今回は、最も単純な機械学習アルゴリズムである「K-nearest neighbors(KNN)」についてご紹介します。KNNは「lazy learning」とも呼ばれています。あるサンプルの分類は、その近傍のサンプル群の投票によって決定されます(すなわち、k 個の最近傍のサンプル群で最も多数なクラスをそのサンプルに割り当てます)。k は正の整数で、一般に小さい。k = 1 なら、最近傍のサンプルと同じクラスに分類されるだけです。二項分類の場合、k を奇数にすると同票数で分類できなくなる問題を避けることができます。なお、近傍を計算する時の距離は、一般にユークリッド距離が用いられます。
| 右の図で例を説明しますと、サンプル(緑の丸)は、第一のクラス(青の四角)と第二のクラス(赤の三角)のいずれかに分類されます。k = 3 なら、内側の円内にあるサンプルが近傍となるので、第二のクラスに分類される(赤の三角の方が多い)。しかし、k = 5 なら、それが逆転します。 | 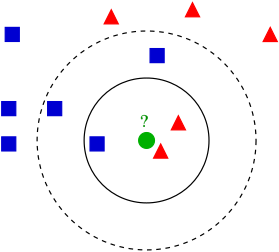 |
今回、使用するデータは、オープンソースであるUCI機械学習リポジトリから、「ウィスコンシン肺がんデータ」を使用します。569のデータからなり、第1列目はサンプルのID番号、2列目に’M’(悪性)または'B'(良性)かの分類クラスが、3列目から32列目までが変量になります。
https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data
30の変量がありますが、2次元の図にプロットする都合上、主成分分析により、2つの主成分を抽出し、Pythonを使用して肺がんが悪性か良性かを予測する機械学習モデルを作成します。主成分分析とPythonを使用した機械学習の流れは、概ね以下になります。なお、Pythonのバージョンは3.5以上を想定しています。
- プロット出力用の関数を定義する。
- データを入力する。
- 入力データを、トレーニングデータとテストデータに分ける。
- トレーニングデータを使用してデータの標準偏差と平均値を求める。
- 標準偏差と平均値を使用して、トレーニングデータとテストデータを、それぞれ標準化する。
- 適切なモデル(Classifier)を選択する。
- 主成分分析により、入力データから上位2つの主成分を抽出する。
- 主成分分析により抽出されたトレーニングデータを使用して、モデルに機械学習させる。
- テストデータを使用して、ラベルの分類を行い、モデルを評価する。
- 学習結果を図にプロットする。
では、各ステップを詳しく見ていきましょう。
①プロット出力用の関数を定義する。
まず、対話形式ではなく、Pythonのスクリプトをファイルで用意します。Pythonスクリプトの先頭に以下の2行を添付しておくことをお勧めします。
| #!/usr/bin/env python # -*- coding:utf-8 -*- |
ここでは、以下のように、「plot_decision_regions」という名前のプロット出力用の関数を定義します。第6回及び第7回で使用したものと全く同じ関数です。
|
import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap
def plot_decision_regions(X, y, classifier, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot class samples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=cmap(idx),
marker=markers[idx], label=cl)
|
②データを入力する。
今回は、冒頭でご紹介した「ウィスコンシン肺がんデータ」を、オープンソースとして提供しているサイトのURLから、pandasライブラリーを使用して以下のようにデータを抽出します。変量Xの配列(569 x 30)に、ラベル(悪性か良性か)を y(569x 1)という配列に569サンプル分のデータを格納します。sklearn.preprocessingライブラリーのLabelEncoder関数を使用して、ラベルの'M'(悪性)を数字の'1'に、'B'(良性)を数字の'0'に、それぞれ変換しています。
|
import pandas as pd df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data', header=None)
from sklearn.preprocessing import LabelEncoder X = df.loc[:, 2:].values y = df.loc[:, 1].values le = LabelEncoder() y = le.fit_transform(y) |
③入力データを、トレーニングデータとテストデータに分ける。
scikit-learning.model_selectionライブラリーのtrain_test_split関数を使用して、
変量配列Xとラベル配列yについて、トレーニングデータとテストデータに分けます。変量配列Xを、それぞれ、X_train配列, X_test配列に分割し、ラベル配列yは、y_tarin配列, y_test配列へそれぞれ分割します。test_sizeのパラメータにより、テストデータの割合を指定できます。ここでは、0.2を指定することで、テストデータの割合を全体の20%と指定しています。全569サンプルの20%(= 114サンプル)がテストデータで、残りの455サンプルがトレーニングデータとなります。random_state=1を指定することにより、ランダムにトレーニングデータとテストデータを分割することができます。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=1)
|
④トレーニングデータを使用してデータの標準偏差と平均値を求める。
sklearn.preprocessingライブラリーのStandardScaler関数を用いて、変量配列X_trainとX_testを標準化します。まず、標準化のための標準偏差と平均値は、トレーニングデータのみを使用して計算しなければなりません。fitメソッドを使用して以下のように行います。
from sklearn.preprocessing import StandardScaler sc = StandardScaler() sc.fit(X_train) |
⑤標準偏差と平均値を使用して、トレーニングデータとテストデータを、それぞれ標準化する。
次に、変量配列のトレーニングデータとテストデータを、transformメソッドを用いて、それぞれ標準化します。標準化した変量配列をそれぞれ、X_train_std, X_test_stdに格納します。
X_train_std = sc.transform(X_train) X_test_std = sc.transform(X_test) |
⑥適切なモデル(Classifier)を選択する。
様々なClassifierがscikit-learnライブラーの中でサポートされています。線形データとして分類できる場合は、Perceptron, Adaptive Linear Neuron(Adaline),Logistic regulation, Support Vector Machine(SVM),Decision tree, Random forests, K-nearest neighbors(KNN)などがあります。今回は、 K-nearest neighbors(KNN)を選択することにいたします。sklearn.neighborsライブラリーのKNeighborsClassifier関数を使用して以下のように記述します。
from sklearn.neighbors import KNeighborsClassifier kn = KNeighborsClassifier(n_neighbors=5, p=2, metric='minkowski')
|
まず、kの値をn_neighborsのパラメータで指定します(デフォルトは5)。次に、あるサンプルの近傍との距離を計算する方法をmetricパラメータで指定します。metric名と各距離の計算式との関係を表1で示します。最も一般的な距離の計算式は、ユークリッド距離です。metric='minkowski' (デフォルト)を指定し、p=2 (デフォルト)を指定した場合、表1からわかる通り、metric='euclidean'を指定した場合と同じ距離の計算式となります。ここでは、デファルトの値をそのまま、採用することとします。
表1. metricと距離の計算式
| metric名 | クラス名 | 引数 | 距離の計算式 |
| “euclidean” | EuclideanDistance |
|
sqrt(sum((x - y)^2)) |
| “manhattan” | ManhattanDistance |
|
sum(|x - y|) |
| “chebyshev” | ChebyshevDistance |
|
max(|x - y|) |
| “minkowski” | MinkowskiDistance | p | sum(|x - y|^p)^(1/p) |
| “wminkowski” | WMinkowskiDistance | p, w | sum(w * |x - y|^p)^(1/p) |
| “seuclidean” | SEuclideanDistance | V | sqrt(sum((x - y)^2 / V)) |
| “mahalanobis” | MahalanobisDistance | V or VI | sqrt((x - y)' V^-1 (x - y)) |
⑦主成分分析により、入力データから上位2つの主成分を抽出する。
sklearn.decompositionライブラリーの中でサポートされているPCA関数を用いて、トレーニングデータについて主成分分析を行い、トレーニングデータ及びテストデータについて、2つの主成分を抽出します。
|
from sklearn.decomposition import PCA pca = PCA(n_components=2) X_train_pca = pca.fit_transform(X_train_std,y_train) X_test_pca = pca.transform(X_test_std) |
⑧主成分分析により抽出されたトレーニングデータを使用して、モデルに機械学習させる。
トレーニングデータにfitメソッドを適用して、学習させます。
kn.fit(X_train_pca, y_train) |
⑨テストデータを使用して、ラベルの分類を行い、モデルを評価する。
テストデータを使用して、ラベルの分類を行い、sklearn.metricsライブラリーのaccuracy_score関数を用いて、モデルの精度を評価します。
|
from sklearn.metrics import accuracy_score y_pred = kn.predict(X_test_pca) print('Accuracy: %.3f' % accuracy_score(y_test,y_pred)) |
出力結果は、以下のように95.6%の精度と表示されます。
Accuracy: 0.956
K-nearest neighbors(KNN)にご興味のある方は、以下の本の第3章を是非、読んでみてください。
「Python Machine Learning: Unlock Deeper Insights into Machine Learning With This Vital Guide to Cutting-edge Predictive Analytics」
Sebastian Raschka (著)
出版社: Packt Publishing (2015/9/23)
言語: 英語
ISBN-10: 1783555130
ISBN-13: 978-1783555130
⑩学習結果を図にプロットする。
①で定義したplot_decision_regions関数を用いて、トレーニングデータとテストデータについて、それぞれ、抽出した第1主成分(PC1)を横軸に、第2主成分(PC2)を縦軸にした2次元領域にプロットします。
まず、トレーニングデータについてプロットします。
|
plot_decision_regions(X_train_pca, y_train, classifier=kn) plt.xlabel('PC 1') plt.ylabel('PC 2') plt.legend(loc='lower left') plt.tight_layout() plt.show() |

×印と青い領域が「悪性: 1」、■印と赤い領域が「良性:0」を表しています。
複数のサンプルに例外がありますが、トレーニングデータについて、概ね、曲線で、分類されていることがわかります。ここで、注目すべきことは、PerceptronやLogistic regulationによる機械学習モデルでは、きれいな直線によりクラスが分類されていたのに対して、KNNでは、入り組んだ曲線で分類されている点です。
次に、テストデータについてプロットします。
|
plot_decision_regions(X_test_pca, y_test, classifier=kn) plt.xlabel('PC 1') plt.ylabel('PC 2') plt.legend(loc='lower left') plt.tight_layout() plt.show() |

テストデータについても、4つのサンプルに例外がありますが、概ね、曲線で、分類されていることがわかります。
全体を通してのコードは以下のようになります。なお、本コードの稼働環境は、Python3.5以上を想定しています。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
def plot_decision_regions(X, y, classifier, resolution=0.02):
# setup marker generator and color map
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
# plot the decision surface
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution),
np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
# plot class samples
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1],
alpha=0.8, c=cmap(idx),
marker=markers[idx], label=cl)
import pandas as pd
df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/wdbc.data', header=None)
from sklearn.preprocessing import LabelEncoder
X = df.loc[:, 2:].values
y = df.loc[:, 1].values
le = LabelEncoder()
y = le.fit_transform(y)
#le.transform(['M', 'B'])
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X,y, test_size=0.2, random_state=1)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
#from sklearn.linear_model import LogisticRegression
#lr = LogisticRegression(penalty='l1',C=0.1)
from sklearn.neighbors import KNeighborsClassifier
kn = KNeighborsClassifier(n_neighbors=5,
p=2,
metric='minkowski')
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_train_pca = pca.fit_transform(X_train_std,y_train)
X_test_pca = pca.transform(X_test_std)
kn.fit(X_train_pca, y_train)
from sklearn.metrics import accuracy_score
y_pred = kn.predict(X_test_pca)
print('Accuracy: %.3f' % accuracy_score(y_test,y_pred))
plot_decision_regions(X_train_pca, y_train, classifier=kn)
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.legend(loc='lower left')
plt.tight_layout()
plt.show()
plot_decision_regions(X_test_pca, y_test, classifier=kn)
plt.xlabel('PC 1')
plt.ylabel('PC 2')
plt.legend(loc='lower left')
plt.tight_layout()
plt.show()
|