
・08.Google App EngineとBigQuery 導入編(1/3)
・09.Google App EngineとBigQuery 実践編(2/3)
・10.Google App EngineとBigQuery ノウハウ編(3/3)
CA Beat エンジニアリーダーのヤマサキ(@vierjp)です。
今回は、これまでに何度か触れてきたBigQueryについてです。
「02.macheでApp EngineのログをBigQueryにコピーして解析」 で
BigQueryに少しだけ触れましたが、
ログの解析に関連して示した例はBigQueryの使い方のうちのほんの一部と言っていいでしょう。
CA Beatでは元々データ解析のためにBigQueryを使い始めた経緯もあり、
データ解析の方がメインの利用目的となります。
今回から3回に渡ってまるごとBigQuery特集です。
今回App Engineと関連した話も書くつもりで、タイトルを「Google App EngineとBigQuery」としました。
しかし、基本的にはBigQueryに登録するデータソースはCSV(TSV等も可)またはjson形式なので、
Google App Engineを使っていなくても、RDBのデータをCSV形式にダンプして
BigQueryに載せれば、同様に大量データの解析が可能です。
逆にApp Engineをやっているけどデータ集計にはあまり興味が無い、という方もいるかと思いますが、
「01.Google App Engine 最近の動向」にも書いたとおり、
BigQueryの存在は今後App Engineのデータ設計に影響を与えるものになっていくと思います。
第10回記事の最後の方に「BigQueryでDatastoreのデータを解析するために考慮しておくと良いこと」を書く予定ですので、
そこだけでも見ておくと、あとあといいことあるかも?
○BigQueryの概要

BigQueryは大量のデータに対して高速にクエリを実行可能なGoogleのサービスです。
Google BigQuery — Google Developers
Publickeyから引用
SQLのクエリに対応し、3億件を超えるデータに対してインデックスを使わないフルスキャン検索で10秒以内に結果を出す。
グーグルのBigQueryは大規模なクエリを超高速で実行する能力を提供するサービスです。
グーグルは大規模クエリを実行するサービスとして社内でコードネーム「Dremel」を構築しており、2010年にそのDremelを解説する文書
「Dremel: Interactive Analysis of Web-Scale Datasets」を公開しています。
BigQueryは、そのDremelを外部公開向けに実装したものです。
ただしカラム型データストアには欠点もあります。それはデータの更新操作が苦手なこと。
Dremel/BigQueryでもこの欠点は同様であり、アップデートの操作は用意されていません。
グーグルのBigQuery、高速処理の仕組みは「カラム型データストア」と「ツリー構造」。解説文書が公開 - Publickey
Google佐藤さんの書かれた解説文書(ホワイトペーパー)はこちら。
An Inside Look at Google BigQuery (PDF)
私もまだ読んでいる途中なのですが、
BigQueryの説明に加えてMap Reduceとの比較もしているとても興味深い内容です。
大規模なデータに対する集計クエリを実行してもすぐに結果を表示してくれる事、
SQLの基本的な知識があればクエリを実行できるため学習コストが低い事、
これらはBigQueryの導入を検討するにあたっての非常に魅力的なポイントです。
「大規模」と言っても具体的にどのくらいかピンと来ないと思いますので、
ホワイトペーパーから衝撃的なスケールの記述をご紹介。
クエリを並列化し、Googleのインフラ上の数万のサーバーで同時に実行することができます。
Dremelは350億行のスキャンをインデックスなしに数十秒で行います。
(Dremel Can Scan 35 Billion Rows Without an Index in Tens of Seconds)
*PublicKeyの「3億件を10秒」はWP内にある「より具体的なクエリ」の実行例に基づいていると思います。
そのクエリを実行してみたところ、「3.5~4秒」で結果が返ってきました。
○BigQueryの導入
・API Consoleにアクセス
・ServicesでBigQueryをONにする。
・Bilingを有効にする。
(反映に少し時間がかかる場合があります)
○BigQueryの3つのツール
BigQueryには
・ブラウザツール
・bqツール
・REST API
の3つのアクセス方法があります。
・ブラウザツール
BigQuery Browser Tool
ブラウザの画面からGUIで操作します。
macheで転送したログの参照のように、
必要に応じて(突発的に)クエリを実行したい場合にはブラウザツールが便利です。
また、dataset(テーブルを格納する領域)の作成や権限設定もブラウザツールから行うのが簡単です。
BigQueryは他のProductに比べて比較的GUIの機能が充実している印象で、
少し試す程度ならブラウザツールだけで一通り試すことができます。
ただし、既存のテーブルにレコードを追加する「追記アップロード」はブラウザツールからはできませんし、
直接Uploadできるファイルのサイズにも通常以上の制限がかかります。
(Cloud Storage経由なら通常の制限になるようですが、これはこれでちょっと面倒です)
参考:BigQuery Browser Tool: Quick Start - Google BigQuery — Google Developers
・bqツール
BigQueryをコマンドライから操作するためのCUIのツールです。
前述の、ブラウザからはできない「追記アップロード」もできますし、
Cloud Storageを経由しなくても、ローカルからサイズの大きいファイルを直接アップロードできます。
手動でのデータアップロード操作はbqツールを使うのが良いでしょう。
インストール方法
参考:bq Command-Line Tutorial - Google BigQuery — Google Developers
・REST API
RESTのAPIからデータのUploadやクエリの実行ができます。
以前紹介したmacheもREST APIを使ってBigQueryにデータを転送しています。
自前のシステムからデータをUploadしたいとか、
自前のシステムからBigQueryでクエリした結果を表示したいとか、
クエリの結果として構造化されたデータを取得して自動化したい、
といった場合には、REST APIを使うのが良いでしょう。
参考:Using the BigQuery API: Quick Start - Google BigQuery — Google Developers
現在弊社で定期的になっている集計作業についても、近々REST APIを使って自動化する予定です。
こちらについては自動化が終わった後で別途記事にしようかと思います。
○BigQueryの機能
・データセットの作成

データセットは「テーブルを格納するための領域」のようなものです。
最初にデータセットを作成します。
ここでは「test」とします。
・データのアップロード
適当なcsvを作成して試してみましょう。
| id | item1 | item2 | item3 | date |
|---|---|---|---|---|
| AAAA | item1A | item2A | item3A | 2012-11-21 00:00:00 |
| BBBB | item1B | item2B | item3B | 2012-11-22 00:00:00 |
| CCCC | item1C | item2C | item3C | 2012-11-23 00:00:00 |
・新規テーブルの作成
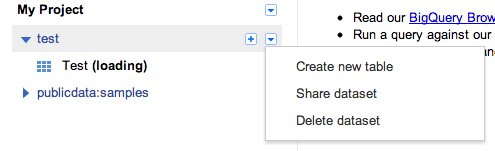
datasetから右クリックで作成ウィザードを開きます。
・Choose destination

テーブル名を入力します。ここでは「Test」とします。
・Select Data

・Source Format(※1)
csvを選択します。
・Load data from
「Choose File」を押してローカルのファイルを選択します。
前述のようにCloud Storageからのアップロードもできます。
Cloud Storageからのアップロードの方がファイルのサイズ上限は大きいです。
・Specify schema

スキーマを指定します。
スキーマは
[カラム名1:型],[カラム名2:型]・・・,[カラム名n:型]
という形式で定義します。
ここでは以下のようにします。
id:string,item1:string,item2:string,item3:string,date:string
・Advanced options
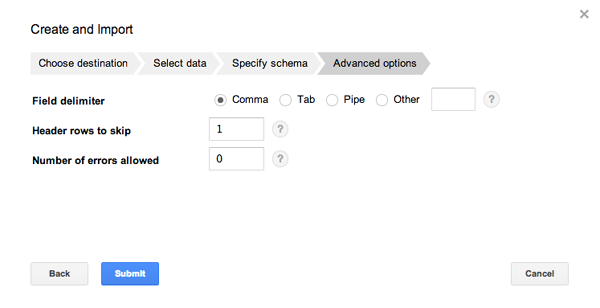
ファイル先頭のヘッダー行を無視するため、「Header rows to skip」に「1」を指定します。
この画面を見るとわかりますが、実は「CSV」だけでなく、「TSV」や他の区切り文字でも読み込むことができます。
※1
キャプチャを見てわかるとおり、jsonフォーマットを選択できます。
データの内容によってはjson形式の方が繰り返し部分のデータが減ってより多くのレコード数を一度にアップロードできそうです。
弊社ではjson形式を扱った経験が無いので、今回は省略させていただきますが、
反復データを扱えることも含め、csvよりメリットが多いように見えます。
今後マスターしていきたいところです。
また、Google Cloud Storageに保存したApp EngineのDatastoreのバックアップも選択できるようになっています。
つい最近までTTやってたはずなのに、いつのまに・・・・。
ただ、Slim3で投入したデータは
自動生成される「slim3.schemaVersion」プロパティの名前の「.」がBigQuery側に拒否られて
インポートできないのです。。(´・ω・`)
Slim3とNDB(同じような名前のプロパティがあるらしい)のユーザーは
2012/11/29 追記
@Model(schemaVersion = 1, schemaVersionName = "schemaVersion")
というように、Modelクラスに設定するアノテーションの属性で
「スキーマバージョンのプロパティ名」を指定できるそうです。
新しいModelに関してはこれを指定するのが良いと思います。
twitterで「あおうさ」さん(@bluerabbit777jp)からご指摘いただきました。ありがとうございます。m(__)m
versionにalias付けられますよ。 RT “@vierjp: Slim3で投入したEntityは「slim3.schemaVersion」プロパティの「.」がBigQuery側に拒否られてインポートできないままなのね。。泣ける(´;ω;`)#gaeja #gbqja”
— あおうささん (@bluerabbit777jp) 11月 28, 2012とはいえ既に書き込まれた既存のEntityについてはインポートできないので、
やっぱり対応して欲しいなぁ(´・ω・`)
・bqツールからアップロード
bqツールから以下のようにコマンドを実行します。
bq.py load [project_id]:test.Test test.csv id:string,item1:string,item2:string,item3:string,date:string
「project_id」は「Google APIs Console」の「Over View」に書いてある「Project ID」です。
*bqツールを使う場合、テーブルが既に存在する場合には既存のテーブルにデータを追加する形のアップロード(追記アップロード)になります。
The fully-qualified table name of the table to create, or append to if the table already exists.
・クエリの実行
画面左上の「COMPOSE QUERY」ボタンでも開けますが、
左のテーブル一覧からテーブル名を選択するのが良いでしょう。
ここでは最初から用意されている「publicdata:samples」の「wikipedia」から開きます。

テーブル名から開いて「Query Table」ボタンを押すことで
SELECT FROM [publicdata:samples.wikipedia] LIMIT 1000
のようなテンプレートが自動で生成されます。
さらに表示されているカラム情報の「カラム名」をクリックすると、
クリックしたカラム名がクエリ入力欄に自動でセットされます。
・クエリの実行履歴

画面左上の「Query History」からクエリの実行履歴を一覧で参照することができます。
クエリを選択するとそのクエリが再度入力画面に表示され、再実行することができます。
・クエリの結果をテーブルとして保存する機能

クエリの結果画面から「Save as Table」でテーブルとして保存することができます。
サブクエリとして何度も使うクエリは、この機能を使ってテーブルとして保存してしまえば、
以降のクエリの記述が簡単になります。
・クエリの結果をcsvとして保存する機能
クエリの結果画面から「Download as Table」で保存することができます。
クエリ結果をcsvでダウンロードしたい場合に便利です。
○データの編集機能はありません
「データの編集」は「インポート済みの値の変更」や「スキーマ定義の変更」を指していますが、
概要で引用した中に書いてある通り、データの編集はBigQueryのアーキテクチャが苦手とする操作です。
値を書き換えるupdate文も無ければ、スキーマ定義を変更する方法も用意されていません。
ただ、値の変更そのものはできなくても、
変更したい内容とデータ量によっては
既存テーブルをクエリで加工してその結果を別テーブルとして保存することで、
目的を達成できる可能性はあります。
これについては最後のノウハウ編でもう少し詳しく書こうと思います。
○導入編まとめ
以上がBigQueryの機能の概要説明と基本的な使い方です。
今回の導入編に続き、
○09.Google App EngineとBigQuery 実践編(2/3)
・RDBとの違いも含めたクエリの構文や関数の紹介
○10.Google App EngineとBigQuery ノウハウ編(3/3)
と記事を公開していく予定です。
当初の予想以上にボリュームが大きくなってしまいましたが、
最後までお付き合いいただけたら幸いです。
それではまた明日(`・ω・´)ノシ
 この記事をはてなブックマークに追加
この記事をはてなブックマークに追加
★宣伝★
CA BeatではTwitter、Facebookページの運営も行っております!
ブログの更新情報だけでなく、役立つスマホトピックニュースを
選りすぐって配信しております。
ブログ右サイドバーからぜひフォロー、いいね!してくださいねヽ(´▽`)ノ