2ヶ月前にインフルエンザとウィルス性胃腸炎でひどくダメージを受けた増田(@masudaK)です。アメーバピグは2009年2月に始まったサービスで、FLASH・Javaで作られています。そして、データストアにMySQLを用いてます。本記事では、わたくしが2年ほど見続けているアメーバピグのDB環境について構成や、日々どのようにして問題と向き合っているかを紹介したいと思います。インフラ寄りの内容が多いため、アプリ寄りの話は弊社生沼の資料を御覧ください。
1. 構成と規模
1.1. 構成
まず構成ですが、読み書きはすべてマスターへ行うようにしています。そのため、スレーブには参照を向けず、ホットスタンバイとして使っています。バージョンに関しては2012年中旬までは5.0を使ってましたが、DC移転にあわせて5.5にあげました。ロック機能を用いたシャード構成をしてまして、2014年3月現在6シャードになっています。したがって、サービスで用いている台数は12台になります。加えてバックアップ用DBサーバが一台、準本番環境用に一台あります。
この他にも下記第1図にあるように、認証用のDB、ランキング用のDB、スマホアプリ向けDBなど色々ありますが、本稿ではサービスを動かしている12台のMySQLサーバに焦点を当てます。また、現在のMySQLを使った構成に至るまでは、様々な工夫・苦労があったのですが、それは弊社桑野の資料やデブサミのレポートを見て頂ければと思います。

第一図: ピグDB環境の全体図
1.2. 規模。そしてトラフィック
総トラフィック・総参照・更新量としては約700Mbps、参照3万/秒、更新7千/秒になります。この量をマスター6台で捌いています。また、待機系も作るということになり、動作確認のために待機系を稼働させると、第二図にあるようにエリアのオンライン情報の共有をしているテーブルなどは倍のトラフィックが流れるときもあります。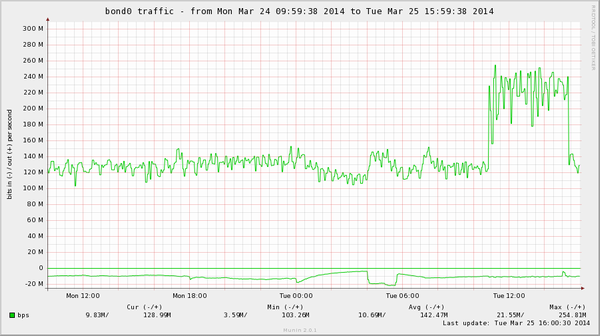
第二図: 待機系稼働時のトラフィック量
アメーバピグのDBはこれぐらいの規模で運用されているんだなという印象を持って頂ければと思います。
2. どう戦ってきたか
上述したような構成・規模で運用されているMySQLですが、運用してから色々と問題がありましたので、ここからはそれぞれの問題について、どう対応していったかを述べていきます。
2.1. クエリ調査
サービス開発をしていると、リソースが枯渇してしまうような問題が生じます。ピグはioDrive Duoを使っており、IOへの負荷よりも基本CPUへの負荷のほうが高騰しやすく、mysqldがCPUを酷使し、ロードアベレージ300超えというときもありました。
負荷が高騰して、処理が終わらないクエリが出てきているので、調査しなければなりません。そのような負荷高騰時は基本的にはshow processlistで現在実行されているSQLを見たり、スロークエリログを見て時間のかかっているSQLを特定したりするなど、まず一般的なアプローチでトラブルシューティングを行います。またそれに加え、tcpdumpでパケットキャプチャを行い、そのデータをpt-query-digestコマンドに読み込ませ、大量に発行されたSQLなどを特定したりするなどして、それらを改修してもらうということを行っています。show proceslistに関しては割愛します。pt-query-digestに関しては、出力の読み方も具体的に説明します。まず、DBサーバでパケットキャプチャをします。以下のようなコマンドを発行します。
# /usr/sbin/tcpdump -s 65535 -x -nn -q -tttt -i [INTERFACE_NAME] -c 10000 port [PORT] > /tmp/`hostname`-`date +%Y%m%d_%H%M%S`.pcap
インターフェース名やポートは各環境に合わせて変更してください。-cオプションで取得するバイト数を指定していますので、トラフィックが比較的あるサーバであれば、一瞬で終わるかと思います。そして、このpcapファイルをpt-query-digestが使える環境にSCPします。
次に、pcapファイルを解析する環境を整えます。まずそのサーバにpercona-toolkitパッケージをインストールしましょう。パッケージはPERCONAのサイトに置いてありますので、そこからダウンロードして使ってください。そして、以下のコマンドで解析を行います。
$ pt-query-digest --type tcpdump db04-20140319_203516.pcap > db04-20140319_203516.digest $ cat db04-20140319_203516.digest
そうすると以下のような形式から始まるファイルが出力されます。簡単ではありますが説明していきます。
# 4.8s user time, 70ms system time, 32.33M rss, 164.88M vsz # Current date: Wed May 22 00:25:07 2013 # Hostname: test01 # Files: db04-20140319_203516.pcap # Overall: 1.96k total, 49 unique, 917.04 QPS, 33.47x concurrency ________ # Time range: 2014-03-19 00:03:25.966159 to 00:03:28.107843 # Attribute total min max avg 95% stddev median # ============ ======= ======= ======= ======= ======= ======= ======= # Exec time 72s 0 2s 36ms 241ms 141ms 152us # Rows affecte 941 0 220 0.48 1.96 4.96 0
# Query size 238.84k 8 1.15k 124.53 329.68 154.31 76.28 # Warning coun 160.14k 0 48.75k 83.49 0 1.59k 0 # Boolean: # No index use 0% yes, 99% no
見方は難しくなく、いつからいつまでにキャプチャされたデータで、実行時間やクエリサイズの平均値・最小値・最大値という単純なものから、標準分布、中央値などの統計的な値も算出されていて、全クエリの解析結果がまず出ています。実行時間が長いものを見つけたり、クエリサイズの大きいものを見つけられるかもしません。たとえば、2秒かかってるクエリがあったというのは気に留めておいて調査をしてもよいでしょう。
次は、キャプチャ時に流れていたクエリの内訳になります。それぞれのクエリのコール数や占有している時間などが分かります。降順で並んでますので、上位5位ぐらいまで見ていくと大体怪しそうなものは見つかるでしょう。また、平常時のデータと比較することで、高負荷時にはコール数が増えていたり、時間がかかっているようであれば、目星もつけられるでしょう。
# Profile # Rank Query ID Response time Calls R/Call V/M Item # ==== ================== ============= ===== ====== ===== =============== # 1 0x19E9A02CB74CDC83 11.2006 15.6% 137 0.0818 0.68 INSERT UPDATE table1 # 2 0x51AF3D00FC8FC8BA 9.5568 13.3% 181 0.0528 0.42 SELECT table1 # 3 0x097D1EE66A7D9EEB 9.3640 13.1% 238 0.0393 0.59 SELECT table2 # 4 0xF9F96162CEE7817F 8.7675 12.2% 542 0.0162 0.61 SET # 5 0x85B0DB48178B131C 5.2483 7.3% 81 0.0648 0.51 INSERT UPDATE table3 # 6 0x6CFA293E5A09DFD5 4.2260 5.9% 40 0.1056 0.40 INSERT UPDATE table2 # 7 0xFC70D8E1CBAE0B6D 3.3443 4.7% 224 0.0149 0.33 SELECT table5 # 8 0x2D30BB0A76BC19BE 3.1292 4.4% 147 0.0213 0.22 SELECT table6 # 9 0x840399521E7FA550 3.0779 4.3% 20 0.1539 0.62 INSERT UPDATE table6 # 10 0x9F81E35658AD5D28 2.4473 3.4% 24 0.1020 0.52 SELECT table7 # 11 0x3E68A4EEC870A8E9 2.2641 3.2% 43 0.0527 0.63 SELECT table8 # 12 0x7FADBD30E1E24E40 1.7834 2.5% 54 0.0330 0.49 INSERT UPDATE table10 # 13 0x6B96B871E111AD7B 1.4353 2.0% 10 0.1435 1.10 SELECT table11 # 14 0xFBD8C9F5097ADB41 1.0718 1.5% 4 0.2679 0.52 SELECT table12 # 15 0x397C925C3827CB0F 0.9169 1.3% 7 0.1310 0.22 SELECT table13 # 16 0x6D2D77FAC9FACD66 0.6539 0.9% 37 0.0177 0.37 SELECT table14 # MISC 0xMISC 3.1911 4.5% 175 0.0182 0.0 <33 ITEMS>
次は、クエリそのものの解析です。
# Query 1: 64.81 QPS, 5.30x concurrency, ID 0x19E9A02CB74CDC83 at byte 8436064 # This item is included in the report because it matches --limit. # Scores: V/M = 0.68 # Time range: 2014-03-19 00:03:25.966932 to 00:03:28.080809 # Attribute pct total min max avg 95% stddev median # ============ === ======= ======= ======= ======= ======= ======= ======= # Count 6 137 # Exec time 15 11s 161us 1s 82ms 455ms 235ms 224us # Rows affecte 24 235 0 2 1.72 1.96 0.68 1.96 # Query size 17 42.22k 286 337 315.57 329.68 11.45 313.99 # Warning coun 0 0 0 0 0 0 0 0 # String: # Databases db04 # Error msg ****************************** # Errors 65535 # Hosts 10.200.110.89 (14/10%), 10.200.110.81 (11/8%)... 36 more # Query_time distribution # 1us # 10us # 100us ################################################################ # 1ms # # 10ms # 100ms ########### # 1s # # 10s+ # Tables # SHOW TABLE STATUS FROM `db1` LIKE 'table1'\G # SHOW CREATE TABLE `db1`.`table1`\G insert into table1 values ( _binary'********************' , _binary'\*********' ) on duplicate key update data = _binary '\0\0\0\0\0\0\0\n\0\0\0\0\0\;\G
このクエリはINSERTしているものですが、64.81qps出ています。また、同時並列数5になっていて、更新頻度も高くなっています。このようなクエリが大量に走り、IOに限界が来ていたり、行ロック待ち多発等つまりが見られるようであれば、まとめてINSERTできないかどうか、非同期でINSERTできないかどうかなどの検討もできますし、テーブルを他のシャードに移動させるということも検討できます。
このような対応は一例ではありますが、これぐらい詳細なデータがツールから得られるので、対応がしやすくなるというのが雰囲気からでも伝わって頂ければ幸いです。
このように、高負荷時のデータを平常時と比較することで、負荷の全体像を把握することができます。もちろん、binlogを集計することで更新クエリの比率などを見ることはできますが、実行時間の分布や並列処理数含めた詳細なデータが簡単に手に入るので、個人的にはこの方法を好んで使っています。
また上記の方法のみならず、ピグではDB前段にあるキャッシュにヒットしたかどうかもトレースできるように、ログからの解析も行っています。どのテーブルに対して挿入・更新したか、読み込みしたかをピグではログに残しており、ひまたぎなど一時的に負荷が高騰し、その後沈静化してしまうようなものに関しても、どのテーブルへの参照・更新が多いかを分単位でログから集計し、それをもとに対策をおこなえるようにしています。
たとえば、以下はある特定の日のDBオペレーションのログとなります。第3フィールドが「テーブル名」で、第4フィールドが「キャッシュにヒットしているかどうか」になります。これらの項目を使うことで、前日や前週と比べて、クエリが急増してないかどうか、キャッシュヒット率は下がってないかどうか等を見ることが可能となります。
14:54:00.000 1 table1 Y 01dc5468 [ServerWorker-49] 14:54:00.000 1 table2 Y 62617369635f657874725f617369616e627265657a5f686f7573655f6f725f31333033 [ServerWorker-6] 14:54:00.004 1 table3 Y 786d61735f635f636f736d657365745f626b5f31333132 [ServerWorker-35] 14:54:00.004 1 table4 N 00737b0041 [ServerWorker-49] 14:54:00.004 1 table5 Y 62617369635f657874725f6e6f6d616c5f636f636f6e7574735f747265655f31333032 [ServerWorker-6] 14:54:00.004 1 table6 Y 00af4bf6 [ServerWorker-11] 14:54:00.004 1 table7 Y 786d61735f635f636f736d656261675f626b5f31333132 [ServerWorker-35] 14:54:00.004 1 table8 Y 00af4bf6 [ServerWorker-11] 14:54:00.004 1 table9 Y 617369616e5f7461626c655f726f756e645f31303132 [ServerWorker-6]
14:54:00.004 1 table10 Y 01dc5468 [ServerWorker-49]
フォーマットも決まってますので、テーブルごとのキャッシュヒット率を出すワンライナーを一つ作っておけば、平常時と比べてどのような変化があったのかが見られます。このようにして、誰でも調査しやすい環境も整えています。
2.2. DB冗長化
DBマスターサーバは、Webサーバやアプリケーションサーバに比べると、障害時の影響が大きく、冗長化をしておかなければなりません。ピグではリリース時にホットスタンバイのサーバは用意していましたが、ホットスタンバイ構成の場合切り替えまでのタイムラグが発生するためどうしてもサービスのダウンタイムが発生してしまいます。そのためデータベースの冗長化を行うためにMHAの導入を進めました。その際、以下の様な項目を事前に検討・検証し、本番環境導入を進めました。
- ヘルスチェックの方法と間隔の検討。具体的にはSELECT 1を3秒に一回発行して確認する方法でいいのかどうか
- 様々な状況でのMHAによるフェールオーバーテスト(デーモンstop, kill -9, OSシャットダウン, FIO強制デタッチ)
- 切り替えまでの間隔の確認
ヘルスチェックの方法と間隔の検討ですが、SELECT 1を3秒に一回投げ続けるという点、そしてヘルスチェックを複数環境から行う必要があるかということを主に検討しました。SELECT 1であることはチーム内で異論は特になく、このクエリが失敗するのであれば、明らかにDBサーバとの通信で影響が出ており、アプリにも支障が出ているという点でこのヘルスチェックをデフォルトのまま採用しています。加えて、複数環境からヘルスチェックを行うかに関しては、MHAマネージャーからのヘルスチェックでエラーを返しているようであれば、アプリからの参照もうまくいっていない可能性があり、複数環境からはヘルスチェックせず、MHAマネージャーからの監視のみでよいという判断をしました。現状、1年半ほどこの方針で運用していますが、現状何も問題は起きていません。
また、ヘルスチェックが失敗する状況を再現するため、デーモンを停止させたり、kill -9コマンドでプロセスを殺したり、想定しうる様々な方法を試しました。いずれの方法を試しても、フェールオーバーが成功したので、有事の際も検知は問題なくできるだろうと判断しました。
これらをチーム内で検討し、その上で本番に準じた環境を作成し、実際にDBを落としてアプリケーションの実際の挙動の確認を行いました。その際DBCPの設定が正しくできておらず、プール内のコネクションの死活監視はしていても、すぐ切り替えられるような設定にはなっていなかった等の問題が判明したためその部分を修正し、本番に導入を行うことが出来ました。
具体的には、DBCPの「timeBetweenEvictionRunsMillis」というパラメータを用いることで定期的にプール内コネクションの状態を監視することができます。この監視を行う専用のスレッドがプール内のコネクションの有効性を確認し続けていますので、アプリは正常にコネクションを使用することができます。
また、有効性を確認できない場合はプールからそのコネクションを破棄し、正常にコネクションのみプール内に存在するように処理します。しかし、本番に準じた環境でテストした際に、その監視間隔が10分になっていたため、フェールオーバーに伴うコネクションの異常を検知できず、問題を抱えたコネクションを破棄せずに使いまわそうとしていました。
そのため、最大10分にわたって異常なコネクション(フェールオーバー前のDBに接続しようとするコネクション)を使い続けた結果、アプリ側で接続異状によるエラーログが出力され続けていました。その対応として、監視間隔を10秒にし、問題のある状態をすぐ検知し、フェールオーバー時も正常なコネクションを使用できるようにしました。
MHA導入後、本番環境でマスターがリブートし、全く応答を返さなくなったことがありましたがその際も10秒ほどでスレーブに切り替わり、ユーザの体感的には遅延程度の影響で済むレベルになっています。
2.3 データ量肥大化対応
加えて、ピグでは一日に2~3GBデータサイズが増えており、容量圧迫の対策として、pt-online-schema-changeを使い、テーブルのデフラグをしています。
以前はそこまで容量増加に関して意識を向けていなかったのですが、第3図で示したように、容量が徐々に増え、容量を圧迫し始め対策をしなければならないということになり、pt-online-schama-changeの導入を進めました。pt-online-schama-changeは弊社のサービスでも既に導入実績があったため、テスト環境での検証、途中で止めた際の挙動確認・対応などを調べ、導入をすることにしました。
以下の図は特定のDBのデータ量の増加をグラフにしたものですが、昨年の4月には使用量40-45%ぐらいだったものが、7ヶ月後の11月頃には60%近くなっています。つまり、このペースで更に1年ほど経つと、容量はほぼ使い果たしてしまい、更新することができなくなってしまいます。

第三図: DBのデータ量増加の推移
そのため、テーブルのデフラグによりひとまず容量を確保することとなりました。もちろん、そのあいだに消せないデータがないかもチームで検討を進め、デフラグと不要データ削除の方針で対応を進めていきました。
pt-online-schama-changeですが、他のチームでの導入実績が合ったとはいえ、いきなり本番マスターで実行するわけにはいきません。そのため、以下の様な項目を検証し、本番への導入を進めました。
- テスト環境での挙動確認
- 本番に準じた環境での動作確認
- 本番スレーブでの動作確認
- 本番マスターでの動作確認
テスト環境では、実際にpt-online-schama-change経由でデフラグができることの確認のみならず、途中でキャンセルした場合の挙動確認、負荷の確認を行っています。その後、本番に準じた環境で確認したのち、本番スレーブでも確認を行い、マスターと同スペックでの負荷の確認を行いました。スレーブではレプリケーションにより更新クエリも流れているため、書込み量なども参考にできます。そのような情報をもとに本番マスターでも稼働させられると判断し、実際に実行しました。また、その際もデータ量の少ないテーブルから処理をするようにし、データ量が多いテーブルへの処理はイベントなどが少ない時間に行い、ユーザへの影響を配慮した上で本番導入をしました。
以下の図が対応を入れた際のディスク容量の図です。65%ぐらいまで達していた容量が55%ぐらいに達し、その後再度実行し50%近くまで削減できています。

第四図: pt-online-schama-change実行前後のデータ量の変化
以下がデフラグ前後の容量(単位はキロバイト)の変化です。参考までにデフラグの処理にかかった時間も記しておきました。
| デフラグ前容量 | デフラグ後容量 | 差分 | 処理にかかった時間 |
|---|---|---|---|
| 2584588 | 1830920 | -753668 | 3m10.157s |
| 3338240 | 3338244 | 4 | 5m53.351s |
| 16486456 | 13889604 | -2596852 | 4m38.501s |
| 109863914 | 109342980 | -520934 | 159m31.411s |
| 125752164 | 76177972 | -49574192 | 199m27.108s |
| 1011724 | 880644 | -131080 | 1m18.705s |
| 1302536 | 1175560 | -126976 | 1m27.022s |
| 1994776 | 1884172 | -110604 | 2m18.840s |
| 2596880 | 1597448 | -999432 | 3m34.345s |
| 5361716 | 2834460 | -2527256 | 9m5.613s |
| 5435408 | 4456476 | -978932 | 9m54.702s |
| 5828640 | 3842048 | -1986592 | 9m7.552s |
| 5963844 | 2785280 | -3178564 | 6m17.178s |
| 6733900 | 5615648 | -1118252 | 5m30.092s |
| 7315492 | 6193192 | -1122300 | 10m4.802s |
| 10399860 | 6672412 | -3727448 | 9m19.385s |
| 10666028 | 7725112 | -2940916 | 6m40.966s |
| 12005504 | 9138308 | -2867196 | 29m7.796s |
| 24965368 | 6656080 | -18309288 | 13m29.364s |
| 26488912 | 26452168 | -36744 | 35m16.178s |
| 44298652 | 35119232 | -9179420 | 38m52.427s |
| 76648752 | 77013576 | 364824 | 110m15.918s |
| 107647372 | 72106488 | -35540884 | 104m58.513s |
第一表: pt-online-schama-change実行前後の各テーブルのデータ量の差異
まれにデフラグが効果的ではなく、容量が減らないテーブルもありますが、一般的には効果があるようです。30GB以上減らせるものもありましたので、ピグの場合は非常に助かりました。処理時間に関しては、容量がかなり多くても、2時間あればピグでは問題なく処理が終わってました。
また負荷に関しても、200MB/secぐらいの書き込みが発生するときもあり、通常時より数倍書き込み増えてはいましたが、ioDrive使ってることもあり、安心してコマンド発行しています。現在のところ全く問題なく使えており、ユーザ影響もないため、非常に重宝したツールとなっています。もちろん、不要なデータを削除するなどの抜本的な対策は必要ですが、長年運用しているとデータサイズは大きくなってしまうので、pt-online-schema-changeはピグには欠かせないものとなっています
終わりに
この記事ではアメーバピグにおけるDB構成と、どのように日々抱える問題と向き合ってるかについて、簡単ではありますが、述べてみました。
クエリ調査やDB冗長化などはどのサービスにでも当てはまる内容でしょうし、データ量肥大化もサービスによっては同じような状況になっているものもあるかもしれません。
いずれにしても、ピグでは様々な意見をもとに、上述したようなアプローチで本番導入を進めることができています。まだまだ不十分な点はあるかもしれませんが、少しでも参考にして頂き、問題に取り組むための判断材料にして頂ければ幸いです。不明な点等あればお問い合わせ頂ければと思います。