム 群れの中間に座り、一貫した結果を出すだけでも特別ではありません。すでにAWSクラウドサービスを使っているならAWSは良い選択肢ですし、Deepgramは便利なAPIでそこそこ良いパフォーマンスを発揮します.
に対して リアルタイムストリーミングASR, 最良の選択肢は以下の通りです AWS トランスクライブ&アセンブリ AI. 両モデルとも同等の性能を発揮しましたが、フォーマットが不要な場合に限られます。しかし現時点では、リアルタイムで完璧にフォーマットされたテキストを生成するのに十分な信頼性を持つモデルはありません.
以上がこのベンチマークの終わりです。もし役に立ったなら、ぜひVoice Writerを試してみてください。最高のモデルを使ってあなたのスピーチを文字起こしするだけでなく、言葉や句読点もリアルタイムで修正してくれるので、メールやブログ記事、チャットメッセージなど、どんな文書にも簡単に貼り付けることができます。今すぐ無料で登録してください!