今日は、OracleにおけるSQL実行がどのような仕組みで行われているかを勉強したいと思います。
オプティマイザについて勉強しようとしたんですが、
その前にSQL実行のしくみを理解しておく必要があるようなので、先に。
オプティマイザの勉強は明日…!
もくじ
2.解析
3.最適化
4.行ソース生成
5.実行
対応するOracleドキュメントの箇所はこちら。
1.SQL実行の流れ概要
SQL文がユーザやアプリケーションから発行されると、DB側では、いくつかのプロセスを踏んだうえでそのSQLを実行する流れとなる。
SQL文の発行後、実行までの各段階は以下の通り。

プロセスを細かく見ていくと、Oracle特有の処理が行われていたりするのだが、
基本的には、一般的なプログラミング言語のコンパイルの流れ(解析→最適化→実際に実行するプログラムの生成)と、
大きく変わらないと言える。
ちなみに、一般的なコンパイルの流れは以下の通り。
※以下の画像は、応用情報技術者試験ドットコム(平成25年秋 午前 問20)の解説部分から引用させていただきました。
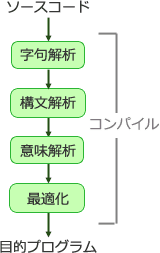
以降、OracleにおけるSQL処理の各プロセスについて、詳細を見ていく。
2.解析
まず最初のプロセスである解析は、さらに3段階に分かれる。

◎解析① 構文解析
一般的なコンパイルにおける「構文解析」と同様のチェックが行われる。
つまり、単純なスペルミスがないか、SQLの文法的に間違っていないかといったことが確認されるプロセスである。
◎解析② セマンティクス解析
「セマンティクス」とカッコつけて命名されているが、解析内容は、一般的なコンパイルにおける「意味解析」と近い。
SQLで指定されたテーブルや列などが、存在しているかを確認するプロセスとなる。
◎解析③ 共有プール解析
共有プール解析は、Oracle特有の解析である。
■そもそも、共有プールとは…
共有プールとは、SQL文その他の情報データやキャッシュを配置する場所。
メモリみたいなやつ。(物理的にも、共有プールには実メモリが利用される)
共有プールを利用することで、以下のようなメリットが得られる。
・SQL文解析のオーバーヘッドを回避
→システムのCPUリソース低減・処理速度の向上
・共有プールにデータやキャッシュが残っていれば、データ確認が完結するため、ディスク・アクセスが不要となる。
→ディスクI/Oの総数が低下(処理速度の向上)
■共有プール解析とは…
実行しようとしているSQL文と同じSQL文が、共有プール内に存在しているかをチェックすること。
過去に同じSQL文が実行されて共有プールに残っていた場合、
ユーザから発行されたSQLをさらに解析したり、実際の実行のために整理処理を重ねたりする必要がなくなる。
当然、その処理分だけ、全体としての速度向上につながり、CPUなどのリソース消費も減らすことができる。
ただ、必ずしも過去に同じSQLが実行されているかはわからないし、
実行されたとしても、古いキャッシュのため削除されている可能性もある。
そのため、発行されたSQLの解析時点で、再利用可能な同じSQLが、共有プール内にあるかを確認する必要がある。
その確認が、解析の3段階目である、「共有プール解析」となる。
共有プール解析を行うために、共有プール内に保管された各SQLには、
あらかじめハッシュ・アルゴリズムを利用したIDがつけられている。
ユーザによりSQLが発行されると、発行されたSQLをハッシュ化してIDを割り出して、
共有プール内のSQL用の領域(共有SQL領域、または、カーソル・キャッシュ)を検索し、一致するSQL IDがあるかを確認するしくみとなっている。
共有SQL領域に、一致するSQLがあるかないかで、その後の解析処理が変わってくる。
・共有SQL領域に、一致するSQL領域がなかった場合
「ハード解析」と呼ばれる解析処理が走る。
具体的には、新しい実行可能なバージョンのアプリケーション・コードを構築する処理が行われる。
・共有SQL領域に、一致する既存のSQLがあった場合
「ソフト解析」と呼ばれる解析処理となる。
ソフト解析の場合、基本的にはその後の処理が大幅に省略され、一致した既存のSQLを利用することになる。
ただし、SQLが一致していたとしても、例えば以下のようなケースの可能性もある。
Aスキーマ内の、 SELECT * FROM TESTTABLE;
Bスキーマ内の、 SELECT * FROM TESTTABLE;
このように、まったく同じSQLであっても、実際の意味としては異なる内容となっていることがある。
そのため、既存のSQL利用を最終決定する前に、
本当にSQLが一致しているかを、より精密にチェックする処理が行われる。
より精密なチェックを経てもなお、共有SQL領域にあるSQLと一致すると判断されれば、
次の「最適化」および「行ソース生成」の手順は省略される。
逆に、一致しないと判定されれば、ハード解析に強制的に切り替えられることになる。
ちなみに、SQLコードの再利用は、ライブラリ・キャッシュ・ヒットとも呼ばれる。
ここまでの共有プール解析の話をまとめると、こんな感じ。

3.最適化
Oracle Databaseによって、一意のDML文ごとに必ず1回以上のハード解析および最適化が行われる。
(具体的にどうやって最適化されているかなど、詳細はドキュメントに記載がない…(´・ω・`))
DMLは必ず最適化される一方、DDLの最適化は原則として行われない。
4.行ソース生成
一連の解析が終われば、行ソース生成手順に入る。
※そもそも、「行ソース」ってなんやねん? という問題があるが…(ドキュメント読んでもよくわからんかった。。)
この行ソースを作るための原型となるものが、明日のブログでテーマとする予定の「オプティマイザ」によって作られるらしい。
なので、行ソースとは、や、行ソースを作る仕組みの詳細は、明日改めて勉強したい。
行ソース生成は、行ソース・ジェネレータが、オプティマイザから最適なSQLの実行計画を受け取り、
反復実行計画を作成する手順となる。
簡単に言うと、SQLをDatabase上で実際に実行できる状態にする処理が行われる。
SQL実行のため、具体的にどのような動きをするのかを、OracleDBに的確に示すための手順づくりみたいな感じである。
行ソース生成により、以下のような情報を持った「行ソース・ツリー」が作られることになる。
・SQL文によって参照される表の順序
・SQL文で出てくる各表へのアクセス方法
・結合される表の結合方法
・フィルタ、ソート、集計などのデータ操作
5.実行
行ソースが生成されたら、いよいよ実行となる。
生成した行ソースを、順に実行していく。
実行中、データ取得が発生する可能性があるが、データの参照先はメモリとなる。
もしデータがメモリになければ、ディスクからメモリにデータを読み取る処理が発生する。
また、処理終了時には、データ整合性を保証するために必要なすべてのロックおよびラッチの除去と、
SQL実行時に行われたすべての変更記録が行われる。
SQL処理の流れは以上!!
ということで、行ソースがいまいちまだかみ砕けてないので、
明日引き続き勉強していきたいと思います('ω')ノ