Single point of failure?

現在の時代には常に運用されるべきで、高いavailabilityが必要な重要なサービスを作るように言われた場合、サーバーを1台だけで構成するバックエンド開発者は誰もいないだろう。図のように1つのサーバーと複数のクライアントの構造がある場合、サーバーが故障してクライアント全体が応答できないことをシングルポイントオブフェイルと言います。しかし、サーバーを複数用意することが常識になった現在、このようなことが本当に起こるかどうか疑問です。
単純な図で見ると、現代では絶対に起こらないように思えますが、この問題はaws、facebook、マイクロソフトなどのIT大企業でも発生したことがあります。現代では、この問題は単純にサーバーを1つにしただけで起こるものではなく、むしろシングルポイントオブフェイルを解決するための対策から発生することが最も多いです。
single point of failure はソフトウェアアーキテクチャだけでなくハードウェア、建築分野などでも使われる単語である。 最も重要な概念は、一つに依存しないように設計することだ。
例えば、データベースをいくら分けても分けたデータベースが一つのデータセンターにあり、データセンターが止まってしまうと、データベースシステム全体が止まってしまう可能性がある。 これはデータセンターがSingle point of failure になるものである。 実際、韓国ではKAKAO Talkにデータセンター障害問題が発生し、カカオトークが中断される事態が発生したことがある。

Single point of failureのすべての解決策の方向は"機能を一ヶ所に依存しない!"である。 コンピュータハードウェア設計分野では、これをFault Containment Region(エラーが出ても外部まで影響を及ぼさない領域)と呼ぶこともある。
実際の事例
Facebookの場合、シングルポイントオブフェイルが発生し、instagram、facebook、whatsapp全てが6時間停止した事件がありました。原因を分析すると、バックボーンスイッチの設定が間違っており、全てのトラフィックが1つのサーバーに集まり、障害が発生したとのことです。

SPOF(Single point of failure)は、会社が大きければ大きいほど致命的な損害を与えるため、これを発生させないためには、私が使用するSPOFの解決策の構造を知ることが非常に重要です。これから、SPOFの解決策がどのように構成されているのかを見ていきましょう
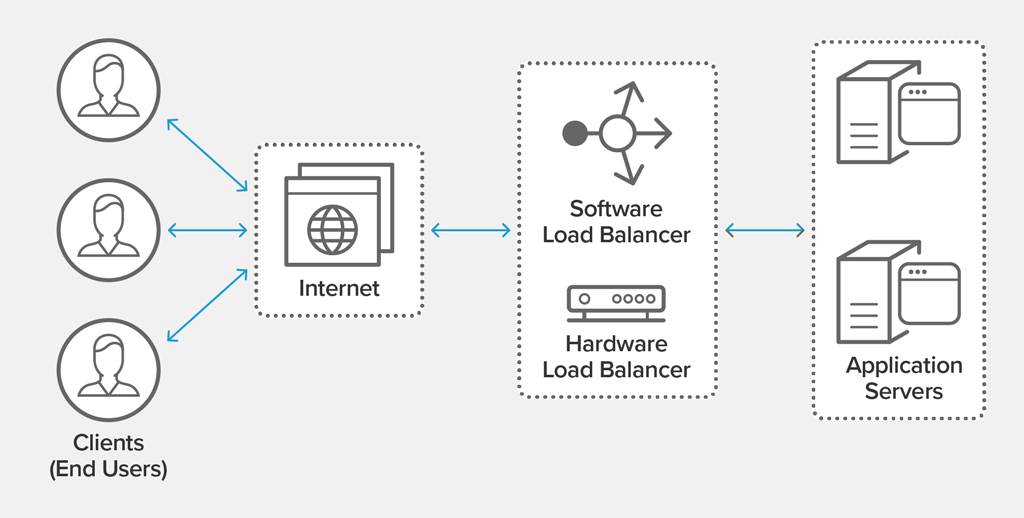
Load Blancer

モノリシックアーキテクチャを避けるために、複数のサーバーを持つアーキテクチャを使用します。しかし、単に複数のサーバーを持つだけでは、クライアントがどのサーバーに接続すべきか分からない問題を解決する必要があります。これを解決するために、ロードバランサというサーバーを設けて、複数のサーバーの負荷を分散します。

しかし、ロードバランサーが一つだけ運用されている場合、従来の単一サーバーのモノリシックアーキテクチャの弱点を補うことができないため、複数のサブロードバランサーを設置して運用する。
メインロードバランサーとサブロードバランサーを設置し、お互いのヘルスチェックを行い、ロードバランサーが正常に稼働しているかを確認する。これにより、メインロードバランサーが停止してもサービスがavailabilityを維持できるようにする。この時、クライアントがどのロードバランサーに接続するか選択する問題が発生するが、主に2つの方法がある。
クライアントがロードバランサーに接続する2つの方法
Virtual ipを基にした接続方法

各ロードバランサーをVirtual Routerに束ねて、Virtual IPを使用して接続する方法がある。各ロードバランサーはヘルスチェックを通じて有効なサーバーだけにリクエストが転送できるようにする。

メインのロードバランサーに障害が発生した場合、ヘルスチェックを通じてこれを検出し、すぐにVirtual IPのリクエストがサブロードバランサーに到達できるようにして、サービスの中断を防ぐ。
DNSを基にした接続方法

クライアントがDNSサーバーにリクエストをするとき、DNSサーバーはロードバランサーをモニタリングして、接続が有効なロードバランサーのipだけをクライアントに返す。クライアントは与えられたIPだけに接続リクエストをすればよい。この方法の注意点は、DNSからIPを受け取ると、Webの場合、ブラウザはIPアドレスをキャッシュするが、一度キャッシュされると、その後のリクエストからは別にDNSにIPを尋ねずに、直接キャッシュにあるIPを通じてサーバーに接続する。キャッシュされた後に障害が発生すると、クライアントは有効でないロードバランサーのIPにリクエストを送り、リクエストが失敗する可能性がある。ロードバランサーの実装方法
これまでに、クライアントがどのようにロードバランサーに接続するのかを見てきました。次に、ロードバランサーがどのようにサーバーに均等に負荷を分散するのかを見ていきましょう。負荷分散の方法は、2つ紹介します。
- Round Robin
- Constaint Hashing
Round Robin

ラウンドロビンは基本的に、単純に入ってきたリクエストの順番で交互にサーバーにリクエストを分けるアルゴリズムです。このアルゴリズムに基づいて、重みをつけて最適化する方法も多く使用されています。Constaintハッシング
Constaintハッシングは、基本的なハッシュの問題を補完するために作られた方法です。GoogleのロードバランサーであるMeglevでは、この技術を使用してロードバランサーを実装しています。この方法は、ロードバランサーだけでなく、Cassandra**、** Amazon DynamoDBでデータを分散保存する方法にも使用されています。
Constaint Hashing
Constaint Hashing は基本的なHash の問題を補完するために作られた方法である。 グーグルで使用するロードバランサーMeglev では、この手法を使ってロードバランサーを実装している。 この技法は、ロードバランサーだけでなく、Cassandra**、**Amazon DynamoDBでデータを分散保存する方法にも使われる方法である。
従来のハッシュアルゴリズムの問題点

従来のハッシュ方式は、特定の値が来るとノードの数 - 1で値を割り、その余りを基に値を分配するのがハッシュアルゴリズムの基本です。しかし、この方法を単純に使用すると、特定のノードにのみ値が集中する問題が発生する可能性があります。Constaintハッシングは、このような問題を防ぐためのハッシュ方法です。
Constaintハッシングの実装方法
Constaintハッシングの最も核心的なアイデアは、ノードをリング形状で管理することです。


ノードをリング形状に作成した後、リングの各区間に各サーバーの区間を時計回りに定義します。サーバーa,b,cが3つあると仮定すると、3つの色が入った図のように各サーバーの区間を割り当てることができるでしょう。
負荷超過が発生した場合

Constaintハッシングで負荷超過が発生した場合、どのように処理するかを見てみましょう。次の図のようにbのサーバーが障害を起こし、右側の図のようにCに過度のトラフィックが集中するという状況を仮定してみましょう。Constaintハッシングでは、これをVirtual nodeという概念で解決しています。Virtual nodeとは、単純にリング上にサーバーを追加することで、各ノードが過負荷になるのを防ぐ方法です。
Virtual nodeが適用されたConstaintハッシング

負荷超過が発生しそうな区間に余裕のあるサーバーの仮想ノードを追加することで、非常に簡単にサーバーに負荷が集中する現象を解決できるという点が、この方法の最大の魅力です。
Constaintハッシングの利点
- サーバーが追加または削除されたときに再配置されるキーの数が最小化されます。
- データが集中するサーバーが生まれても、単に仮想ノードを一つ追加することで変更を最小化し、問題を解決することができます。
ロードバランサーによるアーキテクチャの欠点
- 結局、複数のサーバーがネットワークを基に送信されるため、すべてのサーバーが信頼性のある時間を持つことが難しい。ナノ秒単位で考えると、意図した順序で時間の一貫性を保つことが難しい。そのため、これを解決するためには、時間の順序でリクエストの順序を判断するのではなく、イベントベースで順序を判断するタイムスタンプを使用する。
- 各コンポーネントを接続するのはステートレスネットワークなので、単純にネットワークの送信成功の有無だけをチェックできる。そのため、ネットワークが少し遅延したり、プロセスが停止して再開した場合(Java GCのsotp the word)でも、ノードが死んだとロードバランサーが判断することができる。
参考資料