Murmurvtはどのようにして音声をリアルタイムで文法的に正しい文章に変換するのでしょうか?ほとんどの音声アプリはまずすべてを録音し、その後で処理します。Voice Writerは異なる仕組みで、ストリーミングASRとLLMを使って話す間に数秒未満の遅延を提供します。この記事では、低遅延、高い信頼性、そしてより良いモデルが利用可能になるたびに音声プロバイダーをシームレスに切り替えられるリアルタイムアーキテクチャについて解説します.
問題1:リアルタイム要件
既存の多くのボイスアプリはシンプルなパターンに従っています。話すと録音し、録音が終わると文字起こしが始まります。しかし、このアプローチには深刻な欠陥があると感じました。なぜなら、ユーザーが自分の録画全体が正しく処理されると信頼しなければならないからです 事後. エラー処理には深刻なリスクがあります。もしプロセスの途中で何かが失敗した場合(ネットワークエラーやモデルの過負荷など)、復旧が難しく、私たちの経験ではほとんどの場合、セッション全体が失われます。Voice Writerで10分間メールを口述しただけで、すぐに消えてしまうのは最悪の体験で、ツールを信頼することはまずないでしょう.

だからこそ、リアルタイムで転起をストリーミングする決断をしました。こうすることで、ユーザーは単語が1秒以内に認識されているのを確認し、動作しているかどうかを即座に把握できます。何か問題が起きても、少なくとも部分的な進行が見えて救うことが可能で、すべてが静かに消えてしまうわけではありません.
問題2:音声バックエンドの断片化
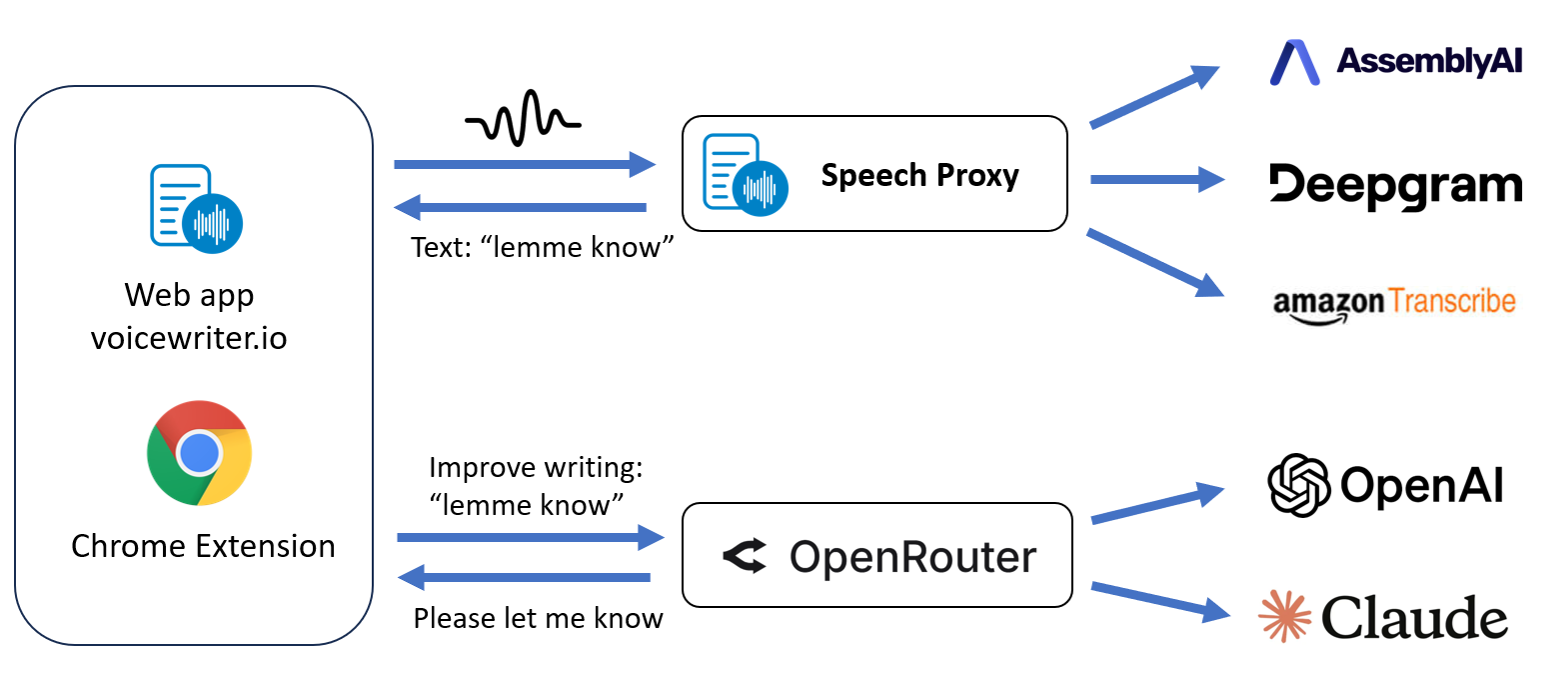
もう一つの課題は、音声提供者ごとに異なるAPIを公開しており、認証方法、入力フォーマット、オーディオコーデック、出力スキーマ(例:言語、信頼度スコア、チャネル)、部分的なトランスクリプトと最終的なトランスクリプトの処理の組み合わせが異なることです。フロントエンドのロジック(ウェブアプリやChrome拡張機能)でこれらの違いを管理するのは難しいでしょう.
さらに、 よろしく ASRモデルは常に変化しています。パフォーマンスは言語、話者のアクセント、音響条件、話題などによって異なります。私たちはこれを追跡します 私たちのベンチマーク, そして、プロバイダーがモデルを改良するにつれて、勝者は月ごとに変わります.
これに対応するために、柔軟性が必要でした。音声プロバイダーを簡単に切り替えられる機能と、フロントエンドにシンプルなインターフェースを公開できる機能――モデルIDを切り替えるだけで済みます。私たちの文法訂正LLMでは、 OpenRouter ClaudeからGeminiへの切り替えは1行で終わる抽象層として使われます。しかし音声認識(特に)においては ストリーミング ASR)にはまだOpenRouter版の同等のものはありません。だから自分たちで作ったんだ.
解決策:ストリーミングプロキシを使ったリアルタイムASR
私たちが開発した解決策は 音声プロキシサーバー それはクライアントと音声認識のバックエンドの間に位置しています。この件は次のように維持しています。 2つのアクティブなWebSocket接続: 1つはクライアント(ブラウザ)と音声プロキシ間、もう1つは音声プロキシとASRプロバイダー間です。WebSocketプロトコルはリアルタイムかつ双方向の通信を可能にします。クライアントが音声をサーバーにストリーミングし、サーバーがそれをプロバイダーに転送し、プロバイダーが部分的かつ最終的な文字起こしをJSON形式で返送します.
では、なぜプロキシサーバーを選んだのでしょうか?なぜなら、接続、セキュリティ、フォーマット互換性、プロバイダー抽象化という複数の責任を管理するレイヤーが必要だからです。プロキシは以下の主要な機能を担っています:
1. セキュア認証. ほとんどのASRプロバイダーは認証にAPIキーを必要としますが、そのキーをブラウザに公開するのは避けられ、どのユーザーでも抽出して悪用する可能性があります。代わりに、プロキシはセッションクッキーを使ってクライアントを認証し、適切なAPIキーをサーバーサイドにアタッチして、すべての秘密がフロントエンドに漏れないようにしています.
2. リアルタイムフォーマット変換. ASRプロバイダーは通常、8000Hzまたは16000Hzの16ビット署名付きPCMフォーマットの生音声を期待しています。しかし、MediaRecorder APIを使用するブラウザマイクは、Opusエンコード音声を含む圧縮WebM形式で44.1 kHzまたは48 kHzの音声をストリーミングします。プロキシはリアルタイムのオーディオデコードとリサンプリングを処理し、互換性のあるフォーマットで音声をプロバイダーにストリーミングします.
3. 統一メッセージフォーマット. 各プロバイダーには独自の特徴があります。入力オプション(モデル選択、言語コード、句読点設定など)や出力スキーマ(テキストフィールド、タイムスタンプ、信頼度スコアなど)が異なります。私たちのプロキシは、リクエストとレスポンスの両方の形式を正規化して統一されたスキーマにまとめることで、これらの違いを抽象化します。つまり、フロントエンドは裏でどの音声プロバイダーがアクティブであっても、1つのプロトコルだけを理解すればよいということです.
4. 接続管理と信頼性. プロキシはまた、複数の同時クライアントのサポート、タイムアウト管理、クライアントまたはプロバイダーがサイレントした場合の両側のクリーンシャットダウンの確保など、接続ライフサイクルロジックも処理します。ほとんどのASRプロバイダーはこれらの詳細を管理するクライアントライブラリを提供していますが、それぞれ接続の扱い方は少し異なります。代わりに、WebSocketプロトコルレベルでメッセージフォーマットを統一し、必要な接続管理ロジックをすべて自分たちで再実装する方がよりクリーンだと感じました.
部分的および最終トランスクリプト:レイテンシー最適化
ほとんどのASRプロバイダーは以下を区別しています。 部分的 および 最終記録. 部分的な文字起こしは低遅延でほぼ即座に表示されますが、音声処理が進むにつれて変わることがあります。最終成績証明書は安定しており、これ以上の変更はありません.
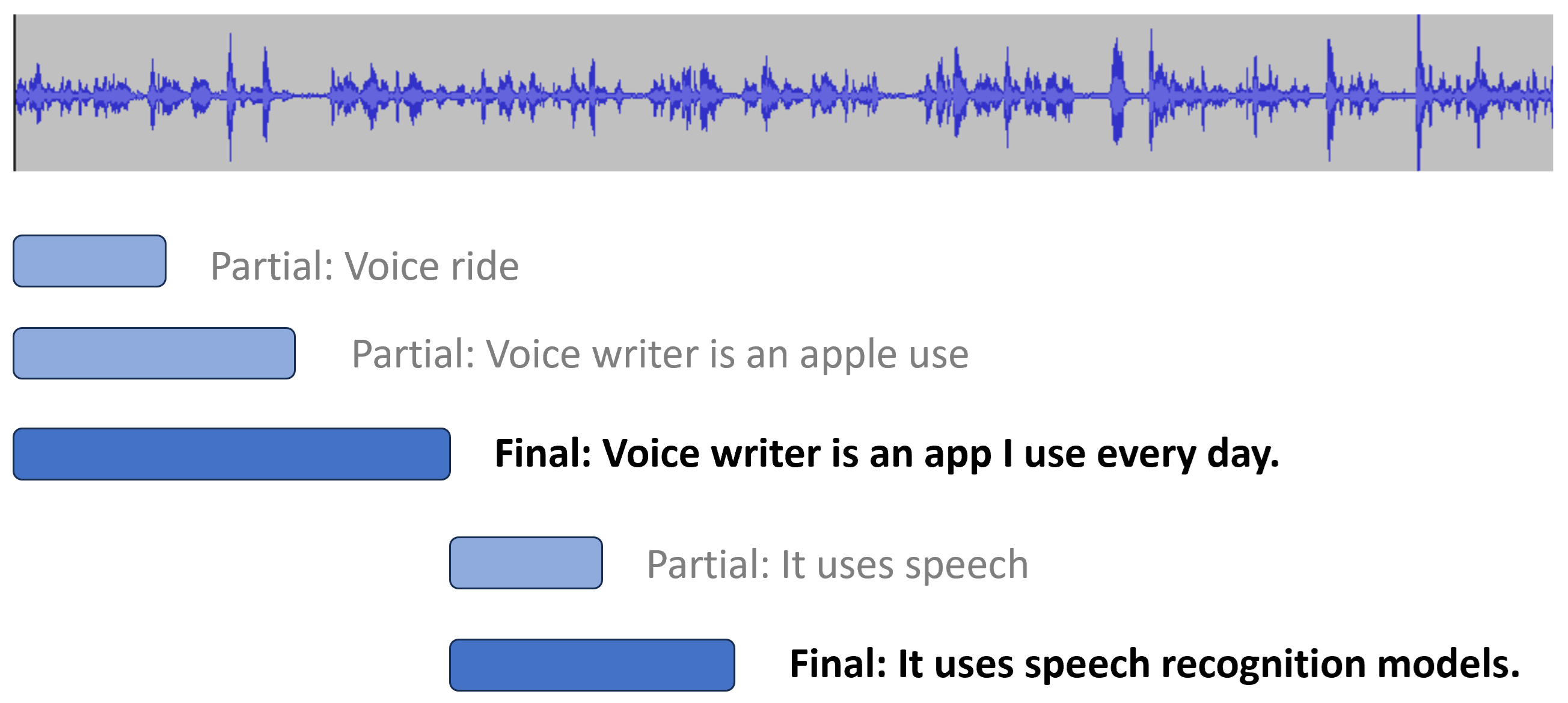
部分的なトランスクリプトを表示することで、知覚されるレイテンシーが数秒改善されます。例えば, ウィスパー・ストリーミング 部分的な書き起こしを0.5秒未満で生成でき、最終遅延は平均3〜5秒です.
一部のASRプロバイダーもサポートしています 手動最終化. 通常、最終的な転写本は静寂を検出した後(VADによる)、句読点の生成、または同じ部分的な転写本が十分に複数回生成された場合にヒューリスティックに基づいて発行されます。しかしフロントエンドのとき 知っている ユーザーが話すのをやめたとき(停止ボタンが押されたとき)、ASRプロバイダーに即時の最終処理を促し、最後のセグメントの待ち時間を短縮できます。プロバイダーがサポートするプロトコルには必ずこのルールを追加しています.
最終的な成績証明書が届くと、 文法訂正 LLM. これにより最初のトークンが届くまでに通常1〜2秒の遅延が発生し、その後、SSE(サーバー送信イベント)を介してLLMプロバイダーからフロントエンドへチャンクがストリーミングされます。幸いにも、このエコシステムのこの部分は比較的成熟しており、OpenRouterは動的に最適な稼働時間と遅延を持つLLMプロバイダーを自動的に選択します。このストリーミングパイプライン全体は遅延を最小限に抑えるよう設計されており、ユーザーは即時のフィードバックと最小限の待ち時間を得られ、書き込みフローを中断しないようにしています.

結論
音声を文法的に正しいテキストに変えるという核心的なアイデアはシンプルですが、実際にうまく機能させるには多くの思考とエンジニアリングが必要でした。私たちは、私が毎日使っている高速で堅牢なシステムを構築し、多くのユーザーがボイスライティングのニーズに頼っています。ブラウザで無料で試してみて、執筆に最適な音声モデルを体験してください.
もし興味があり、もっと知りたいなら、ぜひご連絡ください ここだ LLM、音声認識、リアルタイムAIアプリについて議論するために!