
CA Beat エンジニアリーダーのヤマサキです。
先日twitter(@vierjp)にも書きましたが、
macheというApp Engine向けツールがとても便利だったので、
情報が古くならないうちに、
「App Engineのログ」と「macheを使ったBigQueryでのログの解析」
というテーマでブログを書こうと思います。
○App Engine管理画面でのログの閲覧
App Engineでは
・httpのアクセスログ
・プログラムから出力したシステムログ
が記録され、管理画面から参照することができます。

新しい順にログを処理参照するだけでなく、
指定した時刻以前のログを検索したり、項目毎に条件を指定して検索ができます。
・UserAgentで検索
filterを「Labels」で
useragent:.*Chrome.*
・URLのPathで検索
filterを「Labels」で
path:/api/v1_0/get.+
・UserAgentとPathでand検索
filterを「Labels」で
useragent:.*Chrome.* path:/api/v1_0/get.+
・スピンアップしたリクエストだけ取得
filterを「Regex」で「This request caused a new process to be started for your application」
テスト中に最近のログを見たいだけならApp Engine管理画面でも対象のログを探すことができますが、
古いログを参照できないことがあるので本番運用中には辛い場合があります。
その点BigQueryにログを転送した場合には古いログもちゃんと見ることができますし、
集計関数を使って統計情報を取得することもできます。
○BigQueryって何?
BigQueryは大量のデータに対して高速にクエリを実行するために最適化されたGoogleのサービスです。
Google BigQuery — Google Developers
csv形式(またはjson形式)のデータをアップロードしてテーブルとして保存し、
そのテーブルに対してSQLによく似たクエリを実行することができる、
「列指向データベース」に分類されるデータベースです。
・RDBとの違い
・RDBと違いインデックスを設定する必要はありません
・データをアップロード後に編集することはできません。あくまで「データ解析用」です
・RESTのAPI経由で実行できます
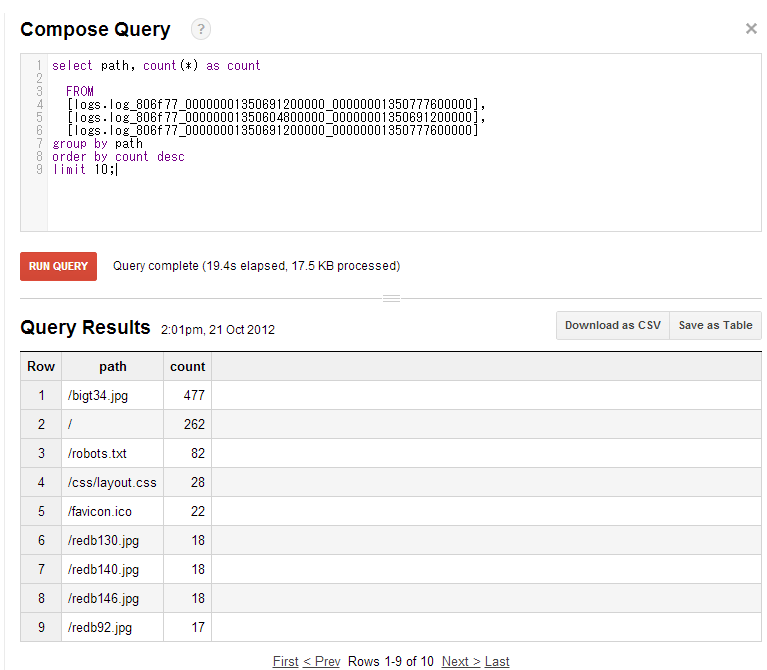
○実行できるクエリの例
・Pathをリクエスト数の多い順にソートして表示
select path, count(*) as count
from [テーブル名]
group by path
order by count desc
limit 10;
・スピンアップした場合のリクエスト処理時間の平均値(ミリ秒)を取得
select ROUND(AVG(latencyUsec) / 1000) as latencyUsec
from [テーブル名]
where isLoadingRequest=true
and path='/';
スピンアップを含むリクエスト時間の平均なので、できるだけ何も処理をしないpathを指定しましょう。
・処理コスト(金額)の高いリクエストを取得
select path, AVG(cost) as cost
from [テーブル名]
where isLoadingRequest=false
group by path
order by cost desc
limit 10;
・リクエスト数も含めてアプリで一番コストのかかっている処理を取得
select path,cost,cnt, (cost * cnt) as totalCost
from
(
select path, AVG(cost) as cost, COUNT(*) as cnt
from [テーブル名]
where loadingRequest=false
group by path
)
order by totalCost desc
limit 10;
この「コスト」がどんな値なのかが謎なのであまり期待しない方がいいかも。
データの参照処理でMemechae使った場合と使っていない場合で同じ数値だったので
DatastoreのI/Oを見てなさそうです。CPUだけ?
・エラーログを含むリクエストを取得する
SELECT FORMAT_UTC_USEC(timestamp + 32400000000) as timestamp, path, maxLogLevel, appLog
FROM [テーブル名]
where maxLogLevel>=4
order by timestamp desc
limit 100;
「FORMAT_UTC_USEC(timestamp + 32400000000) as timestamp」は
リクエスト時刻を日本時間(UTC + 9時間)に変換しています。
クエリ結果をBigQueryのクエリ画面で
「Download as CSV」を押してcsv形式としてダウンロードすると、
Excelで開いて見ることもできます。
※「maxLogLevel」「appLog」はデフォルトのmacheでは取得していません。
コードに手を入れて追加しました。
・アプリケーションから出力したログの内容から検索する
SELECT FORMAT_UTC_USEC(timestamp + 32400000000) as timestamp, httpStatus, method, finished, host, path, resource, ip, userAgent, referrer, instanceKey, responseSize, loadingRequest, pendingTimeUsec, latencyUsec, maxLogLevel, appLog
FROM [テーブル名]
WHERE timestamp>=PARSE_UTC_USEC('2012-10-26 15:00:00')
and path='/api/hoge'
and REGEXP_MATCH(appLog, 'something')
order by timestamp desc;
appLogに指定した文字列を含むログを取得しているだけですが、
AppEngine管理画面の検索よりも精度が高いように思います。
AppEngine管理画面の検索は、
特に古いログについて、保存期間的に存在するはずのログでも
期待通りに結果を取得できないこと、ありますよね。
その点このクエリはかなり便利です。
リクエストパラメーターやデータを特定できるようなログをまるごとログに出力しておけば
問題発生時の調査もしやすいです。超オススメ。
・複数の日付のログをまたいでクエリする
SELECT FORMAT_UTC_USEC(timestamp + 32400000000) as timestamp, path
FROM
[テーブル名1],
[テーブル名2],
[テーブル名3],
order by timestamp desc
BigQueryには構文としての「UNION」はありませんが、上記の記法でUNIONできます。
参考:BigQuery「クエリ リファレンス」
○ログ保存にかかるコストはどちらが安いか
・BigQuery
$0.12 GByte/month
Pricing - Google BigQuery — Google Developers
・App Engine Logs Storage
$0.24 GByte/month ($0.008 GByte/day x 30)
※管理画面 Billing Historyで確認
単純にストレージのコスト表の比較で言えば、BigQueryの方が安い(半額)です。
ただ、それぞれでデータの保存形式が違えば同じログを記録するのに必要とする容量も違うでしょうから、
どちらが安いかは調べないとはっきりとは言えないところです。
また、BigQueryはクエリの実行にも課金されます。
月に一定量まではクエリの実行が無料なので、
ログ解析に限って言えば、よほど大量のログに対してクエリを実行しない限り、
こちらは無料で足りるのではないかと思います。
データをコピーするためのApp Engine上のプログラムを処理するCPUも無料では無いですし、
App Engine上でのログ参照にもコストがかかります。(Billing Historyの「Logs Read Bandwidth」)
安くなることまでは期待しない方がいいかもしれません。
ちなみに、Priceの「How am I charged?」に書いてありますが
BigQueryのクエリでは不要な列を取得しない方がコストが安いようです。
○取得できるログの項目
後で説明するmacheは内部的に「LogService」を使っており、
取得できるログの項目は「RequestLogs」から取得できる項目に依存します。
RequestLogs (Google App Engine Java API)
requestId リクエストのユニークなID
timestamp リクエスト時刻
versionId アプリのバージョンID
httpStatus HTTPのステータスコード(200,404等)
method HTTPのmethod(GET,POST等)
httpVersion HTTPのバージョン(HTTP/1.1等)
loadingRequest スピンアップしたかどうか
finished リクエストが終了しているかどうか
host アクセス先ホスト名(独自ドメインにアクセスした場合独自ドメイン)
path アクセス先Path(クエリを含まない)
resource アクセス先Path(クエリを含む)
nickname Googleアカウントで認証を要求しているPathで、かつ認証している場合にログインユーザー名が表示される
ip クライアントのIPアドレス
userAgent クライアントが送信するUserAgnetの文字列
referrer リファラー(クライアントが送信する遷移元)
instanceKey インスタンスのユニークID
apiMcycles リクエストを処理するのにAPI呼び出しに費やしたマシン・サイクル数(非推奨・正確な値では無いらしい)
cost リクエストを処理するのに費やした推定コスト($)
responseSize レスポンスデータのサイズ(byte)
mcycles リクエストを処理するのに費やしたマシン・サイクル数
pendingTimeUsec 保留中の要求キューで費やされた時間(マイクロ秒、スピンアップ時間は含まれないっぽい)
latencyUsec リクエスト処理時間(スピンアップ時間を含む)
maxLogLevel 独自追加:アプリケーションから出力したログのうち一番重要度が高いもの。
「DEBUG=1,INFO=2,WARN=3,ERROR=4,fatal=5」(App Engineではlog4j等のTRACEレベルはDEBUGとして扱われる)
appLog 独自追加:アプリケーションから出力したログの時刻とログレベル、ログ文字列
○App EngineのログをBigQueryにコピーするためのmacheとその仕組み
Pythonで書かれたlog2bqというツールもありますが、
今回はJavaで書かれたmacheを使います。(我々Javaエンジニアですし)
App EngineのログをBigQueryでクエリするためにはログデータをBigQueryにコピーする必要があります。
このコピーの流れは以下のようになります。
・Google App Engine上でLogServiceを使ってログを取得
・取得したログをGoogle Cloud Storageに書き出す
・Google Cloud StorageからBigQueryにアップロード
この自分で作ると大変そうなコピーの処理をしてくれるのがmacheです。
・Google Cloud Storageの準備
・gsutilをダウンロード
・「gsutil config」で初期設定
・「gsutil mb gs://{bucket名}」でbubketを作成する
・「gsutil getacl gs://{bucket名} > bucket.acl」で「権限情報」をダウンロード
・権限情報に以下を追加
<Entry>
<Scope type="UserByEmail">
<EmailAddress>
{AppEngine上のアプリケーションID}@appspot.gserviceaccount.com
</EmailAddress>
</Scope>
<Permission>
WRITE
</Permission>
</Entry>
・「gsutil setacl bucket.acl gs://{bucket名}」で変更を反映。
権限設定をするためにCUIのツールが必要なところとか、
使い勝手の点ではまだまだAmazon S3に水をあけられていると言わざるをえないところ。。
自動化前提ならCUIのツールもいいけど、権限設定は自動化のニーズも少ないと思います。
しかもこの権限設定はバックアップの時にも行う必要があるので
アプリを複数管理していると使用頻度が高いのです。
権限設定だけでもWebの画面からできるといいんですけど。
「Google Cloud Strage」内のファイルを見たい場合はonline browserで確認できます。
・BigQueryの権限設定
・Google APIs consoleを開く
・Teamタブを開く
・「{AppEngine上のアプリケーションID}@appspot.gserviceaccount.com」を入力し、owner権限を付与。
・BigQueryのデータセットを作成する
・BigQuery web interface に行く
・「Create new dataset」でデータセット名を入力して作成する。
○1.macheの使い方
・gitからmacheのファイルを取得
・javaファイルをログを取得したいアプリプロジェクトのsrcフォルダに、全てのjarを「WEB-INF/lib」以下にそれぞれコピー。
(mache本体はmache-0.0.2.jarのみでOK)
・web.xmlをドキュメントからコピペ(javaファイルのパッケージ名変えてなければそのままコピペ)
・cron定義の追加
<cron>
<url>/logging/logExportCron?bucketName={bucket名}&bigqueryProjectId={Google APIのプロジェクトID}&bigqueryDatasetId={BigQueryのデータセットID}</url>
<description>Export logs to BigQuery</description>
<schedule>every 2 minutes</schedule>
</cron>
※「Google APIのプロジェクトID」はGoogle APIs Consoleに書いてある「Project ID」の文字列です。
この方法は簡単なんですが、
macheのmavenリポジトリが用意されていない点と、
macheだけで使うjarをメインのアプリに大量に配置するのが嫌で、少しいじってみました。
○2.筆者がカスタマイズしたmache-web
・ログの取得項目を追加
・macheを単独のWebアプリとしてbackendsに配置
・「ログを取得したいアプリケーション」から
「自身のアプリケーションのバージョン名」を指定してbackendsのmacheを起動するようcron定義。
・cronから起動された「backendsのmache」は「指定されたバージョン名のログ」を取得してBigQueryに転送する
これによって、
・cron定義以外にメインのアプリを変更する必要が無い。
・macheバージョンアップ時にそれぞれのアプリのmacheのjarを入れ替える必要がなく、
「mache-web」を変更するだけで良い。
「mache-web」は単独のWebプロジェクトなのでデプロイ先を変えるだけでどのアプリにも配置できる。
となります。
mache-webはbackendsではなくFrontendに置いても動作します。
(※ 2012/11/13 訂正 今日試したら10個まで配置できました。5つは勘違いだったようです)
そのまま使うもよし、カスタマイズの参考にするもよし、コード置いておきます。(無保証です)
[mache-web」をダウンロード
使い方・設定方法は「README.txt」を参照してください。
※SDK1.7.3で環境を作っているので、場合によってはコンパイルエラーになると思います。
その場合はSDKの設定を変更してください。
比較的最近のApp Engine SDKが必要ですので、
最近更新していない人はこの機会に入れておきましょう。
ただ、この方式は必ずしもオススメはしません。
backendsのインスタンスが少なくとも一つ一日中動きっぱなしになり、
無料枠に収まらずCPUのみで毎日$1.20かかるので無料運用を狙う場合には向きません。
また、「デプロイ時にデプロイ先に応じて自動的に設定情報を書き換える仕組み」を用意できていない場合は
メインのアプリのデプロイ時にcronで指定するバージョン番号をいちいち書き換えるのも面倒です。
でも、今回の記事を見てちょっと試してみようという方には
mache-webをbackendsにデプロイして
自分のアプリのcron.xmlだけ編集すれば試せるので楽かと思います。
運営している複数のアプリでmacheを使いたい場合にも良いかと。
ケースバイケースですが。
「maven使ったことないんだけど(´・ω・`)」という人は
Eclipseプラグインから普通にFrontendにデプロイしても動くんじゃないかな、、たぶん。
すでにmacheを使っていて、記録するログの項目だけ追加したい人、
「動かねぇぞゴルァ(゚Д゚)」という人は
「jp.co.cabeat.mache.analysis」パッケージ内のファイルをコピーして
cronのパラメーターで
「bigqueryFieldExporterSet=jp.co.cabeat.mache.analysis.CustomizedFieldExporterSet」
を指定すればOKです。(無保証です)
○BigQueryについて
弊社では最近データの集計にもよくBigQueryを使っています。
(JOINするテーブルのサイズ制限と結果データのサイズに制限があるのがこの先の課題・・・かな?)
今回のログの件に限らず、Datastoreのデータを集計したい場合にもBigQueryはオススメです。
特にApp EngineではDatastoreに対するクエリの制限が色々あるためデータ集計や分析がしづらいです。
また、BigQueryで集計をする前提であれば、
アプリの挙動には必要のない「集計のために用意したインデックス」が不要になるため
Datastoreの書き込みコストを減らすこともできます。
現在、App EngineからBigQueryにDatastoreのデータをコピーするためには
「DatastoreのデータをCSVとしてダンプ」→「BigQueryにアップロード」という手順が必要です。
これは比較的簡単に自動化できるのですが、データ転送料とDatastoreの参照コストがかかります。
しかし、ちょうど今
「公式のApp EngineからBigQueryにDatastoreのデータを直接コピーする機能」
のクローズドテスト中です。
Google App Engine Blog: New Google BigQuery Launch includes Datastore Import for Trusted Testers
これは「既存のバックアップ機能でGoogle Cloud Storageに出力したバックアップデータ」を
BigQueryにアップロードする機能です。(※1)
運用環境ではBigQueryとは関係なくDatastoreのデータを定期的にバックアップしているでしょうから、
そのデータをそのままBigQueryに持っていって集計もできちゃう、というわけです。
この機能が正式リリースされた後は、
それほどコストをかけずにDatastoreのデータに対して集計クエリを実行できるようになるでしょう。
これまでApp EngineのDatastoreはそのクエリの制限から、データを集計するのが大変でした。
集計のためだけに使うインデックスを用意すればその分Datastoreへの書き込みコストが増えますし、
多くの場合には集計用のプログラムを書く必要がありました。
BigQueryとの連携によってこの点が改善されれば、
App Engineにとっての大きな進歩と言って良いでしょう。
ちなみに、macheにはDatastoreのデータをコピーするために使うっぽいプログラムも入っています。
(「com.streak.datastore.analysis」内)
急ぐ場合はこれを試してみるのもいいかもしれません。
バックアップデータからコピーした方が総合的に安くつくと思うので筆者はそれ待ちですが。
DatastoreのデータをBigQueryにコピーする方法についても、正式リリース後にブログを書こうと思います。
※1:Google App Engine Blogからははっきり読み取れませんが、
BigQueryのサイトには
「direct ingestion of App Engine Datastore backup data dumps」
と書いてあります。
BigQuery Data Ingestion Best Practices and Cookbook - Google BigQuery — Google Developers
○次回予告
次回はApp Engineで独自ドメインでSSLを使う方法です。
自己証明書ではなく、認証機関が発行するテスト用SSL証明書でクロスルート証明書を使った実用的な解説です。
「公式の英語ドキュメント見りゃわかるよ」なんて言わせないぞ(`・ω・´)
★宣伝★
CA BeatではTwitter、Facebookページの運営も行っております!
ブログの更新情報だけでなく、役立つスマホトピックニュースを
選りすぐって配信中♪
ブログ右サイドバーからぜひフォロー、いいね!してくださいねヽ(´▽`)ノ
 この記事をはてなブックマークに追加
この記事をはてなブックマークに追加