今回もインターネット広告代理店におけるデータ分析に特化したわけではなく、データマイニングの一般的な方法論を記事にします。
前回までの記事はこちらです。
主成分分析
フィッシャーの線形判別
前回も書きましたが、社内外含めて、統計学やデータマイニングの流行の波の中で、統計学やデータマイニングの講師を依頼されることがあります。私は社会に出てからデータマイニングを勉強したので、伝え方に問題ないか心配で、色々ご意見いただければ幸いです。
参考図書と記事を紹介します。
参考図書
製品開発のための統計解析学/共立出版

¥3,240
Amazon.co.jp
この本は、私が前職で製造業だったときに買った本で、式の展開がねちねち書いてあって、分かり易いやら分かりにくいやら、ともあれ、初めての1冊には良い本だと思います。
参考記事
XICA社 統計ブログ
重回帰分析を理解するために知っておきたい7つの統計用語
重回帰分析とは? ~120秒で分かる超基礎~
この記事は、とても易しい言葉で書いてありますので、概念や回帰分析での用語の理解によいと思います。
回帰分析の考え方
変数が複数ある場合に、それらの変数間に相関がある場合があります。一方の変数が増える(減る)と、他方の変数も増える(減る)という関係です。その時に、「その関係性を上手く表現できるような線(※)を引く」というのが回帰分析の考え方です。
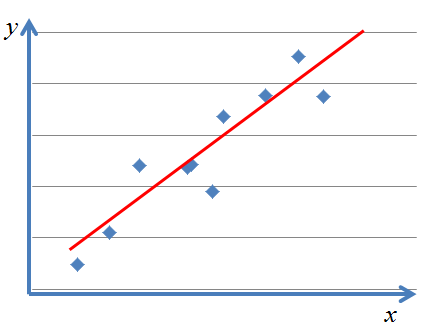
(※)変数が複数ある場合は、面や体積又は超平面になります。
また、直線を引く場合は、比例式になることがポイントですのでご了解ください。

直線は、傾き(ベータ1)と切片(ベータ0)で完全に形が決まります。ハットが付いた数値が実数値で、線の上の数値が予測値になります。
上図のように、上手く引いたとしても、予測誤差が出ます。
回帰式の予測値と実測値は次の通りです。

「誤差を最も小さくするように、直線の形状を決めよう、つまり傾き(ベータ1)と切片(ベータ1)を決めよう」というのが回帰分析の考え方になります。
補足:変数の種類について
直線の形状を決める前に、xとかyと書いていた変数について分類について補足します。
回帰分析は、上記の場合、xと元にして、yを予測するというものです。つまり、予測の元と先があります。
予測元となる変数xを説明変数、予測先となる目的変数と呼ばれています。回帰分析を行う際は、何を説明変数とし、何を目的変数とするかを定義してください。
1点注意として、説明変数を原因として、目的変数を結果とするような、因果関係を仮定する必要は必ずしもありません。
コスト関数
さて、本題に戻ります。
誤差を一番小さくするような直線の形状を決めるために、全データからの誤差の合計を書いてみます。それが下記のS(コスト関数)です。

Sは誤差そのものの合計ではなくて、2乗の合計です。これは、2乗すると、大きな数値はますます大きくなりますので、よりペナルティーが大きくなります。つまり、大きな誤差は許さないぞという考え方です。
Sはベータの値によって、大きくなったり小さくなったりするのですが、ベータを調整して、Sが一番小さくなればOKです。
そのようなベータ0と1を決めたいと思いますが、解法としては、2式目のようにSをそれらで微分してゼロ点を取ると、極小点(=最小点)のSとその時のベータが求まります。
これは、最小二乗法と呼ばれる方法です。
ベータは直線の形状を決める量でしたので、これで誤差が最小になる直線を求めることができました。
重回帰分析モデル
変数(x)が1つ以上ある場合(例えば2個)もありますので、その場合は、以下のような比例式を繋げて回帰分析を行います。重回帰分析と呼ばれる方法です。

この場合も、上記のように最小二乗法でベータ0,1,2を決めることができます。
重回帰分析での注意
以下のようなデータをあったとします。
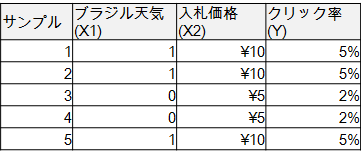
例えば、ブラジルの天気を晴れのときに1、雨のときに0としています。入札価格とクリック率はインターネット広告の変数とします。
ブラジルの天気は日本のクリック率に関係あるわけないですが、データから判断するとあるように見えます。ここから、ブラジルの天気が晴れのときに、広告出稿しましょうと判断するとまずいですが、データだけから、一切の経験を排して曇りのない心で判断すると、そうしてもよさそうです。
何かがおかしいのですが、このデータから、上記のコスト関数と微分の式を解いてみると、ベータ1,2は次の式で求められると分かります。
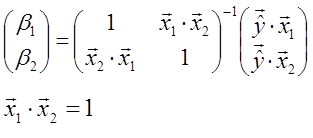
※分かり易いようにx1,2は正規化しました。
ここでベータ1,2を求めるためには、データの列をベクトルとして、x1,2の内積を求めて、それを成分とする逆行列を計算する必要があります。今、内積は1です。ベクトルで表現すると、ブラジルの天気の変化と、入札価格の変化は同じ方向を向いています。
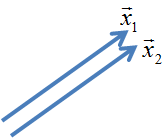
統計学の言葉では、相関が1と言い換えられます。
このとき、逆行列は、ランク落ちという現象のため、不定になります。つまり、ベータが決まりません。よって、回帰分析で、直線の形状(今の場合、平面の形状)を決めることができません。
この現象を多重共線性と言います。(マルチコと呼ばれます。)
この現象を回避するためには、以下のような方法があります。
・相関の高い変数ペアの中からどちらか1つ変数を除く。
・主成分分析を事前実施する。(主成分分析の記事)
重回帰分析をするときには、マルチコには注意してください。
線形回帰分析の拡張
上記までで、線形回帰を示してきました。しかし、実際のデータは直線的ではなくて、曲線的な場合が多いです。
例えばネット広告の場合は、投下予算と顧客獲得数は曲線的な関係になります。つまり、投下予算を増大していくと、顧客獲得の増加は低減してきます。
参考リンク
インターネット広告運用における平均CPAと限界CPA
この場合、元々の変数に変換φをしてから、通常の回帰分析をすることにより、曲線的な関係に一番誤差のない線を引くことができます。
簡単な例は、対数を取る方法です。

適宜試していただければと思います。
おわりに
今回は回帰分析の記事でした。
この方法は、ネット広告の現場のみならず、広い範囲で使える方法です。身に着けておいて損はないので、是非考え方を理解して、その後、エクセルやRなどで、実践していただければと思います。
今回は、推定された変数ベータについての検定の話しは除きました。
(ここから個人的な意見ですが、)検定をすると例えば、「直線の傾きベータ1は、ゼロではない値が出ている。しかし、偶然この数値が出た確率は、10%ある。」などと言えます。そして、まじめな統計分析者であれば、有意な判断はできない、と判断するかもしれません。
この判断は正しいですが、現場では「何も言えません、おしまい」では話しにならないので、検定ももちろん大切ですが、プロットしてみて、目視で判断する事も大切かと思います。もしくは有意差水準の基準を緩めるなどでもよいと思います。
また、もう1つ補足として、最尤法という方法を使うと、誤差分布がより広いクラスの確率分布を扱うことができます。最小二乗法は誤差が正規分布のみ対応できます。誤差が上に外れやすという場合は、最尤法でポアソン分布などを活用した回帰分析が適しています。
何れにせよ、あまり堅苦しくなく、応用する事、ビジネスに活かす事を第1に考えて使用していただければよいのではないかと思います。(あまりにも誤用はダメですが)
以上
終わり