IT media NEWSから大規模言語モデルの「幻覚」を軽減する32の最新テクニック バングラデシュなどの研究者らが発表
↓32のテクニックを、分かりやすく短くまとめています。
LLMの問題でもある「幻覚(ハルシネーション」を軽減するための32のテクニックがあるらしいので、、ひと通りPDFを3日に分けて読んでみた(笑)
バングラデシュのIslamic University of Technology、米サウスカロライナ大学、米スタンフォード大学、米Amazon AIに所属する研究者らが発表した論文「A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models」

PDF link:https://arxiv.org/pdf/2401.01313.pdf
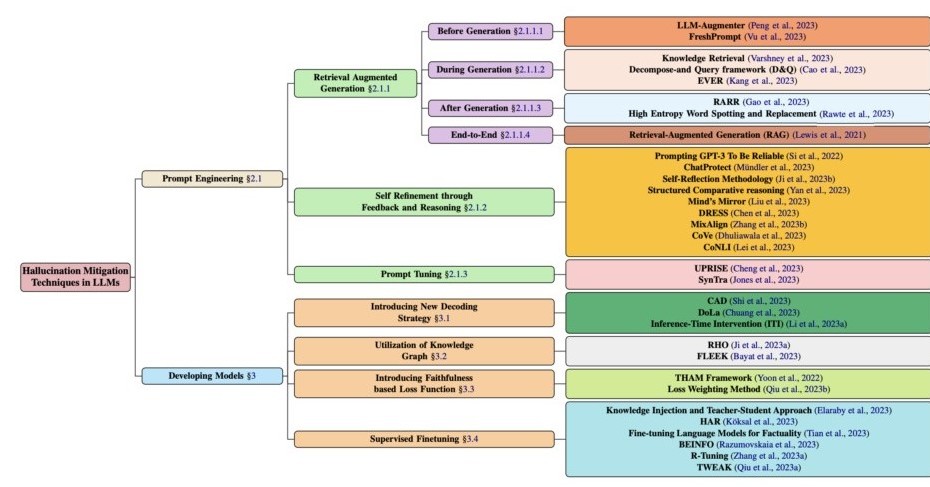
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Modelsは、LLM(大規模言語モデル)における幻覚(AIが根拠のないコンテンツを生成すること)を軽減するための32のテクニック(研究)を紹介した研究報告である。
これらの中で注目に値するのは、検索拡張生成 (RAG) (Lewis et al. 2021)、Knowl Edge Retrieval (Varshney et al., 2023)、CoNLI (Lei et al., 2023)、および CoVe (Dhuliawala et al., 2023) です。
大規模言語モデル (LLM) における幻覚には、多数の対象にまたがる事実に誤りのある情報の作成が伴います。
LLM の根本的な問題は、現実世界の主題について誤った、または捏造された詳細をもたらす傾向があることです。
GPT-4 やその他の同種の高度なモデルが不正確な、またはまったく根拠のない参照を生成する可能性があるというシナリオにつながります
(Rawte et al., 2023)。
この問題は、トレーニング段階のパターン生成技術とリアルタイムのインターネット更新がないために発生し、情報出力の不一致に寄与します (Ray、2023)。
(感想)
なんとなく、分かったようなわからんような....
んで、この「幻覚を軽減するテクニック」をGPT-3で試してみた。歴代内閣総理大臣を答えてもらったんでけど...色々違うぞ。なんで?
GPT-4は正解率が高いんだけど。よくわかりません。