最近計測ツールのデータの特徴について考えさせられる毎日です。
代理店にいると、結構計測ツールのデータをそのまま集計・分析してレポーティングするという事をやっている場合があります。
が、「それってやっちゃっていいんだっけ?」というのが今回のお題です。
さて、計測ツールのローデータを手に入れたとしましょう。
そのデータの中には「どのidのユーザーが、何を、何時、クリック・CVしたか?」というログがひたすら並んでいます。
ちょっと単純化して図にするとこんな感じです。

赤の矢印が1回CVするまでの経路1セットで、矢印の頭の部分でCVをするとしましょう。
簡略化の為に仮にすべてのユーザーが3回CVする物と仮定します。
こういったサービス(データ生成プロセス)がある時に、利用可能なデータ期間に制約が掛かっているツールを利用してローデータを抽出すると以下の様な状態になります。
この時制約は以下の物と仮定します。(計測ツールとしては一般的な制約)
・CVしたユーザーのみのデータが手に入る
・最後のCV以降のデータは入手できない
・設定された期間内のデータしか手に入らない。
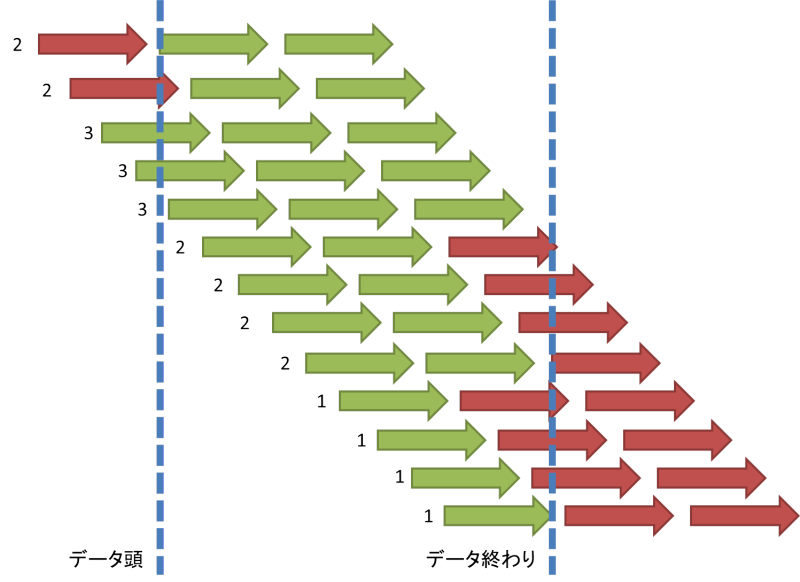
青の点線がデータの期間を示しているとします。
そして緑の⇒がデータに含まれている物、赤が含まれていないが、実際にはおきている事象となっています。
矢印の並びの左側に数字が入っていますが、そちらはデータの中でそのユーザーのCVが何回計測されているのか?という数字です。
見て貰えればわかるとおり、ユーザーは本質的には3回CVするのですが、このデータ内では多くのユーザーは3回ではなく1,2回としてカウントされており、平均約1.9回程度となっています。
なのでユーザーが1人当たり何回CVするのか?という問いに対して1.9回というバイアスのかかった回答がこのデータからは出てきてしまいます。
このバイアスの大きさは、ユーザー当たりのCVの回数とか、CVまでの時間の長さとか、データの期間によってかなり違ってきます。
仮にCVまでの長さが、データの期間とほぼ一緒だったら、データの中で計測されるユーザー当たりのCV回数はほぼ1回になってしまいます。
もしこういった結論を元に「ウチのサービスを利用するユーザーは1回CVしてしまったらもうCVしないから、CVユーザーのリタゲ意味ないね。」みたいな結論になるとミスジャッジになってしまいます。
と言ったように、データ取得の構造によって取れているデータをそのまま扱ってしまう事がバイアスを持った結論へと導くことがあります。
こういったデータに対して結構高度な分析モデルをぶつけてるケースもあってなんだかなぁと思う次第です。
取得しているデータがどの様な生成プロセスと、どの様な取得プロセスを持っているか?というのを気にすることはとても大事ですねというお話でした。