前回までに取り扱ってきたデータは、全て線形データ(直線により分類できるデータ)でした。ところが、実世界のアプリケーションでは、むしろ非線形データを扱うことの方が多いかと思います。これまで、ご紹介してきた、パーセプトロン(Perceptron)、ロジスティック回帰(Logistic Regression)、(標準)Support Vector Machine(SVM)では、非線形データを分類することはできません。機械学習の世界では、非線形データを分類する方法として、Kernel Method( Kernel SVM、Kernel PCA、Kernel trickなど)が考案されてきました。今回は、Kernel Methodを使用しないで、多層ニューラルネットワークによって、いかに非線形データを上手く分類することができるかについて、ご紹介したいと思います。
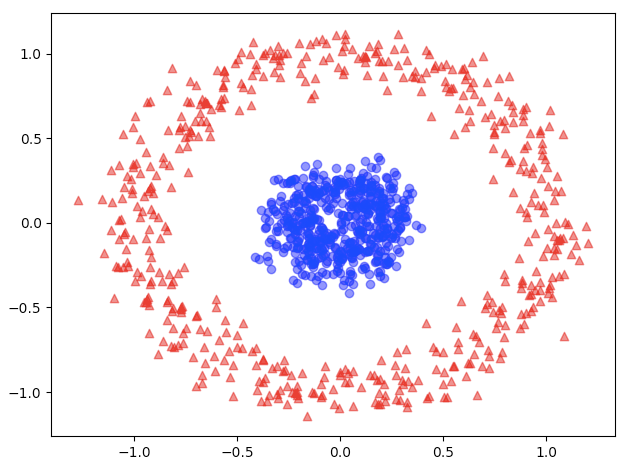
図1
TensorFlowによる多層ニューラルネットワークを使用して図1の非線形データを分類する機械学習モデルを作成します。TensorFlowによる多層ニューラルネットワークを使用した機械学習の流れは、概ね以下になります。なお、Pythonのバージョンは3.5以上を想定しています。まだ、Pythonや関連ライブラリーをまだ導入されていない方は、第2回および第13回を参考に導入してください。
- 非線形データを入力する。
- 入力データを、トレーニングデータとテストデータに分ける。
- TensorFlowにより、1層目の隠れ層(hidden layer)の最適化すべき係数(Variable)と活性化関数を定義する。
- TensorFlowにより、2層目の隠れ層(hidden layer)の最適化すべき係数(Variable)と活性化関数を定義する。
- TensorFlowにより、出力層(output layer)の最適化すべき係数(Variable)と活性化関数を定義する。
- TensorFlowにより誤差関数とその最適化法を定義する。
- TensorFlowにより精度を定義する。
- TensorFlowによりセッションを定義する。
- TensorFlowによりセッションを実行する。
- 学習結果に基づき、新データを予測分類するpredict関数を定義する。
- 分類結果および予測値を表示するためのプロット関数を定義する。
- 分類結果および予測値を図に表示する。
では、各ステップを詳しく見ていきましょう。
①非線形データを入力する。
まず、対話形式ではなく、Pythonのスクリプトをファイルで用意します。Pythonスクリプトの先頭に以下の2行を添付しておくことをお勧めします。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
|
今回は、図1の非線形データをsklean.datasetライブラリーのmake_circles関数を使用して生成して、入力データを作成します。make_circles関数によって、既にデータが標準化されているため、今回は、変量データの標準化は不要です。
from sklearn.datasets import make_circles
X, y = make_circles(n_samples=1000, random_state=123, noise=0.1, factor=0.2)
|
②入力データを、トレーニングデータとテストデータに分ける。
scikit-learning.model_selectionライブラリーのtrain_test_split関数を使用して、
変量配列Xとラベル配列yについて、トレーニングデータとテストデータに分けます。変量配列Xを、それぞれ、X_train配列, X_test配列に分割し、ラベル配列yは、y_tarin配列, y_test配列へそれぞれ分割します。test_sizeのパラメータにより、テストデータの割合を指定できます。ここでは、0.2を指定することで、テストデータの割合を全体の20%と指定しています。全1,000サンプルの20%(= 200サンプル)がテストデータで、残りの800サンプルがトレーニングデータとなります。random_state=0を指定することにより、ランダムにトレーニングデータとテストデータを分割することができます。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=0)
|
③TensorFlowにより、1段目の隠れ層(hidden layer)の最適化すべき係数(Variable)と活性化関数を定義する。
ここからが、TensorFlowの実際の記述になります。1層目の隠れ層について以下のように記述します。
import tensorflow as tf
num_units1 = 4
x = tf.placeholder(tf.float32, [None, 2])
w2 = tf.Variable(tf.truncated_normal([2, num_units1]))
b2 = tf.Variable(tf.zeros([num_units1]))
hidden1 = tf.nn.tanh(tf.matmul(x, w2) + b2)
|
num_units1は1層目の隠れ層におけるノードの数です。ここでは4を指定していますが、2以上の自然数を指定することにより、ノードの数を増やすことができます。ノードの数を増やすことにより、より複雑なモデルに対応することができますが、それに伴いより多くのコンピュータ資源が必要となります。この例では4を指定します。
TensorFlowでは、トレーニングデータを「placeholder」に格納し、機械学習により最適化すべき1層目の隠れ層の係数b2およびw2を「Variable」に格納します。ここでは、placeholderのデータの型と変量の数(ここでは2)のみを指定し、サンプルの数(ここではトレーニングデータの800)は指定しなくても構いません(ここではNoneを指定)。実際のデータ内容はセッション実行時に設定するため、ここでは指定しません。最適化すべき係数のb2の値は、0(ゼロ)に初期化しますが、w2は乱数を用いて初期値を決定しています。Net Input関数と活性化関数による1層目の隠れ層の出力としてhidden1を定義します。ここで注意すべきことは、Net Input関数も活性化関数も、必ずtensorflowライブラリーのものを使用しなければならないということです。例えば、Pythonプログラミングとしては、tf.matmul(x,w2)もnp.dot(x,w2)も全く同じ機能で計算結果も同じですが、np.dot(x,w2)を使用するとTensorFlowのセッション実行時にエラーとなるので、注意が必要です。tf.tanh関数に関しても同様で、np.tanhと指定するとセッション実行時にエラーになります。
④TensorFlowにより、2層目の隠れ層(hidden layer)の最適化すべき係数(Variable)と活性化関数を定義する。
2層目の隠れ層について以下のように記述します。
num_units2 = 6
w1 = tf.Variable(tf.truncated_normal([num_units1, num_units2]))
b1 = tf.Variable(tf.zeros([num_units2]))
hidden2 = tf.nn.tanh(tf.matmul(hidden1,w1) + b1)
|
num_units2は2層目の隠れ層におけるノードの数です。ここでは6を指定しています。機械学習により最適化すべき2層目の隠れ層の係数b1およびw1を「Variable」に格納します。w1はnum_units1 x num_units2の行列になります。最適化すべき係数のb1の値は、0(ゼロ)に初期化しますが、w1は乱数を用いて初期値を決定しています。1層目の隠れ層の出力であるhidden1を入力にしてNet Input関数と活性化関数による2層目の隠れ層の出力hidden2を定義します。
⑤TensorFlowにより、出力層(output layer)の最適化すべき係数(Variable)と活性化関数を定義する。
最適化すべき係数 w0 と b0を0(ゼロ)に初期化します。2層目の隠れ層からの出力であるhidden2の値を入力にNet Input関数を計算し、sigmoid関数で0〜1の確率に変換します。
w0 = tf.Variable(tf.zeros([num_units2, 1]))
b0 = tf.Variable(tf.zeros([1]))
p = tf.nn.sigmoid(tf.matmul(hidden2, w0) + b0)
|
⑥TensorFlowにより誤差関数とその最適化法を定義する。
トレーニングデータの分類ラベルtのデータの型と大きさ(ここでは1)をplaceholderを用いて定義します。サンプル数(ここではトレーニングデータの数)については指定は不要です(ここではNoneを指定)。また、実際のデータ内容はセッション実行時に指定するため、ここでは指定しません。
次に誤差関数を定義します。i番目のデータの分類がt=1である確率をpとすると、tでない(t=0)確率は( 1- p )となります。したがって、i番目のデータを正しく予測する確率Piは、Pi = p^t x ( 1-p)^(1-t) のように表すことができます。N個のデータ全てを正しく予測する確率は、P = P1 x P2 x ... xPN = ΠPi = Π{ p^t x ( 1-p)^(1-t) }となり、この確率Pを最大にするように係数(Variable)の w0、b0、w1、b1、w2、b2の値を最適化すれば良いことになります。これを最尤推定法(maximum likelihood method)と呼びます。したがって誤差関数としては、-Pを最小になるように定義すれば良いわけです。対数関数を使って、次のように記述できます。
loss = - log P = -log Π{ p^t x ( 1-p)^(1-t) } = -Σ{ t*log(p) + (1-t)*log(1-p) }
ここで、Σは、tesorflowライブラリーで、 reduce_sum関数が用意されています。
また、train.AdamOptimizer関数で、誤差関数 lossを最小化するよう設定しています。
t = tf.placeholder(tf.float32, [None, 1])
loss = -tf.reduce_sum(t*tf.log(p) + (1-t)*tf.log(1-p))
train_step = tf.train.AdamOptimizer().minimize(loss)
|
⑦TensorFlowにより精度を定義する。
1行目は、(p-0.5)と(t -0.5)の符号を比較することで、計算値pが元データtと一致しているかどうかを判定しています。signは符号を取り出す関数で、equalは、2つの符号が等しいかどうかを判定して、Bool値を返す関数です。correct_predictionには、データ数(ここではトレーニングデータの800個またはテストデータの200個)分の要素のBool値が格納されます。2行目では、cast関数で、correct_predictionの各要素のBool値を1,0の値に変換します。reduce_mean関数は、1,0の値に変換されたcorrect_predictionの各要素の平均値を返します。これが結局、この機械学習アルゴリズムの精度となります。
correct_prediction = tf.equal(tf.sign(p-0.5), tf.sign(t-0.5))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
|
⑧TensorFlowによりセッションを定義する。
Variable(w0, b0, w1,b1, w2, b2)の値を最適化するための、セッションを定義して、各Variableの値を初期化します。
sess = tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
|
⑨TensorFlowによりセッションを実行する。
誤差関数が最小になるよう、Variableの最適化を2,000回繰り返します。ここでは、200回繰り返すごとに、その時点での誤差関数lossとトレーニングデータの精度Accuracy(train)とテストデータの精度Accuracy(test)の値をそれぞれ計算し、表示しています。sess.runの中で、feed_dictにより、placeholderのx と t にそれぞれ、実際のデータ(変量と分類ラベル)を割り当てています。
y_matrix_train = y_train.reshape(len(y_train),1)
y_matrix_test = y_test.reshape(len(y_test),1)
i = 0
for _ in range(2000):
i += 1
sess.run(train_step, feed_dict={x:X_train, t:y_matrix_train})
if i % 200 == 0:
loss_val, acc_val = sess.run(
[loss, accuracy], feed_dict={x:X_train, t:y_matrix_train})
acc_test_val =sess.run(accuracy, feed_dict={x:X_test, t:y_matrix_test})
print ('Step: %d, Loss: %f, Accuracy(train): %f, Accuracy(test): %f'
% (i, loss_val, acc_val, acc_test_val))
|
(実行結果)
Step: 200, Loss: 483.483246, Accuracy(train): 0.747500, Accuracy(test): 0.745000
Step: 400, Loss: 365.748962, Accuracy(train): 0.866250, Accuracy(test): 0.865000
Step: 600, Loss: 218.444229, Accuracy(train): 0.945000, Accuracy(test): 0.950000
Step: 800, Loss: 115.558090, Accuracy(train): 0.998750, Accuracy(test): 0.995000
Step: 1000, Loss: 65.974106, Accuracy(train): 1.000000, Accuracy(test): 1.000000
Step: 1200, Loss: 34.156906, Accuracy(train): 1.000000, Accuracy(test): 1.000000
Step: 1400, Loss: 20.137693, Accuracy(train): 1.000000, Accuracy(test): 1.000000
Step: 1600, Loss: 13.299058, Accuracy(train): 1.000000, Accuracy(test): 1.000000
Step: 1800, Loss: 9.168139, Accuracy(train): 1.000000, Accuracy(test): 1.000000
Step: 2000, Loss: 6.563805, Accuracy(train): 1.000000, Accuracy(test): 1.000000
実行Stepが進むにつれ、誤差関数(Loss)の値は減少するとともに、トレーニングデータおよびテストデータの精度(Accuracy)の値が、それぞれ、増加して、最終的に精度が100%となり、完全に分類できていることが分かります。
次に、最終時点での係数(w0, w1, w2, b0, b1, b2)の値を取得します。
w0_val, w1_val,w2_val,b0_val,b1_val,b2_val = sess.run([w0, w1,w2,b0,b1,b2])
|
⑩学習結果に基づき、新データを予測分類するpredict関数を定義する。
学習結果の結果、最終的に得られた係数(w0, w1, w2, b0, b1,b2)の値を用いて、予測モデル predict関数を以下のように定義します。
import numpy as np
def net_input(X):
return np.dot(X,w0_val)+b0_val
def predict(X):
hidden_1 = np.tanh(np.dot(X,w2_val) + b2_val)
hidden_2 = np.tanh(np.dot(hidden_1,w1_val) + b1_val)
return np.where(1/(1+np.exp(-net_input(hidden_2))) >=0.5, 1, 0)
|
(11)分類結果および予測値を表示するためのプロット関数を定義する。
⑩で定義したpredict関数を用いて、分類結果および予測データを表示するためのplot_decision_regions関数を以下のように定義します。
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
def plot_decision_regions(X, y, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x')
colors = ('red', 'blue')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
x2_min, x2_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot class samples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=cmap(idx),
marker=markers[idx], label=cl)
|
(12)分類結果および予測値を図に表示する。
(11)で定義したplot_decision_regions関数を実行し、テストデータの分類結果を表示させます。
plot_decision_regions(X_test, y_test)
plt.legend(loc='lower left')
plt.tight_layout()
plt.show()
|

図2.
テストデータについて、完全に曲線で2つのクラスが分類されていることがわかります。このように、多層ニューラルネットワークを適用することにより、非線形データを分類することが、おわかりいただけたと思います。
なお、今回の内容は、以下の書籍の3章を参考に執筆いたしました。ご興味のある方は、ご参考いただければと思います。
「TensorFlowで学ぶディープラーニング入門 ~畳み込みニューラルネットワーク徹底解説~」
中井 悦司 (著)
出版社: マイナビ出版
全体を通してのコードは以下のようになります。なお、本コードの稼働環境は、Python3.5以上を想定しています。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sklearn.datasets import make_circles
X, y = make_circles(n_samples=1000, random_state=123, noise=0.1, factor=0.2)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=0)
import tensorflow as tf
num_units1 = 4
x = tf.placeholder(tf.float32, [None, 2])
w2 = tf.Variable(tf.truncated_normal([2, num_units1]))
b2 = tf.Variable(tf.zeros([num_units1]))
hidden1 = tf.nn.tanh(tf.matmul(x, w2) + b2)
num_units2 = 6
w1 = tf.Variable(tf.truncated_normal([num_units1, num_units2]))
b1 = tf.Variable(tf.zeros([num_units2]))
hidden2 = tf.nn.tanh(tf.matmul(hidden1,w1) + b1)
w0 = tf.Variable(tf.zeros([num_units2, 1]))
b0 = tf.Variable(tf.zeros([1]))
p = tf.nn.sigmoid(tf.matmul(hidden2, w0) + b0)
t = tf.placeholder(tf.float32, [None, 1])
loss = -tf.reduce_sum(t*tf.log(p) + (1-t)*tf.log(1-p))
train_step = tf.train.AdamOptimizer().minimize(loss)
correct_prediction = tf.equal(tf.sign(p-0.5), tf.sign(t-0.5))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
sess = tf.InteractiveSession()
sess.run(tf.initialize_all_variables())
y_matrix_train = y_train.reshape(len(y_train),1)
y_matrix_test = y_test.reshape(len(y_test),1)
i = 0
for _ in range(2000):
i += 1
sess.run(train_step, feed_dict={x:X_train, t:y_matrix_train})
if i % 200 == 0:
loss_val, acc_val = sess.run(
[loss, accuracy], feed_dict={x:X_train, t:y_matrix_train})
acc_test_val =sess.run(accuracy, feed_dict={x:X_test, t:y_matrix_test})
print ('Step: %d, Loss: %f, Accuracy(train): %f, Accuracy(test): %f'
% (i, loss_val, acc_val, acc_test_val))
w0_val, w1_val,w2_val,b0_val,b1_val,b2_val = sess.run([w0, w1,w2,b0,b1,b2])
import numpy as np
def net_input(X):
return np.dot(X,w0_val)+b0_val
def predict(X):
hidden_1 = np.tanh(np.dot(X,w2_val) + b2_val)
hidden_2 = np.tanh(np.dot(hidden_1,w1_val) + b1_val)
return np.where(1/(1+np.exp(-net_input(hidden_2))) >=0.5, 1, 0)
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
def plot_decision_regions(X, y, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x')
colors = ('red', 'blue')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
x2_min, x2_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot class samples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=cmap(idx),
marker=markers[idx], label=cl)
plot_decision_regions(X_test, y_test)
plt.legend(loc='lower left')
plt.tight_layout()
plt.show()
|